本文将介绍:
- 混淆矩阵(Confusion Matrix)
- 准确率(accuracy)
- 召回率(recall)
- 精确率(precision)
- F1score
- ROC和AUC
- 宏平均(macro avg)
- 微平均(micro avg)
- 加权平均(weighted avg)
一,混淆矩阵(Confusion Matrix)
在n分类模型中,使用n行n列的矩阵形式来表示精度,纵列代表n个分类,在每行中的n个数据代表分别预测在每个类别的个数,完美的预测应该是一个列序数=行中有数据的索引数的一条斜线。
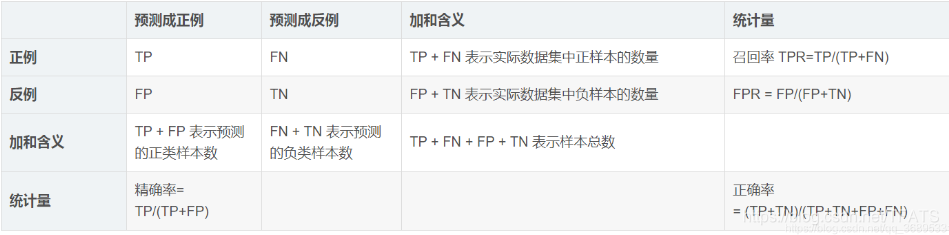
- TP:True Positive :做出Positive的判定,而且判定是正确的
- FP:False Positive :做出Positive的判定,而且判定是错误的
- TN:True Negative :正确的Negative判定
- FN:False Negative:错误的Negative判定
二,准确率(accuracy)
计算公式: accuracy = (TP + TN) / (TP + FP + TN + FN)
在正例较少负例较多的不平衡分类问题(疾病;恐怖分子)中,存在着如果把所有数据全部预测为负例,准确率依然会很高的问题,所以这里引入召回率。
三,召回率(recall)
召回率可以被理解为模型找到数据集中所有感兴趣的数据点的能力。
计算公式:recall = TP / (TP + FN) 所有正确的条目中有多少被检索出来
如果我们将所有的个体都预测为正样例,那么模型的召回率就是 1.0,但这明显也是错误的,所以这里引入精确率。
四,精确率(precision)
精确率可以被理解为模型找到的所以正例的准确性。
计算公式:precision= TP / (TP + FP) 所有预测为正确的条目中有多少真正正确的
随着精度的增加,召回率会降低,反之亦然。
五,F1score
F1 score 是对精度和召回率的调和平均:
F1 Score = 2*P*R/(P+R),其中P和R分别为 precision 和 recall
我们使用调和平均而不是简单的算术平均的原因是:调和平均可以惩罚极端情况。一个具有 1.0 的精度,而召回率为 0 的分类器,这两个指标的算术平均是 0.5,但是 F1 score 会是 0。F1 score 给了精度和召回率相同的权重,它是通用 Fβ指标的一个特殊情况,如果我们想创建一个具有最佳的精度—召回率平衡的模型,那么就要尝试将 F1 score 最大化。
六,ROC和AUC
思想是相当简单的:ROC 曲线展示了当改变在模型中识别为正例的阈值时,召回率和精度的关系会如何变化。
计算公式如下:
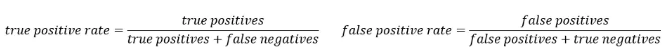
TPR = TP / (TP + FN) TPR 是召回率
FPR = FP / (FP + TN) FPR 是反例被报告为正例的概率
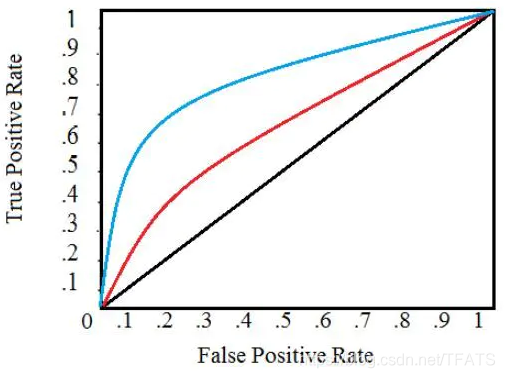
下图是一个典型的 ROC 曲线:
-
黑色对角线表示随机分类器,红色和蓝色曲线表示两种不同的分类模型。对于给定的模型,只能对应一条曲线。但是我们可以通过调整对正例进行分类的阈值来沿着曲线移动。通常,当降低阈值时,会沿着曲线向右和向上移动。
-
在阈值为 1.0 的情况下,我们将位于图的左下方,因为没有将任何数据点识别为正例,这导致没有真正例,也没有假正例(TPR = FPR = 0)。当降低阈值时,我们将更多的数据点识别为正例,导致更多的真正例,但也有更多的假正例 ( TPR 和 FPR 增加)。最终,在阈值 0.0 处,我们将所有数据点识别为正,并发现位于 ROC 曲线的右上角 ( TPR = FPR = 1.0 )。
-
最后,我们可以通过计算曲线下面积 ( AUC ) 来量化模型的 ROC 曲线,这是一个介于 0 和 1 之间的度量,数值越大,表示分类性能越好。在上图中,蓝色曲线的 AUC 将大于红色曲线的 AUC,这意味着蓝色模型在实现准确度和召回率的权衡方面更好。随机分类器 (黑线) 实现 0.5 的 AUC。
七,宏平均(macro avg)、微平均(micro avg)、加权平均(weighted avg)
当我们使用 sklearn.metric.classification_report 工具对模型的测试结果进行评价时,会输出如下结果:
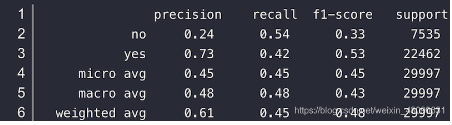
1、宏平均 macro avg:
对每个类别的 精准、召回和F1 加和求平均。
精准 macro avg=(P_no+P_yes)/2=(0.24+0.73)/2 = 0.48
2、微平均 micro avg:
不区分样本类别,计算整体的 精准、召回和F1
精准 macro avg=(P_nosupport_no+P_yessupport_yes)/(support_no+support_yes)=(0.247535+0.73)/(7535+22462)=0.45
3、加权平均 weighted avg:
是对宏平均的一种改进,考虑了每个类别样本数量在总样本中占比
精准 weighted avg =P_no*(support_no/support_all)+ P_yes*(support_yes/support_all =0.24*(7525/29997)+0.73*(22462/29997)=0.61