pandas 是什么
- pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析。它提供了大量高级的数据结构和对数据处理的方法。
pandas 有两个主要的数据结构:Series 和 DataFrame。
数据结构
Pandas 中的数据类型
- Pandas 基于两种数据类型,series 和 dataframe。
series 是一种一维的数据类型,其中的每个元素都有各自的标签,可以把它当作一个由带标签的元素组成的numpy数组。标签(index)可以是数字或者字符。 - dataframe 是一个二维的、表格型的数据结构。Pandas 的 dataframe 可以储存许多不同类型的数据,并且每个轴都有标签。
- Pandas 基于两种数据类型,series 和 dataframe。
Series与DataFrame
Series
是一个一维数组对象 ,类似于 NumPy 的一维 array。它除了包含一组数据还包含一组索引,所以可以把它理解为一组带索引的数组。
from pandas import Series, DataFrame #首先引入需要使用的模块
import pandas as pd
import numpy as np
s = Series([4, 7, -5, 3]) #可以用list构建
print(s)
输出结果:

s2 = Series((4, 7, -5, 3)) #可以用tuple构建
print(s2)输出结果:

s.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
#重新设置index
print(s)

- index值可以相同
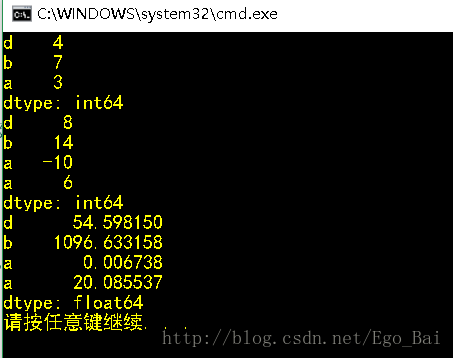
s2 = Series([4, 7, -5, 3], index=['d', 'b', 'a', 'a']) #index的值可以相同
print(s2)
print(s2['a'])输出结果:

- 使用s2[index]提取出series内的对应标签的行
- s2[s2>0]筛选出值大于0的行并打印
- 或进行筛选 数学运算等
print(s2[s2 > 0])
print(s2 * 2)
print(np.exp(s2))
输出结果:
- in 判断index值是否存在,返回一个bool值
如上例中
‘b’ in s2 则会返回True
‘e’ in s2 返回false
删除指定轴上的数据
# Sereis中的drop()操作
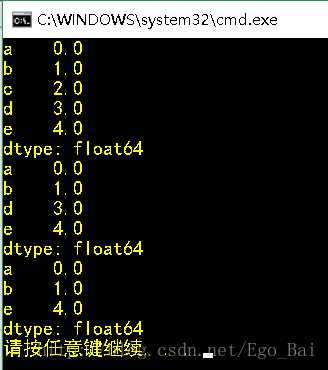
s = Series(np.arange(5.), index=['a', 'b', 'c', 'd','e'])
print(s)
print(s.drop('c'))
print(s.drop(['c','d']))
DataFrame
- DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型。==既有行索引,又有列索引。==
- DataFrame中面向行的和面向列的操作基本是平衡的,它的数据是由一个或多个二维块存放的。
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
frame = DataFrame(data) #用一个dict对象创建DataFrame,注意各项的value值个数要相同
print(frame)
- 如果columns的值与data的key值不符时,会新生成一列数据 值为NaN(Not a Number非数)
print(DataFrame(data, columns=['year', 'state', 'pp']))
#columns的值pp与data的key值不符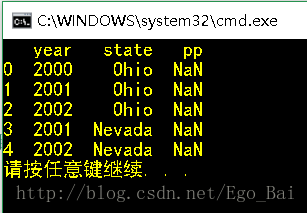
- 这里的索引对象同样负责管理轴标签和其他元数据
可以通过index对象对当前DataFrame进行
- 行/列顺序调整
- 引用指定列/行
- 给指定列/行赋值(可以为单个值,也可以用一个Series赋值给该列的指定行(用index指定)
frame2 = DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four', 'five']) #指定列名和index
frame2['debt'] = Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five']) #用Series给列的指定行赋值
print(frame2)
frame3 = DataFrame(data,columns=['year', 'state', 'pop', ],
index=['one', 'two', 'three', 'four', 'five'])
frame3.index.name = 'sequence'
frame3.columns.name = 'state'
print(frame3)这里介绍一下Index对象的方法与属性
pandas的索引对象
- pandas的索引对象负责管理轴标签和其他元数据。==index对象是不可以修改(immutable)的。==
pandas中主要的index对象:
| 类 | 说明 |
|---|---|
| Index | 最泛化的Index对象,将轴标签表示为一个有Python对象组成的Numpy数组 |
| Int64Index | 针对整数的特殊Index |
| MultiIndex | 层次化”索引对象,表示单个轴上的多层索引。可以看做由元组组成的数组 |
| DatetimeIndex | 存储纳秒级的时间戳 |
| PeriodIndex | 针对Period数据的特殊Index |
index的常用方法和属性:
| 方法 | 说明 |
|---|---|
| append | 连接另一个Index对象,产生一个新的Index |
| diff | 计算差集,并得到一个Index |
| intersection | 计算交集 |
| union | 计算并集 |
| isin | 计算一个指示各值是否都包含在参数集合中的布尔型数值 |
| delete | 删除索引i处的元素,并得到新的Index |
| drop | 删除传入的值,并得到新的Index |
| insert | 将元素插入到索引i处,并得到新的Index |
| is_monottonic | 当各元素均大于等于前一个元素时,返回True |
| is_unique | 当Index没有重复值时,返回True |
| unique | 计算Index中唯一值的数组 |
index1=pd.Index(np.arange(5))
index2=pd.Index(np.arange(7))
print(index2.union(index1))#union计算并集
输出:

