作为一个网络技术人员,机器学习是一种很有必要学习的技术,在这个数据爆炸的时代更是如此。
python做数据分析,最常用以下几个库
numpy pandas matplotlib
一、Numpy库
为了方便科学计算,Numpy库定义了一些属性和方法以便于对一维数据,二位数据和高维数据的处理。为了满足科学计算的需求,Numpy定义了一个多维数组对象——ndarray。Ndarray由实际数据和描述这些数据的元数据(如数据维度、数据类型)构成,ndarray一般要求所有元素类型相同。
(1) Ndarray中的属性
| 属性 |
说明 |
| .dim |
秩,即轴的数量或数据的维度 |
| .shape |
ndarray对象的尺度,对应于矩阵的n行m列 |
| .size |
ndarray对象中元素的个数,即n*m |
| .dtype |
ndarray对象中元素的类型 |
| .itemsize |
ndarray对象中每个元素的大小 |
ndarray中数据类型包括:bool,intc,intp,int8,int16,int32,int64,uint8,uint16,uint32,uint64,float6,float32,float64,complex64,complex128。
(2) Ndarray对象的创建
Ndarray对象可以由python中的列表和元组对象创建、使用ndarray中的函数进行创建、从字节流中创建和从文件中读取特定格式进行创建。
l 使用python中的列表和元组对象进行创建
基本格式为 X = np.array(list/tuple,dtype = 数据类型)dtype参数如果没有指定,那么ndaary会根据数据形式自动定义数据类型
l 使用ndarray中的创建函数
| 函数 |
说明 |
| np.arange(n) |
类似range()函数,返回ndarray类型,元素从0到n‐1 |
| np.ones(shape) |
根据shape生成一个全1数组,shape是元组类型 |
| np.zeros(shape) |
根据shape生成一个全0数组,shape是元组类型 |
| np.full(shape,val) |
根据shape生成一个数组,每个元素值都是val |
| np.eye(n) |
创建一个正方的n*n单位矩阵,对角线为1,其余为0 |
| np.ones_like(a) |
根据数组a的形状生成一个全1数组 |
| np.zeros_like(a) |
根据数组a的形状生成一个全0数组 |
| np.full_like(a,val) |
根据数组a的形状生成一个数组,每个元素值都是val |
(3) Ndarray对象的变换
Ndarray对象的变换是指对ndarray对象的维度和元素类型进行变换。
| 方法 |
说明 |
| .reshape(shape) |
不改变数组元素,返回一个shape形状的数组,原数组不变 |
| .resize(shape) |
与.reshape()功能一致,但修改原数组 |
| .swapaxes(ax1,ax2) |
将数组n个维度中两个维度进行调换 |
| .flatten() |
对数组进行降维,返回折叠后的一维数组,原数组不变 |
| .astype(new_type) |
创建新的数组(原始数据的一个拷贝),但是数据类型进行改变 |
| .tolist() |
ndarray数组向列表的变化 |
(4) 数组的索引和切片

