点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

Implicit Neural Representation for Cooperative Low-light Image Enhancement
【出处】ICCV 2023
论文:arxiv.org/abs/2303.11722
代码:https://github.com/Ysz2022/NeRCo
效果图

导读
本文聚焦于解决制约暗光算法应用的三个问题:训练集和现实暗光场景的退化特征的差异,现有的评价指标不能很好地衡量人眼感知质量,以及成对的训练集的欠缺。本文针对性地提出了三个机制以实现高效地暗光图像增强。具体来说,
作者发现经过隐式神经表示(INR)后的暗光图像的亮度会与原图有差异,且不同亮度的图像经过INR后都表现出相似亮度。作者利用这种特性归一化输入图像的退化分布,弥合训练数据和实际退化数据之间的特征差异,提升算法的泛化性。
为了得到人眼感知更良好的结果,作者还首次在暗光增强领域引入了CLIP模型的文本-图像对先验,其可以在语义的特征空间中训练模型,而非单一地在图像空间训练。
扫描二维码关注公众号,回复: 15945441 查看本文章
最后,作者提出了协同训练的机制,让模型能在非成对数据上训练,拜托了对有限成对训练集的依赖。
下面是作者在文章中给出的用INR归一化后的图像亮度变化图

方法
本文网络由以下部分组成:利用INR实现归一化的图像预处理模块(NRN),从语义空间和图像空间监督训练的鉴别器(TAD)和无监督的协同训练策略。
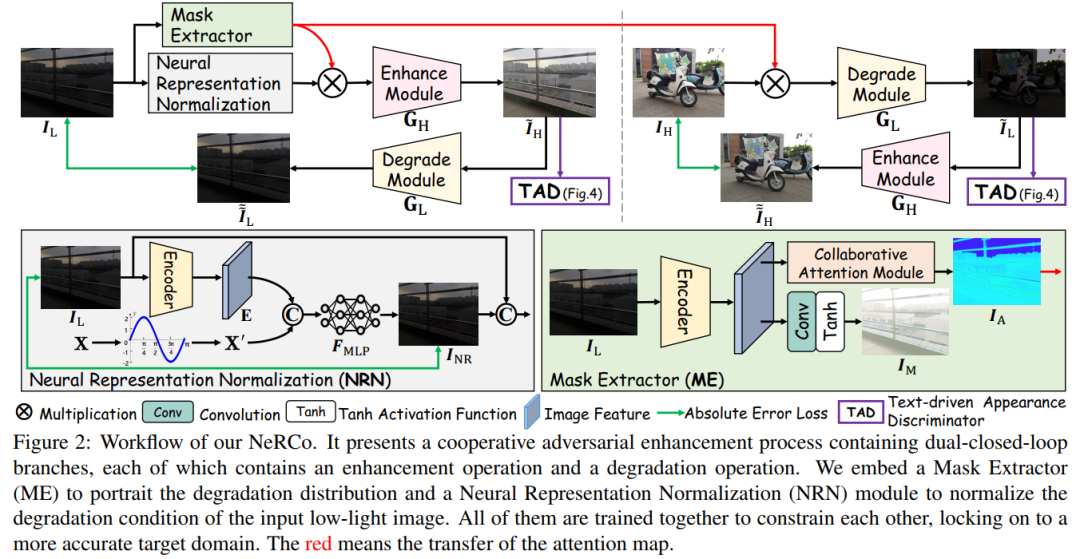
具体来说,
作者先将待增强的暗光图及其对应的空间坐标用全连接层进行编码,并输出一张图片,鼓励输出结果尽可能地与输入的暗光图相似。
然后,利用增强模块(ResNet)将其恢复成亮光结果。在此过程中还引入注意力模块以针对性地增强不同暗光区域。增强后的结果会喂给TAD鉴别其真伪。作者鼓励非成对的亮光自然图像被TAD鉴别为真,鼓励恢复的亮光结果为伪,以此训练增强模块。
文本驱动的外观鉴别器。该鉴别器由3条支路构成。输入的亮光图像(增强结果or数据集)会分别从颜色维度,高频分量和语义空间三个角度被监督:
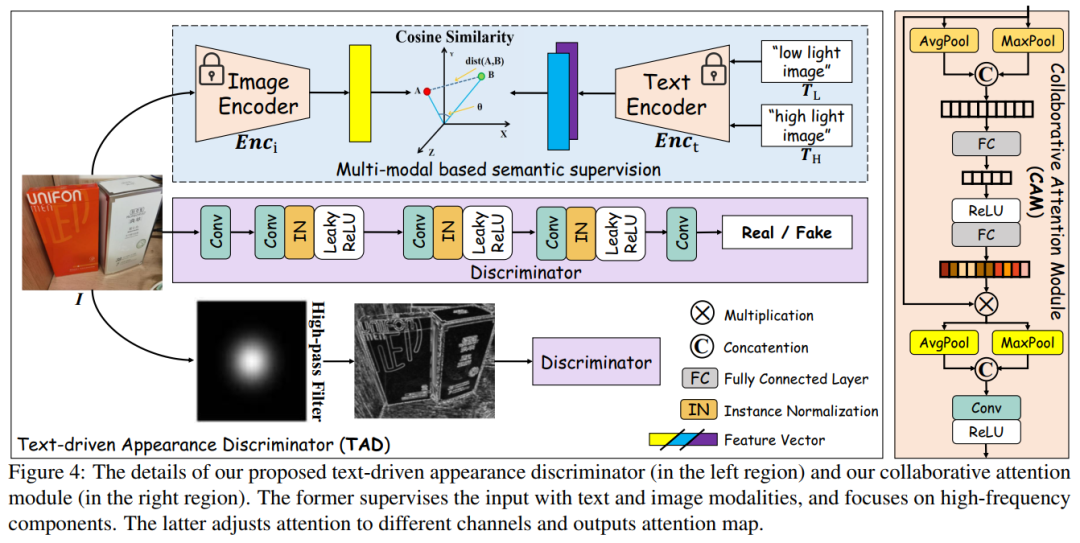
中间的紫色支路是一个普通鉴别器,判断输入图像在像素级别上与真实亮光图之间的差异。下方支路是由Sobel算子和鉴别器组成的高频分量鉴别器。Sobel算子先提取图像的高频分量,再由鉴别器判断其与真实图片的分布差异。上方是作者引入的CLIP先验指导的文本监督,通过对其图像特征和文本特征,引导模型向与文本更匹配的方向优化。实验证明引入文本监督后的模型,其增强结果更符合文本语义特征的分布,甚至比Ground Truth更符合:

作者认为这是因为受过CLIP先验的监督后,增强的图像在CLIP的特征空间中会更接近训练所选用的文本特征。作者也选用了不同的文本进行实验:
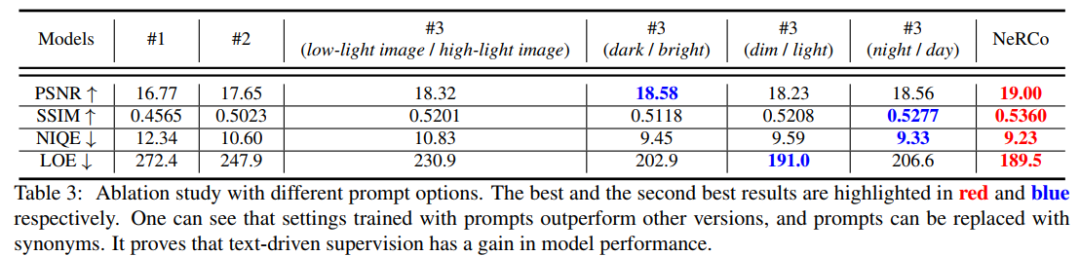
证明在暗光增强领域,可以选择不同文本指导训练。
实验
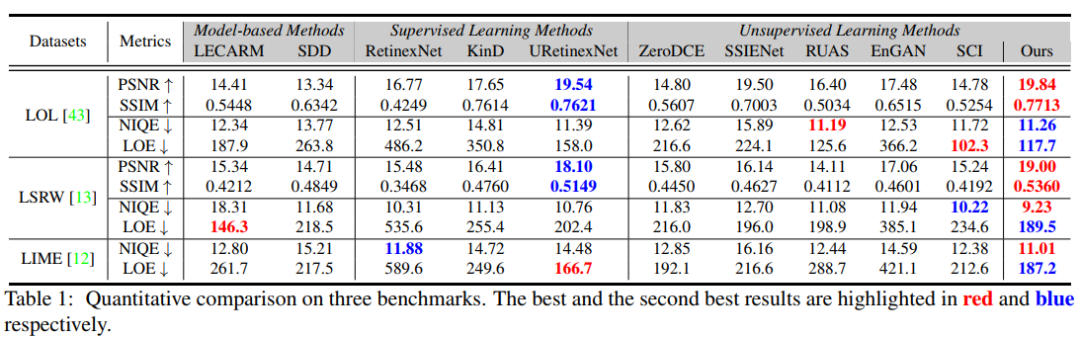
定量对比
定性对比

结论
本文提出了一种用于协同暗光增强的隐式神经表示方法。所提出的NRN对所有输入的退化图作归一化处理,提升模型的泛化性。并匹配了文本驱动的外观鉴别器,从语义,文本和颜色这三个角度两种模态(文本和图像)监督训练,以增加约束条件,加速寻找最优解并得到感知更佳的结果。最后,作者构建的协同训练框架可以在非成对的数据集上无监督训练。实验结果表明,所提出的 NeRCo 模型在实现竞争性能的同时比最先进的方法更有效。
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()