reindex插值的method选项:
| 参数 | 说明 |
|---|---|
| ffill 或 pad | 前向填充 |
| bfill 或 backfill | 后向填充 |
reindex函数的参数:
| 参数 | 说明 |
|---|---|
| index | 用作索引的新索引 |
| method | 插值(填充方式) |
| fill_value | 在重新检索的过程中,需要引入缺失值时使用的替代值 |
| limit | 前向或后向填充时的最大填充量 |
| level | 在MultiIndex的指定级别上匹配简单索引,否则选取其子集 |
| copy | 默认为True |
obj=Series([4,5,5.5,8.46],index=['d','b','a','c'])
print obj.reindex(['a','b','c','d','e'])
print obj.reindex(['a','b','c','d','e'],fill_value=0)#补0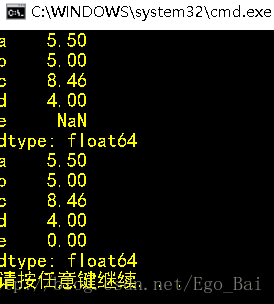
- 向后填充
print(obj3)
obj3 = Series(['blue', 'purple', 'yellow'], index = [0,2,4])
print(obj3.reindex(range(6), method = 'bfill'))
print(obj3.reindex(range(6), method = 'backfill')) 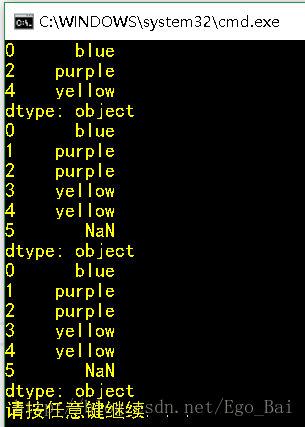
- 向前填充
obj3 = Series(['blue', 'purple', 'yellow'], index = [0,2,4])
print(obj3.reindex(range(6), method = 'ffill'))
print(obj3.reindex(range(6), method = 'pad')) #pad与ffill相同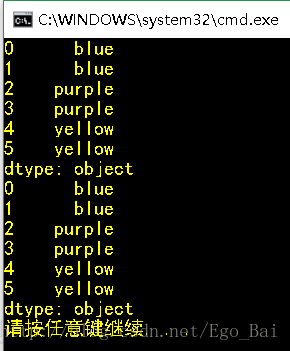
对于Sereis, DataFrame的删除操作
丢弃指定轴上的数据:
- Sereis中的drop()操作
# Sereis中的drop()操作
obj = Series(np.arange(5), index=['a', 'b', 'c', 'd', 'e'])
print(obj.drop('a'))
print(obj.drop(['a', 'b']))
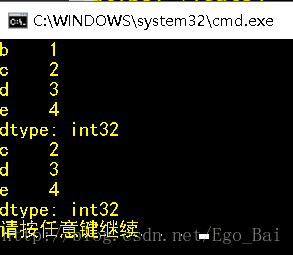
可以看到已经分别删除了索引a,索引a、b所对应的行
- DataFrame中的drop()操作 *
# DataFrame中的drop()操作
data = DataFrame(np.arange(16).reshape((4, 4)), index = ['a', 'b', 'c', 'd'], columns = ['one', 'two', 'three', 'four'])
data.drop(['a', 'b'])
data.drop(['one', 'four'], axis = 1)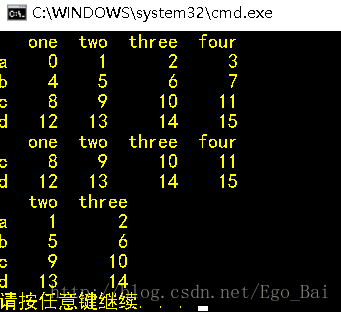
最后总结一下DataFrame的索引选项
类型
obj[:,val] 选择单个列或者列子集
reindex 重新索引
xs 根据标签选取单行或者单列,返回一个Series
icol,irow 根据整数选取单行或者单列,返回一个Series
| 类型 | 说明 |
|---|---|
| obj[val] | 选取DataFrame的单个列或者一行列。在一些特殊情况下会比较便利:==如布尔型数组,切片,布尔型DataFrame== |
| obj.ix[val] | 选取单个行或者一组行 |
| obj.ix[val1, val2] | 同时选取行和列 |
| obj[:,val] | 选择单个列或者列子集 |
| reindex | 重新索引 |
| xs | 根据标签选取单行或者单列,返回一个Series |
| icol,irow | 根据整数选取单行或者单列,返回一个Series(即将弃用) |
| get_value, set_value | 根据行标签和列标签选取单个值 |
部分示例来自书《利用Python进行数据分析》以及 网络
还有一些操作如算术运算和数据对齐、排序、汇总和计算描述统计、相关系数与协方差、缺失数据处理等时间关系下次接着写给大家
吃饭上课去~