多维数组的索引和切片中不同维度的索引序号间要加上逗号进行分隔。

(5) Ndarray数组的运算
| 函数 |
说明 |
| np.abs(x) np.fabs(x) |
计算数组各元素的绝对值 |
| np.sqrt(x) |
计算数组各元素的平方根 |
| np.square(x) |
计算数组各元素的平方 |
| np.log(x) np.log10(x) np.log2(x) |
计算数组各元素的自然对数、10底对数和2底对数 |
| np.rint(x) |
计算数组各元素的四舍五入值 |
| np.modf(x) |
将数组各元素的小数和整数部分以两个独立数组形式返回 |
| np.exp(x) |
计算数组各元素的指数值 |
| np.sign(x) |
计算数组各元素的符号值,1(+), 0, ‐1(‐) |
| np.cos(x) np.cosh(x) np.sin(x) np.sinh(x) np.tan(x) np.tanh(x) |
计算数组各元素的普通型和双曲型三角函数 |
| + ‐ * / ** |
两个数组各元素进行对应运算 |
| np.maximum(x,y) np.fmax() np.minimum(x,y) np.fmin() |
元素级的最大值/最小值计算 |
| np.mod(x,y) |
元素级的模运算 |
| np.copysign(x,y) |
将数组y中各元素值的符号赋值给数组x对应元素 |
(6) 数组的读取和写入
| 函数 |
说明 |
| a.tofile(frame, sep='', format='%s') |
存取函数,frame是写入的文件名,seq是指定的分隔符,format是写入的格式 |
| np.fromfile(frame,dtype=float,count=‐1, sep='') |
读取函数,frame是读取的文件名,count代表读取的元素个数,-1表示读取整个文件。注意该方法需要知道数组的维度信息 |
| np.save(fname, array) |
Frame是文件名,以npy为拓展名,array是数组变量 |
| np.load(frame) |
(7) 随机数函数
| 函数 |
说明 |
| rand(d0,d1,..,dn) |
根据d0‐dn(维度信息)创建随机数数组,浮点数,[0,1),均匀分布 |
| randn(d0,d1,..,dn) |
根据d0‐dn创建随机数数组,标准正态分布 |
| randint(low,high,shape) |
根据shape创建随机整数或整数数组,范围是[low, high) |
| seed(s) |
随机数种子,s是给定的种子值 |
| shuffle(a) |
根据数组a的第1轴进行随排列,改变数组x |
| permutation(a) |
根据数组a的第1轴产生一个新的乱序数组,不改变数组x |
| choice(a[,size,replace,p]) |
从一维数组a中以概率p抽取元素,形成size形状新数组 replace表示是否可以重用元素,默认为False |
| uniform(low,high,size) |
产生具有均匀分布的数组,low起始值,high结束值,size形状 |
| normal(loc,scale,size) |
产生具有正态分布的数组,loc均值,scale标准差,size形状 |
| poisson(lam,size) |
产生具有泊松分布的数组,lam随机事件发生率,size形状 |
(8) 统计函数
| 函数 |
说明 |
| sum(a, axis=None) |
根据给定轴axis计算数组a相关元素之和,axis整数或元组 |
| mean(a, axis=None) |
根据给定轴axis计算数组a相关元素的期望,axis整数或元组 |
| average(a,axis=None,weights=None) |
根据给定轴axis计算数组a相关元素的加权平均值 |
| std(a, axis=None) |
根据给定轴axis计算数组a相关元素的标准差 |
| var(a, axis=None) |
根据给定轴axis计算数组a相关元素的方差 |
| min(a) max(a) |
计算数组a中元素的最小值、最大值 |
| argmin(a) argmax(a) |
计算数组a中元素最小值、最大值的降一维后下标 |
| unravel_index(index, shape) |
根据shape将一维下标index转换成多维下标 |
| ptp(a) |
计算数组a中元素最大值与最小值的差 |
| median(a) |
计算数组a中元素的中位数(中值) |
| np.gradient(f) |
计算数组f中元素的梯度,当f为多维时,返回每个维度梯度 |
二、Matplotlib库
Matplotlib库由各种可视化类构成,内部结构复杂,受Matlab启发matplotlib.pyplot是绘制各类可视化图形的命令子库,相当于快捷方式。
(1) pyplot.plot函数
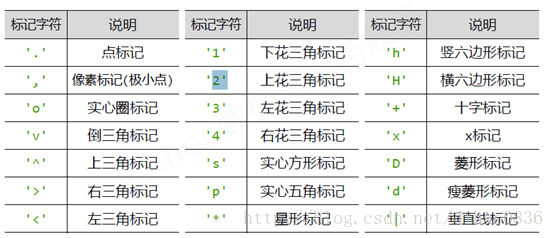
函数基本格式为plt.plot(x, y, format_string, **kwargs)。x为x轴的数据,y为y周的数据,format_string是控制曲线的格式字符串,包括颜色字符,风格字符和标记字符。
| 颜色字符 |
说明 |
颜色字符 |
说明 |
| ‘b’ |
蓝色 |
‘m’ |
洋红色 |
| ‘g’ |
绿色 |
‘y’ |
黄色 |
| ‘r’ |
和红色 |
‘k’ |
黑色 |
| ‘c’ |
青绿色 |
‘w’ |
白色 |
| ‘#008000’ |
RGB某种颜色 |
‘0.8’ |
灰度值字符串 |
| 风格字符 |
说明 |
| ‘-’ |
实线 |
| ‘--’ |
破折线 |
| ‘-.’ |
点划线 |
| ‘:’ |
虚线 |
| '' ' ' |
无线条 |
pyplot并不默认支持中文显示,需要rcParams修改字体实现。

rcParams中的参数:

除了上述方法外,还可以在有中文输出的地方,增加一个属性:fontproperties。

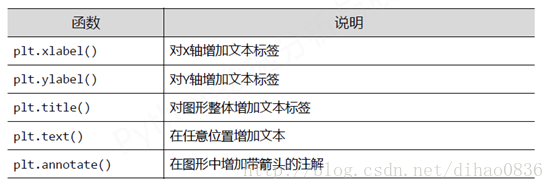
文本显示函数:
(2) pyplot的子绘图区域
可以使用subplotgrid函数,函数的一般形式为:
plt.subplot2grid(GridSpec, CurSpec, colspan=1,rowspan=1)
colspan是指列上的延伸范围,同理rowspan是行方向的延伸范围。

