精确率表示的是预测为某类样本(例如正样本)中有多少是真正的该类样本,一般用来评价分类任务模型。
比如对于一个分类模型,预测结果为A类的所有样本中包含A0个真正的A样本,和A1个不是A样本的其他类样本,那么该分类模型对于分类A的精确率就是A0/(A0+A1)。
通常来说精确率越高,分类效果越好。但是在样本分布非常不均衡的情况下, 精确率高并不一定意味着是一个好的模型。
说明:
比如对于一个分类模型,预测结果为A类的所有样本中包含A0个真正的A样本,和A1个不是A样本的其他类样本,那么该分类模型对于分类A的精确率就是A0/(A0+A1)。
通常来说精确率越高,分类效果越好。但是在样本分布非常不均衡的情况下, 精确率高并不一定意味着是一个好的模型。
比如对于预测长沙明天是否会下雪的模型,在极大概率下长沙是不会下雪的,所以随便一个模型预测长沙不会下雪,它的精确率都可以达到99%以上,所以单纯靠准确率来评价一个算法模型在有些情况下是完全不够的。
召回率表示的是样本中的某类样本有多少被正确预测了。比如对与一个分类模型,A类样本包含A0个样本,预测模型分类结果是A类样本中有A1个正样本和A2个其他样本,那么该分类模型的召回率就是 A1/A0,其中 A1+A2=A0
准确率表示的是所有分类中被正确分类的样本比例,比如对于一个分类模型,样本包含A和B两类,模型正确识别了A类中的A0个样本,B类中的B0个样本,则准确率为 (A0+B0)/(A+B)
ROC曲线和AUC
ROC(Receiver Operating Characteristic)曲线是以假正率(FP_rate)和真正率(TP_rate)为轴的曲线,ROC曲线下面的面积我们叫做AUC,如下图所示:
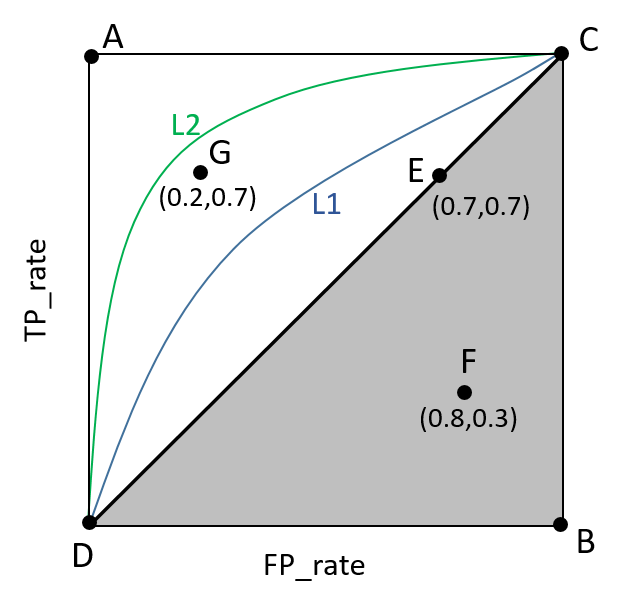
说明:
- 曲线与FP_rate轴围成的面积(记作AUC)越大,说明性能越好,即:曲线越靠近A点(左上方)性能越好,曲线越靠近B点(右下方)曲线性能越差。
- A点是最完美的performance点,B处是性能最差点。
- 位于C-D线上的点说明算法性能和随机猜测是一样的–如C、D、E点。位于C-D之上说明算法性能优于随机猜测–如G点,位于C-D之下说明算法性能差于随机猜测–如F点。
- ROC曲线在高不平衡数据条件下仍不能够很好的展示实际情况