本文来源 机器之心编辑部 有增删
近年来,图像生成技术取得了很多关键性突破。特别是自从 DALLE2、Stable Diffusion 等大模型发布以来,文本生成图像技术逐渐成熟,高质量的图像生成有了广阔的实用场景。然而,对于已有图片的细化编辑依旧是一个难题。
一方面,由于文本描述的局限性,现有的高质量文生图模型,只能利用文本对图片进行描述性的编辑,而对于某些具体效果,文本是难以描述的;另一方面,在实际应用场景中,图像细化编辑任务往往只有少量的参考图片,这让很多需要大量数据进行训练的方案,在少量数据,特别是只有一张参考图像的情况下,难以发挥作用。
最近,来自网易互娱 AI Lab 的研究人员提出了一种基于单张图像引导的图像到图像编辑方案,给定单张参考图像,即可把参考图中的物体或风格迁移到源图像,同时不改变源图像的整体结构。研究论文已被 ICCV 2023 接收,相关代码已开源。
论文地址:https://arxiv.org/abs/2307.14352
代码地址:https://github.com/CrystalNeuro/visual-concept-translator
让我们先来看一组图,感受一下它的效果。

论文效果图:每组图片左上角是源图,左下角是参考图,右侧是生成结果图
主体框架
论文作者提出了一种基于逆映射-融合(Inversion-Fusion)的图像编辑框架 ——VCT(visual concept translator,视觉概念转换器)。如下图所示,VCT 的整体框架包括两个过程:内容-概念的映射过程(Content-concept Inversion)和内容-概念的融合过程(Content-concept Fusion)。内容 - 概念过程通过两种不同的逆映射算法,分别学习和表示原图像的结构信息和参考图像的语义信息的隐向量;内容-概念融合过程则将结构信息和语义信息的隐向量进行融合,生成最后的结果。
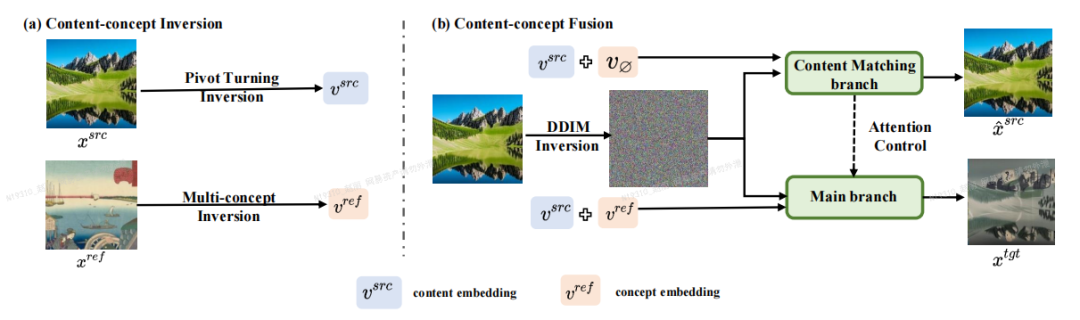
论文主体框架
值得一提的是,逆映射方法是近年来,特别是在生成对抗网络(GAN)领域,广泛应用且在众多图像生成任务上取得突出效果的一项技术【1】。GAN Inversion 技术将一张图片映射到与训练的 GAN 生成器的隐空间中,通过对隐空间的控制来实现编辑的目的。逆映射方案可以充分利用预训练生成模型的生成能力。本研究实际上是将 GAN Inversion 技术迁移到了以扩散模型为先验的,基于图像引导的图像编辑任务上。

