在机器学习、数据挖掘领域,工业界往往会根据实际的业务场景拟定相应的业务指标。本文旨在一起学习比较经典的三大类评价指标,其中第一、二类主要用于分类场景、第三类主要用于回归预测场景,基本思路是从概念公式,到优缺点,再到具体应用(分类问题,本文以二分类为例)。
1.准确率P、召回率R、F1 值
- 定义
- 准确率(Precision):P=TP/(TP+FP)。通俗地讲,就是预测正确的正例数据占预测为正例数据的比例。
- 召回率(Recall):R=TP/(TP+FN)。通俗地讲,就是预测为正例的数据占实际为正例数据的比例
- F1值(F score):
- 思考
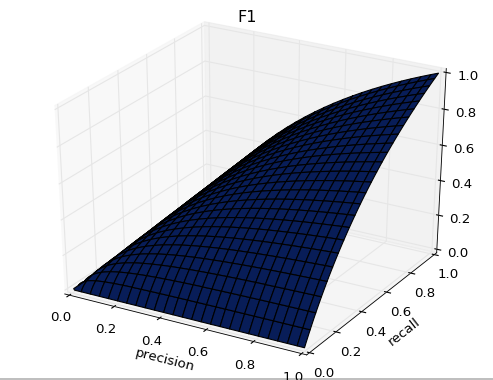
- 正如下图所示,F1的值同时受到P、R的影响,单纯地追求P、R的提升并没有太大作用。在实际业务工程中,结合正负样本比,的确是一件非常有挑战的事。
- 图像展示
- 下面附上源码
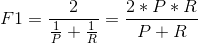
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
fig = plt.figure()
ax = fig.add_subplot(111,projection='3d')
x = np.linspace(0,1,100)
p,r = np.meshgrid(x,x) #meshgrid函数创建一个二维的坐标网络
z = 2*p*r/(p+r)
ax.plot_surface(x,y,z,rstride=4,cstride=4,cmap=cm.YlGnBu_r)
ax.set_title('F1') #标题
ax.set_xlabel('precision') #x轴标签
ax.set_ylabel('recall') #y轴标签
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.ROC、AUC
- 概念
- TPR=TP/(TP+FN)=TP/actual positives
- FPR=FP/(FP+TN)=FP/actual negatives
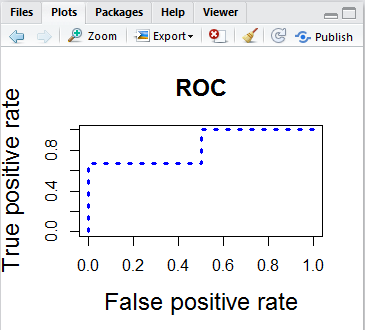
- ROC是由点(TPR,FPR)组成的曲线,AUC就是ROC的面积。AUC越大越好。
- 一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting
- 图像展示
- 附上代码

library(ROCR)
p=c(0.5,0.6,0.55,0.4,0.7)
y=c(1,1,0,0,1)
pred = prediction(p, y)
perf = performance(pred,"tpr","fpr")
plot(perf,col="blue",lty=3, lwd=3,cex.lab=1.5, cex.axis=2, cex.main=1.5,main="ROC plot")
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
- python版本计算AUC
from sklearn import metrics
def aucfun(act,pred):
fpr, tpr, thresholds = metrics.roc_curve(act, pred, pos_label=1)
return metrics.auc(fpr, tpr)
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
- 直接利用AUC优化分类任务(R语言版)
下面是代码

#生成训练数据
set.seed(1999)
x1 = rnorm(1000)
x2 = rnorm(1000)
z = 1 + 2*x1 + 3*x2
pr = 1/(1+exp(-z))
y = rbinom(1000,1,pr)
#使用logloss作为训练目标函数
df = data.frame(y=y,x1=x1,x2=x2)
glm.fit=glm( y~x1+x2,data=df,family="binomial")
#下面使用auc作为训练目标函数
library(ROCR)
CalAUC <- function(real,pred){
rocr.pred=prediction(pred,real)
rocr.perf=performance(rocr.pred,'auc')
as.numeric([email protected])
}
#初始值
beta0=c(1,1,1)
loss <- function(beta){
z=beta[1]+beta[2]*x1+beta[3]*x2
pred=1/(1+exp(-z))
-CalAUC(y,pred)
}
res=optim(beta0,loss,method = "Nelder-Mead",control = list(maxit = 100))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
3.PRC、ROC比较
- AUC是ROC的积分(曲线下面积),是一个数值,一般认为越大越好,数值相对于曲线而言更容易当做调参的参照。
- PR曲线会面临一个问题,当需要获得更高recall时,model需要输出更多的样本,precision可能会伴随出现下降/不变/升高,得到的曲线会出现浮动差异(出现锯齿),无法像ROC一样保证单调性。
- 在正负样本分布得极不均匀(highly skewed datasets)的情况下,PRC比ROC能更有效地反应分类器的好坏。
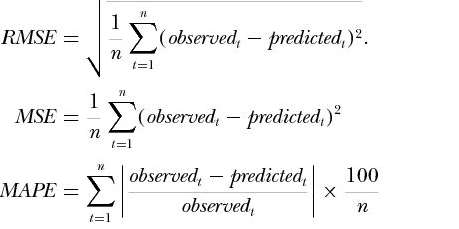
4.mape平均绝对百分误差
- 定义
- 技巧
- 在sklearn中,对于回归任务,一般都提供了mse损失函数(基于树的模型除外)。但有时我们会遇到sklearn中没有定义的损失函数,那么我们可以自定重写模型或者定义函数,下面以xgboost为模型,mape作为损失函数为例(grad、hess分别对应损失函数一阶导、二阶导)。
- 代码
def mapeobj(preds,dtrain):
gaps = dtrain.get_label()
grad = np.sign(preds-gaps)/gaps
hess = 1/gaps
grad[(gaps==0)] = 0
hess[(gaps==0)] = 0
return grad,hess
def evalmape(preds, dtrain):
gaps = dtrain.get_label()
err = abs(gaps-preds)/gaps
err[(gaps==0)] = 0
err = np.mean(err)
return 'error',err
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
参考资源
1.关于AUC,你应该知道的和可能不知道的 (PS.最近才知道,这篇文章的作者是工大的校友啊)