此外还可以使用GridSpec类。

图只是展示数据的一种方式,图像的绘制要结合数据特征来看,而且也比较简单,有了数据知道该如何展示后去matplotlib官网上找相应的代码就好了。
(3) 图像的数组展示和处理
图像一般使用RGB色彩模式,即每个像素点的颜色由红(R)、绿(G)、蓝(B)组成,三个颜色通道的变化和叠加得到各种颜色,每个颜色通道的变化范围为0-255。图像是一个由像素组成的二维矩阵,每个元素是一个RGB值,即shape为(lenth,width,3)。
PIL库是一个具有强大图像处理能力的第三方库,其中定义了Image类,可以使图像变成数组,并对其进行处理,最后再把数组返回成图像。
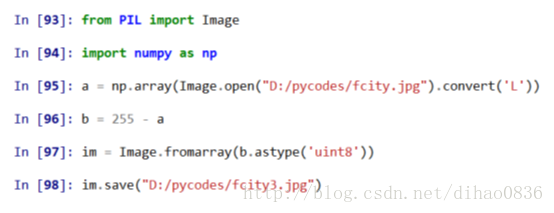
convert(‘L’)表示把图像转化成灰度值。
三、Pandas库
Pandas是Python第三方库,提供高性能易用数据类型和分析工具,其定义了两个数据类型:Series,DataFrame。不同于numpy库中定义的ndarray类型,pandas库中的数据类型关注数据的应用,即数据和索引之间的关系。
(1) Series类型
Series类型由一组数据及与之相关的数据索引组成,只用于表达一维数组。Series类型可以由python列表和字典、ndarray和其他函数创建。
创建的一般表达为,pd.Series(array,index=)

Series类型的操作类似ndarray类型:索引方法相同,采用[]、NumPy中运算和操作可用于Series类型、可以通过自定义索引的列表进行切片以及可以通过自动索引进行切片,如果存在自定义索引,则一同被切片。
Series类型的操作类似Python字典类型:通过自定义索引访问、保留字in操作以及使用.get()方法。
(2) DataFrame类型
DataFrame类型由共用相同索引的一组列组成。DataFrame是一个表格型的数据类型,每列值类型可以不同DataFrame既有行索引、也有列索引DataFrame常用于表达二维数据,但可以表达多维数据。操作和床架与Series类型相似。
(3) 索引类型的函数
| 方法 |
说明 |
| .reindex(index=None,columns=None..) |
改变或重排Series和DataFrame索引 |
| .append(idx) |
连接另一个Index对象,产生新的Index对象 |
| .diff(idx) |
计算差集,产生新的Index对象 |
| .intersection(idx) |
计算交集 |
| .union(idx) |
计算并集 |
| .delete(loc) |
删除loc位置处的元素 |
| .insert(loc,e) |
在loc位置增加一个元素e |
| .drop() |
删除Series和DataFrame指定行或列索引 |

(4) 数据类型运算
算术运算根据行列索引,补齐后运算,运算默认产生浮点数,补齐时缺项填充NaN (空值)。二维和一维、一维和零维间为广播运算。
| 方法 |
说明 |
| .add(d, **argws) |
类型间加法运算,可选参数 |
| .sub(d, **argws) |
类型间减法运算,可选参数 |
| .mul(d, **argws) |
类型间乘法运算,可选参数 |
| .div(d, **argws) |
类型间除法运算,可选参数 |
上述函数的axis参数默认为0,即在行方向上进行运算,改为1则在列的方向上进行运算。
(5) 统计运算
| 方法 |
说明 |
| .sort_values(by,axis=0,ascending=True) |
在指定轴上根据数值进行排序,默认升序 |
| .sum() |
计算数据的总和,按0轴计算,下同 |
| .count() |
非NaN值的数量 |
| .mean() .median() |
计算数据的算术平均值、算术中位数 |
| .var() .std() |
计算数据的方差、标准差 |
| .min() .max() |
计算数据的最小值、最大值 |
| .argmin() .argmax() |
计算数据最大值、最小值所在位置的索引位置(自动索引) |
| .idxmin() .idxmax() |
计算数据最大值、最小值所在位置的索引(自定义索引) |
| .describe() |
针对0轴(各列)的统计汇总 |
| .rolling(w).sum() |
依次计算相邻w个元素的和 |
| .cov() |
计算协方差矩阵 |
| .corr() |
计算相关系数矩阵, Pearson、Spearman、Kendall等系数 |