逆映射技术【1】
方法介绍
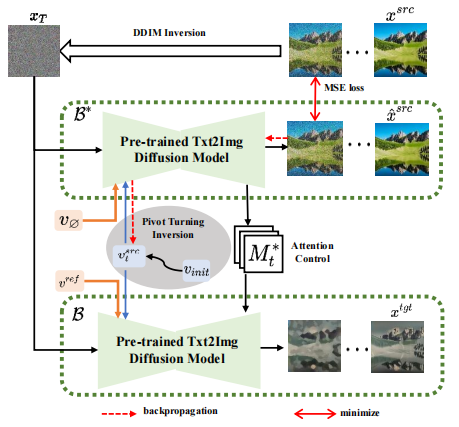
基于逆映射的思路,VCT 设计了一个双分支的扩散过程,其包含一个内容重建的分支 B* 和一个用于编辑的主分支 B。它们从同一个从 DDIM 逆映射(DDIM Inversion【2】,一种利用扩散模型从图像计算噪声的算法)获得的噪声 xT 出发,分别用于内容重建和内容编辑。论文采用的预训练模型为隐向量扩散模型(Latent Diffusion Models,简称 LDM),扩散过程发生在隐向量空间 z 空间中,双分支过程可表示为:
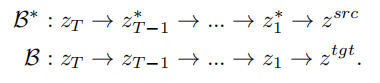
双分支扩散过程
内容重建分支 B* 学习 T 个内容特征向量 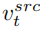 ,用于还原原图的结构信息,并通过软注意力控制(soft attention control)的方案,将结构信息传递给编辑主分支 B。软注意力控制方案借鉴了谷歌的 prompt2prompt【3】工作,公式为:
,用于还原原图的结构信息,并通过软注意力控制(soft attention control)的方案,将结构信息传递给编辑主分支 B。软注意力控制方案借鉴了谷歌的 prompt2prompt【3】工作,公式为:
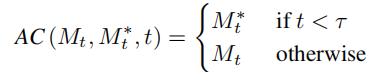
即当扩散模型运行步数在一定区间时,将编辑主分支的注意力特征图替换内容重建分支的特征图,实现对生成图片的结构控制。编辑主分支 B 则融合从原图像学习的内容特征向量 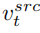 和从参考图像学习的概念特征向量
和从参考图像学习的概念特征向量 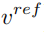 ,生成编辑的图片。
,生成编辑的图片。

噪声空间 ( 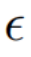 空间) 融合
空间) 融合
在扩散模型的每一步,特征向量的融合都发生在噪声空间空间,是特征向量输入扩散模型之后预测的噪声的加权。内容重建分支的特征混合发生在内容特征向量 和空文本向量上,与免分类器(Classifier-free)扩散引导【4】的形式一致:
和空文本向量上,与免分类器(Classifier-free)扩散引导【4】的形式一致:
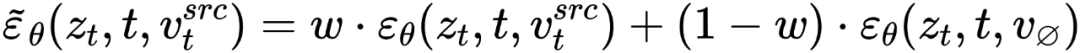
编辑主分支的混合是内容特征向量 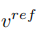 和概念特征向量
和概念特征向量 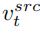 的混合,为
的混合,为
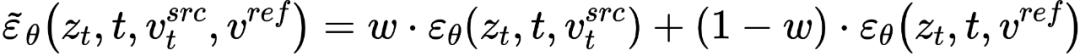
至此,研究的关键在于如何从单张源图片获取结构信息的特征向量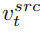 ,和从单张参考图片获取概念信息的特征向量
,和从单张参考图片获取概念信息的特征向量 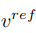 。文章分别通过两个不同的逆映射方案实现这一目的。
。文章分别通过两个不同的逆映射方案实现这一目的。
为了复原源图片,文章参考 NULL-text【5】优化的方案,学习 T 个阶段的特征向量去匹配拟合源图像。但与 NULL-text 优化空文本向量去拟合 DDIM 路径不同的是,本文通过优化源图片特征向量,去直接拟合估计的干净特征向量,拟合公式为:
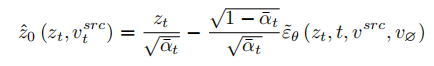
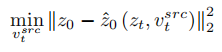
与学习结构信息不同的是,参考图像中的概念信息需要用单一高度概括的特征向量来表示,扩散模型的 T 个阶段共用一个概念特征向量 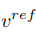 。文章优化了现有的逆映射方案 Textual Inversion【6】和 DreamArtist【7】。其采用一个多概念特征向量来表示参考图像的内容,损失函数包含一项扩散模型的噪声预估项和在隐向量空间的预估重建损失项:
。文章优化了现有的逆映射方案 Textual Inversion【6】和 DreamArtist【7】。其采用一个多概念特征向量来表示参考图像的内容,损失函数包含一项扩散模型的噪声预估项和在隐向量空间的预估重建损失项:
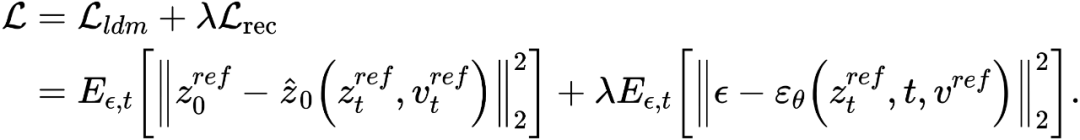
实验结果
文章在主体替换和风格化任务上进行了实验,可以在较好地保持源图片的结构信息的情况下,将内容变成参考图片的主体或风格。

