数据分析绝对绕不过的三个包是numpy、scipy和pandas。numpy是Python的数值计算扩展,专门用来处理矩阵,它的运算效率比列表更高效。scipy是基于numpy的科学计算包,包括统计、线性代数等工具。pandas是基于numpy的数据分析工具,能更方便的操作大型数据集。
这次用jupyter notebook来演示,不会使用jupyter notebook的童鞋可以看这条链接:https://blog.csdn.net/qq_22499377/article/details/80921756
pandas
pandas有两个主要的数据结构,Series和DataFrame。
Series
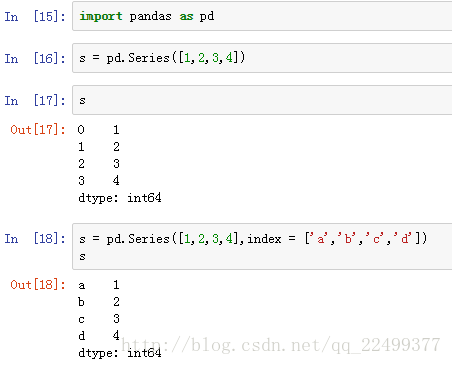
Series类似于一维数组,和numpy的array接近,由一组数据和数据标签组成。数据标签有索引的作用。
加载pandas包,通过Series函数生成一个对象。我们很明显地看到,在jupyter上它的样式不同于array,
它是竖着的。右边是我们输入的一组数据,左边是数据的索引,即标签。数据标签是pandas区分于numpy的重要特征。
索引不一定是从0开始,它可以被重新定义。索引的概念有点像SQL的主键,我们能够轻松的通过索引选取一个数组或者一组数据。
DataFrame
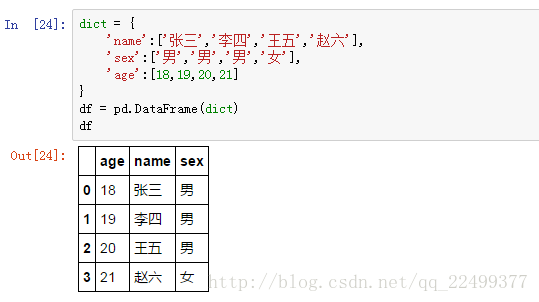
Series是一维的数据结构,DataFrame是一个表格型的数据结构,它含有不同的列,每列都是不同的数据类型。我们可以把DataFrame看作Series组成的字典,
它既有行索引也有列索引。想象得更明白一点,它类似一张excel表格或者SQL,只是功能更强大。
构建DataFrame的方法有很多,最常用的是传入一个字典。
DataFrame中可以通过info函数直接查看数据类型和统计。

列名后面是列的非空值统计量,以及数据类型,最后一行是DataFrame占用的内存大小,对于pandas来说,千万行几百兆的数据也是不再话下的。
DataFrame在数据选取上面非常强大。可以用列名选取,可以用切片的方式选取,可以用逻辑表达式选取,可以用query函数以类SQL语言执行查询。
示例:用列名选取

示例:用切片的方式选取

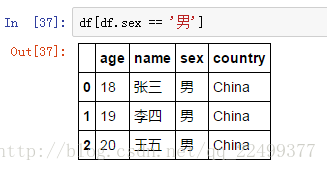
示例:用逻辑表达式选取
示例:用query函数以类SQL语言选取

DataFrame可以直接在列上进行运算,当DataFrame和DataFrame之间运算时,按索引进行加减乘除。
DataFrame还有两个常用函数,又特别容易搞混的是,iloc和loc。它们都是通过索引选取行,iloc是通过所在行的数字为索引,loc是所在行的标签为索引,
简单讲,iloc是第几行,loc是标签。当索引没有标签时,loc和iloc等价。两者支持冒号的范围选择。

上文提到的过的ix,则是两者的混合,即可以行号,也可以行索引。