一、波士顿房屋价格预测代码
import sys
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import matplotlib as mpt
from sklearn.model_selection import train_test_split
##加载数据
data=pd.read_csv('./datas/boston_housing.data', sep='\s+',header=None)
##数据预处理
##获取特征属性X和目标属性Y
X=data.iloc[:,:-1]
Y=data.iloc[:,-1]
print("X的形状:",X.shape)
##划分训练集和测试集
xtrain,xtest,ytrain,ytest=train_test_split(X,Y,test_size=0.3)
##构建模型
##fit_intercept是否需要截距项
linear=LinearRegression(fit_intercept=True)
##模型训练
linear.fit(xtrain,ytrain)
print("linear.coef_参数:",linear.coef_)##参数
print("linear.intercept_截距项:",linear.intercept_)##截距项
ypredict=linear.predict(xtest)##测试集的预测结果
print("linear.score(xtrain,ytrain):",linear.score(xtrain,ytrain))##训练集的score
print("linear.score(xtest,ytest):",linear.score(xtest,ytest))##测试机的score
y_train_hat=linear.predict(xtrain)##训练集的预测结果
##训练集
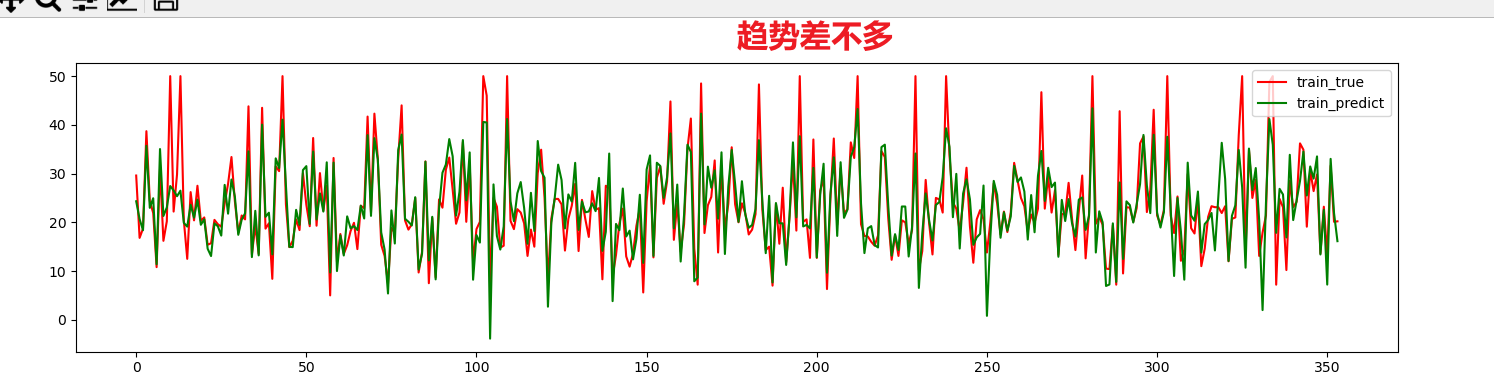
plt.figure(num='train')
plt.plot(range(len(xtrain)),ytrain,'r',label=u'train_true')
plt.plot(range(len(xtrain)),y_train_hat,'g',label=u'train_predict')
plt.legend(loc='upper right')
##测试集
plt.figure(num='test')
plt.plot(range(len(xtest)),ytest,'r',label=u'test_true')
plt.plot(range(len(xtest)),ypredict,'g',label=u'test_predict')
plt.legend(loc='upper right')
plt.show()

X的形状: (506, 13)
linear.coef_参数: [-7.71839713e-02 4.64518189e-02 7.07301749e-03 2.64903087e+00
-1.67266345e+01 3.64469823e+00 1.13463385e-02 -1.35154936e+00
2.50872813e-01 -1.01006435e-02 -1.00671453e+00 1.09409652e-02
-5.28701629e-01]###与特征数量一致
linear.intercept_截距项: 35.79041808015673##x0=1
linear.score(xtrain,ytrain): 0.730889354480308
linear.score(xtest,ytest): 0.753610702915135

二、波士顿房屋价格预测代码多项式
import sys
import pandas as pd
import numpy as np
from daal4py.sklearn.linear_model import Ridge
from sklearn.linear_model import LinearRegression, Lasso
import matplotlib.pyplot as plt
import matplotlib as mpt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
import warnings
warnings.filterwarnings('ignore')
##加载数据