转载:https://blog.csdn.net/a819825294/article/details/51699211
在机器学习、数据挖掘领域,工业界往往会根据实际的业务场景拟定相应的业务指标。本文旨在一起学习比较经典的三大类评价指标,其中第一、二类主要用于分类场景、第三类主要用于回归预测场景,基本思路是从概念公式,到优缺点,再到具体应用(分类问题,本文以二分类为例)。
1.准确率P、召回率R、F1 值
- 定义
- 准确率(Precision):P=TP/(TP+FP)。通俗地讲,就是预测正确的正例数据占预测为正例数据的比例。
- 召回率(Recall):R=TP/(TP+FN)。通俗地讲,就是预测为正例的数据占实际为正例数据的比例
- F1值(F score):
- 思考
- 正如下图所示,F1的值同时受到P、R的影响,单纯地追求P、R的提升并没有太大作用。在实际业务工程中,结合正负样本比,的确是一件非常有挑战的事。
- 图像展示
- 下面附上源码
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
fig = plt.figure()
ax = fig.add_subplot(111,projection='3d')
x = np.linspace(0,1,100)
p,r = np.meshgrid(x,x) #meshgrid函数创建一个二维的坐标网络
z = 2*p*r/(p+r)
ax.plot_surface(x,y,z,rstride=4,cstride=4,cmap=cm.YlGnBu_r)
ax.set_title('F1') #标题
ax.set_xlabel('precision') #x轴标签
ax.set_ylabel('recall') #y轴标签
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.ROC、AUC
- 概念
- TPR=TP/(TP+FN)=TP/actual positives
- FPR=FP/(FP+TN)=FP/actual negatives
- ROC是由点(TPR,FPR)组成的曲线,AUC就是ROC的面积。AUC越大越好。
- 一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting
- 图像展示
- 附上代码
library(ROCR)
p=c(0.5,0.6,0.55,0.4,0.7)
y=c(1,1,0,0,1)
pred = prediction(p, y)
perf = performance(pred,"tpr","fpr")
plot(perf,col="blue",lty=3, lwd=3,cex.lab=1.5, cex.axis=2, cex.main=1.5,main="ROC plot")
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
- python版本计算AUC
from sklearn import metrics
def aucfun(act,pred):
fpr, tpr, thresholds = metrics.roc_curve(act, pred, pos_label=1)
return metrics.auc(fpr, tpr)
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
- 直接利用AUC优化分类任务(R语言版)
下面是代码
#生成训练数据
set.seed(1999)
x1 = rnorm(1000)
x2 = rnorm(1000)
z = 1 + 2*x1 + 3*x2
pr = 1/(1+exp(-z))
y = rbinom(1000,1,pr)
#使用logloss作为训练目标函数
df = data.frame(y=y,x1=x1,x2=x2)
glm.fit=glm( y~x1+x2,data=df,family="binomial")
#下面使用auc作为训练目标函数
library(ROCR)
CalAUC <- function(real,pred){
rocr.pred=prediction(pred,real)
rocr.perf=performance(rocr.pred,'auc')
as.numeric([email protected])
}
#初始值
beta0=c(1,1,1)
loss <- function(beta){
z=beta[1]+beta[2]*x1+beta[3]*x2
pred=1/(1+exp(-z))
-CalAUC(y,pred)
}
res=optim(beta0,loss,method = "Nelder-Mead",control = list(maxit = 100))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
3.PRC、ROC比较
- AUC是ROC的积分(曲线下面积),是一个数值,一般认为越大越好,数值相对于曲线而言更容易当做调参的参照。
- PR曲线会面临一个问题,当需要获得更高recall时,model需要输出更多的样本,precision可能会伴随出现下降/不变/升高,得到的曲线会出现浮动差异(出现锯齿),无法像ROC一样保证单调性。
- 在正负样本分布得极不均匀(highly skewed datasets)的情况下,PRC比ROC能更有效地反应分类器的好坏。
4.mape平均绝对百分误差
- 定义
- 技巧
- 在sklearn中,对于回归任务,一般都提供了mse损失函数(基于树的模型除外)。但有时我们会遇到sklearn中没有定义的损失函数,那么我们可以自定重写模型或者定义函数,下面以xgboost为模型,mape作为损失函数为例(grad、hess分别对应损失函数一阶导、二阶导)。
- 代码
def mapeobj(preds,dtrain):
gaps = dtrain.get_label()
grad = np.sign(preds-gaps)/gaps
hess = 1/gaps
grad[(gaps==0)] = 0
hess[(gaps==0)] = 0
return grad,hess
def evalmape(preds, dtrain):
gaps = dtrain.get_label()
err = abs(gaps-preds)/gaps
err[(gaps==0)] = 0
err = np.mean(err)
return 'error',err
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
参考资源
1.关于AUC,你应该知道的和可能不知道的 (PS.最近才知道,这篇文章的作者是工大的校友啊)
转载:https://blog.csdn.net/a819825294/article/details/51699211