论文实验效果
文章提出的 VCT 框架相较于以往的方案有以下优势:
(1)应用泛化性:与以往的基于图像引导的图像编辑任务相比,VCT 不需要大量的数据进行训练,且生成质量和泛化性更好。其基于逆映射的思路,以在开放世界数据预训练好的高质量文生图模型为基础,实际应用时,只需要一张输入图和一张参考图就可以完成较好的图片编辑效果。
(2)视觉准确性:相较于近期文字编辑图像的方案,VCT 利用图片进行参考引导。图片参考相比于文字描述,可以更加准确地实现对图片的编辑。下图展示了 VCT 与其它方案的对比结果:

主体替换任务对比效果

风格迁移任务对比效果
(3)不需要额外信息:相较于近期的一些需要添加额外控制信息(如:遮罩图或深度图)等方案来进行引导控制的方案,VCT 直接从源图像和参考图像学习结构信息和语义信息来进行融合生成,下图是一些对比结果。其中,Paint-by-example 通过提供一个源图像的遮罩图,来将对应的物体换成参考图的物体;Controlnet 通过线稿图、深度图等控制生成的结果;而 VCT 则直接从源图像和参考图像,学习结构信息和内容信息融合成目标图像,不需要额外的限制。

基于图像引导的图像编辑方案的对比效果
网易互娱 AI Lab
网易互娱 AI Lab 成立于 2017 年,隶属于网易互动娱乐事业群,是游戏行业领先的人工智能实验室。实验室致力于计算机视觉、语音和自然语言处理,以及强化学习等技术在游戏场景下的的研究和应用,旨在通过 AI 技术助力互娱旗下热门游戏及产品的技术升级,目前技术已应用于网易互娱旗下多款热门游戏,如《梦幻西游》、《哈利波特:魔法觉醒》、《阴阳师》、《大话西游》等等。
【1】Xia W, Zhang Y, Yang Y, et al. Gan inversion: A survey [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45 (3): 3121-3138.
【2】 Song J, Meng C, Ermon S. Denoising Diffusion Implicit Models [C]//International Conference on Learning Representations. 2020.
【3】Hertz A, Mokady R, Tenenbaum J, et al. Prompt-to-Prompt Image Editing with Cross-Attention Control [C]//The Eleventh International Conference on Learning Representations. 2022.
【4】Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications
【5】Mokady R, Hertz A, Aberman K, et al. Null-text inversion for editing real images using guided diffusion models [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 6038-6047.
【6】Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patash nik, Amit H Bermano, Gal Chechik, and Daniel Cohen Or. An image is worth one word: Personalizing text-to image generation using textual inversion. arXiv preprint arXiv:2208.01618, 2022
【7】Ziyi Dong, Pengxu Wei, and Liang Lin. Drea martist: Towards controllable one-shot text-to-image gen eration via contrastive prompt-tuning. arXiv preprintarXiv:2211.11337, 2022
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!