data=pd.read_csv('./datas/boston_housing.data', sep='\s+',header=None)
##数据预处理
##获取特征属性X和目标属性Y
X=data.iloc[:,:-1]
Y=data.iloc[:,-1]
print("X的形状:",X.shape)
##划分训练集和测试集
xtrain,xtest,ytrain,ytest=train_test_split(X,Y,test_size=0.3)
##特征工程--多项式扩展
"""
PolynomanalFeatures ##多项式扩展
degree=2,扩展的阶数
interaction_only=False,是否只保留交互项
include_bias=True,是否需要偏置项
"""
print(type(xtrain))
print(xtrain.shape)
print(xtest.shape)
print(xtest.iloc[0, :])
"""
X的形状: (506, 13)
<class 'pandas.core.frame.DataFrame'>
(354, 13)
(152, 13)
0 1.15172
1 0.00000
2 8.14000
3 0.00000
4 0.53800
5 5.70100
6 95.00000
7 3.78720
8 4.00000
9 307.00000
10 21.00000
11 358.77000
12 18.35000
Name: 33, dtype: float64
"""
poly=PolynomialFeatures(degree=2,interaction_only=True,include_bias=True)
poly2=PolynomialFeatures(degree=2,interaction_only=False,include_bias=True)
poly3=PolynomialFeatures(degree=2,interaction_only=True,include_bias=False)
"""
特征工程:--根据设置和数据集--->先确定模型结构
poly=PolynomialFeatures(degree=2,interaction_only=True,include_bias=True)
poly2=PolynomialFeatures(degree=2,interaction_only=False,include_bias=True)
poly3=PolynomialFeatures(degree=2,interaction_only=True,include_bias=False)
fit:然后训练模型参数
fit_transform==>fit+transform
transform:在fit训练好的模型基础上,再进行具体的预测
"""
print(poly.fit(xtrain))#PolynomialFeatures(interaction_only=True)
print(poly.transform(xtrain).shape)##(354, 92) (354, 13)--->(354, 92)
print(poly.fit_transform(xtrain).shape)#(354, 92)
print(poly2.fit(xtrain))#PolynomialFeatures()
print(poly2.transform(xtrain).shape)#(354, 105) (354, 13)--->(354, 105)
print(poly2.fit_transform(xtrain).shape)#(354, 105)
print(poly3.fit(xtrain))#PolynomialFeatures(include_bias=False, interaction_only=True)
print(poly3.transform(xtrain).shape)#(354, 91) (354, 13)--->(354, 91) 没有x0=1这一项
print(poly3.fit_transform(xtrain).shape)#(354, 91)
x_train_poly=poly.fit_transform(xtrain)###得到了xtrain的预测值
x_test_poly=poly.fit_transform(xtest)###得到了xtest的预测值
print(type(x_train_poly))#<class 'numpy.ndarray'>
print(x_train_poly.shape)#(354, 92)
print(x_test_poly.shape)#(152, 92)
