机器学习分类中的常用指标,这几个指标最大的特点,其实是容易看完就忘。。
英文
TP true positive, 前面的字母代表预测是否正确,后面的字母代表预测的类型,TP是预测正确的正例,预测为1实际也为1
TN true negative预测正确的负例,预测为0实际也为0
FP false positive预测错误,预测为正例,实际为负例,所以是预测错误的负例,预测为1实际为0
FN false negative预测错误的正例,预测为1实际为0
准确率-accuracy
精确率-precision
召回率-recall
F1分数-F1-score
ROC 曲线 Receiver Operating Characteristic curve
ROC曲线下面积-ROC-AUC(area under curve)

PR曲线 precision recall curve
PR曲线下面积-PR-AUC
准确率
准确率和精确率是一对在字面上很容易搞混的名词,准确率 = 预测正确的样本数量/预测总的样本数量。准确率指标在不平衡样本的情况下,基本没有什么实质性说明作用。这很容易理解,假设有100条样本,其中99条正例,1条反例。假设一个模型对所有样本均预测为正例,则这个模型的准确率为99%。然而它并没有泛化作用,因为它无法预测反例。
精确率/召回率
精确率和召回率关系紧密,是一对在含义上很容易混淆的名词。
精确率针对预测结果,所有预测为正的样本的包括:将正例预测为正(TP),负例预测为正(FP)
精确率,即为预测正确的正例(TP)在所有预测为正例的样本中出现的概率,即分类正确的正样本个数占分类器判定为正样本的样本个数的比例:
而召回率针对原始样本,原始的正例可能被预测为:正例预测为正(TP),正例预测为负(FN)
召回率,即为预测正确的正例(TP)在原始的所有正例样本中出现的概率,即分类正确的正样本个数占真正的正样本个数的比例:
拿一个图进行说明的话就是:
一个例子:
- TP: 将正类预测为正类数 40
- FN: 将正类预测为负类数 20
- FP: 将负类预测为正类数 10
- TN: 将负类预测为负类数 30
准确率(accuracy) = 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN) = 70%
精确率(precision) = TP/(TP+FP) = 80%
召回率(recall) = TP/(TP+FN) = 2/3
F1分数
F1score综合考虑了精确率和召回率,是它们的调和平均数。
![]()
很有可能精确率低,召回率高;和精确率高,召回率低这两组最后得到的F1分数可能差不多。
在多类别分类评估下,需要用到micro-F1 score和macro-F1 score。
micro-F1 score
它未区分类别,而是直接使用总体样本进行计算。比如有A/B/C三类,若将A预测为A就记为1个TP,若将A预测为B或者C就记为1个FN,B和C同理。最后通过精确率和召回率计算出的F1就是micro的。
macro-F1 score
它对类别进行了区分,对于每一类的样本分别计算F1 score,最后将所有类的F1 score求算术平均值。一般来说,用macro会比用micro更好一些,因为在不均衡样本的情况下,macro受到小数量类别样本的影响会更大,更能体现模型的漏洞和缺陷。
灵敏度/真正率 True Positive Rate
灵敏度/真正率就是召回率。
灵敏度 = TP/(TP+FN)
特异度
特异度和灵敏度(召回率)完全相反。灵敏度求的是预测正确的正例与所有正例的比率,特异度求的是预测正确的负例与所有负例的比率。
![]()
假正率 False Positive Rate
假正率 = 1 - 特异度 = FP/(TN + FP)
它代表预测错误的负例与所有负例的比率。
ROC 曲线
提到真正率、假正率的目的就是为了说明ROC。
假设回到一开始的不均衡样本问题,开始已经阐述过在不均衡样本问题中使用准确率作为评判标准是有水分的。
但是用真正率和假正率不会。假设有90%正例,真正率只关注预测正确的正例比这90%正例的比率;假正率只关注预测错误的负例与10%负例的比率。这就避免了样本不平衡的问题,也是为什么选择TPR和FPR作为ROC的指标。
ROC的横坐标为FPR,纵坐标为TPR。
ROC是通过遍历所有阈值来进行绘制的。也就是说,曲线上的每一个点代表着,在某一阈值下,模型将大于该阈值的结构判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的真正率和假正率。对于一个输出概率的模型,例如逻辑回归,改变阈值,会改变TP和FP的数量。
通过遍历所有阈值,我们会得到一系列(FPR,TPR)的点,这些点构成曲线,点越多,曲线越光滑。
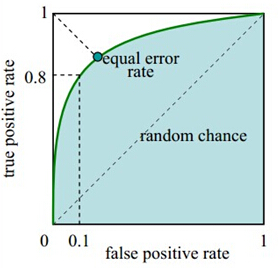
可以想象,我们希望曲线经过越左上的点越好,也就是FRP越小,TPR越大。极端的点为(0,1),FRP为0代表所有负例预测正确,TPR为1代表所有正例预测正确,于是所有样本预测正确。而曲线若经过(0.5,0.5)这个点,代表随机判断,一半预测正确一半预测错误。曲线两端的点,分别代表阈值设为0,所有都预测为正,所以为(1,1);阈值设为正无穷,所有都预测为负,所以为(0,0)。
AUC
ROC曲线下面积。一般来说模型不可能做的比随机判断还差,所以AUC取值一般在0.5-1。理想的就是一个正方形。AUC对所有的阈值进行了一个综合评估,来反映模型的好坏。
PR曲线 precision recall curve
类似ROC,以召回率为x轴,精确率为y轴就得到了PR曲线。
我们当然希望不同的阈值下精确率和召回率越大越好,于是极端的点就是(1,1),所以曲线如果越往右上靠说明模型整体性能越好。
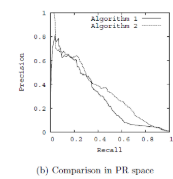
ROC与PR的比较
相比PR,ROC有一个特点,当正负样本的分布发生变化时,ROC的形状能够保持基本不变,而PR曲线的形状一般会发生比较剧烈的变化。

支持度

注意:{尿布,啤酒}的支持度等于{啤酒,尿布}的支持度,支持度没有先后顺序之分。
置信度

提升度
举个栗子:
10000个超市订单(10000个事务),其中购买三元牛奶(A事务)的6000个,购买伊利牛奶(B事务)的7500个,4000个同时包含两者。
A和B的支持度为:4000/10000 = 0.4
A对B的置信度为:4000/6000 = 0.67 说明在购买三元牛奶后又67%的人又购买了伊利牛奶。
B对A的置信度为:4000/7500 = 0.53
A对B的提升度为:0.67/0.75 = 0.89 即以A作为前提,对B出现的概率有什么影响,如果提升度为1说明AB没有任何关联,如果小于1说明AB是互斥的,如果大于1,认为AB是有关联的,但在具体任务中认为提升度大于3才是值得认可的关联。