print(len(x_test_poly[0]))#92
print("---"*30)
##构建模型
linear=LinearRegression(fit_intercept=True)
lasso=Lasso(alpha=0.1,fit_intercept=True)##截距项b l1正则
ridge=Ridge(alpha=0.1,fit_intercept=True)##截距项b l2正则
"""
fit_intercept :
布尔类型,初始为True。决定在这个模型中是否有intercept,即偏移量,即类似于线性函数y = w1x1 + w0 中的w0。 如果False则无。
normalize:
布尔类型,初始为False。如果fit_intercept设置为False,那这个参数就会被忽略。反之,设为True,则模型在回归之前,会对特征集X减去平均数并除以L2范式(没懂),理解为一种标准化的规则。如果设为了False,而你又想标准化特征集合,则需要使用 sklearn.preprocessing.StandardScaler类来进行预处理。
copy_X:
布尔类型,初始化为True。True则,特征集合不变,反之会被复写。
n_jobs:
The number of jobs to use for the computation
初始为None,表示用1个处理器计算;-1代表所有处理器,只用于多个目标集问题的提速和大型问题。
2.3 属性
coef_:权重矩阵,理解为线性函数y = w1x1 + w0 中的W1
intercept_ :偏移量,理解为线性函数y = w1x1 + w0 中的W0
rank_: 特征矩阵的秩
singular_:特征矩阵的奇异值
"""
# 模型训练--fit训练模型参数
linear.fit(x_train_poly, ytrain)
lasso.fit(x_train_poly, ytrain)
ridge.fit(x_train_poly, ytrain)
print("="*50)
print(linear.coef_.shape)#(92,)
print(linear.intercept_)#5079837304.813356
print(lasso.coef_.shape)#(92,)
print(lasso.intercept_)#14.25982398796421
print(ridge.coef_.shape)#(92,)
print(ridge.intercept_)#-89.7858279511164
print("预测测试集"*30)
y_test_hat = linear.predict(x_test_poly)
y_test_hat = lasso.predict(x_test_poly)
y_test_hat = ridge.predict(x_test_poly)
print("-" * 100)
print(linear.score(x_train_poly, ytrain))#0.9360376865166864
print(linear.score(x_test_poly, ytest))#0.7890885829295062
print(lasso.score(x_train_poly, ytrain))#0.9068616853860628
print(lasso.score(x_test_poly, ytest))#0.704444988710448
print(ridge.score(x_train_poly, ytrain))#0.9355470033459335
print(ridge.score(x_test_poly, ytest))#0.7943193832839427
y_train_hat = linear.predict(x_train_poly)
y_train_hat = lasso.predict(x_train_poly)
y_train_hat = ridge.predict(x_train_poly)
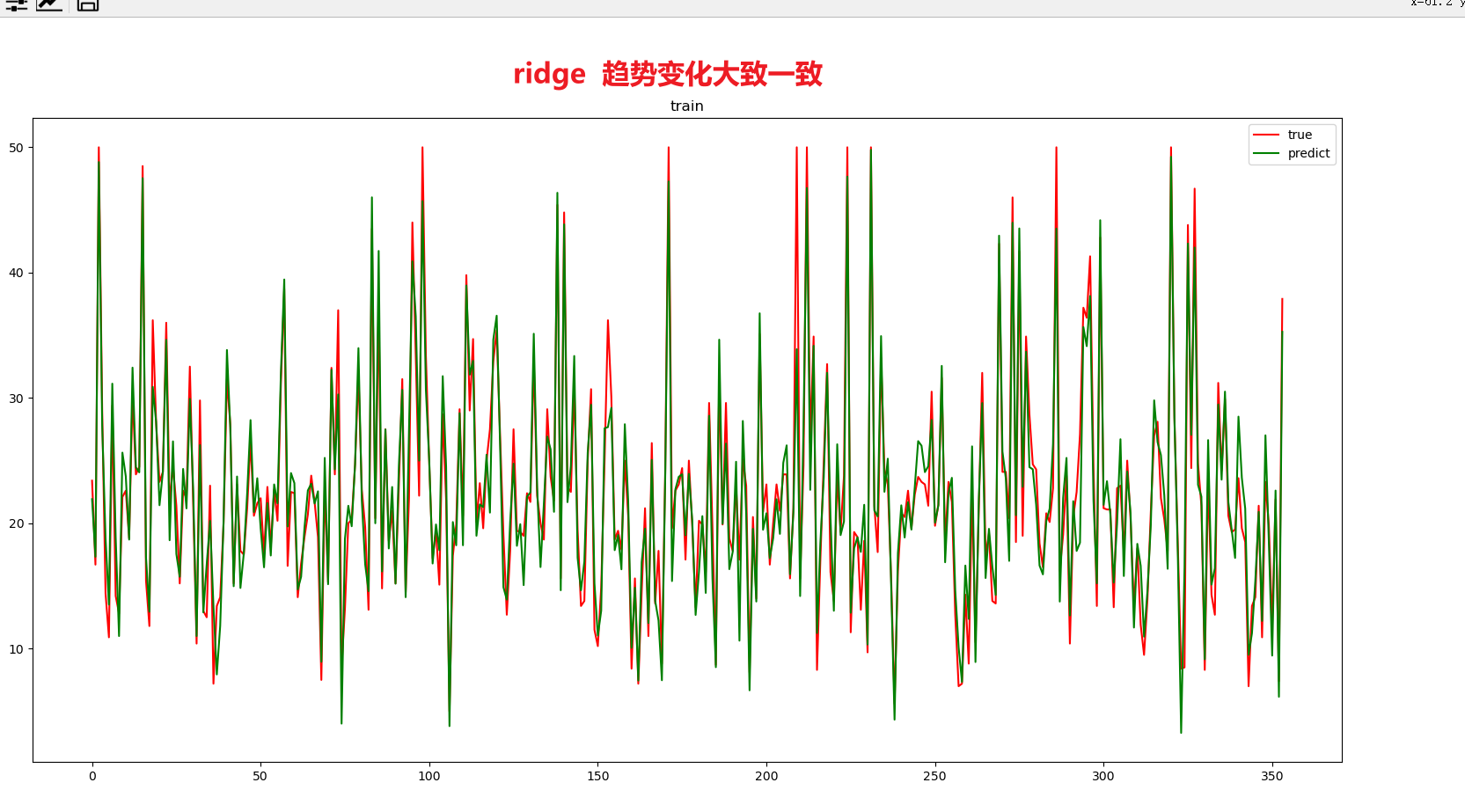
plt.figure(num="train")
plt.plot(range(len(xtrain)), ytrain, 'r', label=u'true')##ridge
plt.plot(range(len(xtrain)), y_train_hat, 'g', label=u'predict')
plt.legend(loc='upper right')
plt.title("train")
# plt.show()
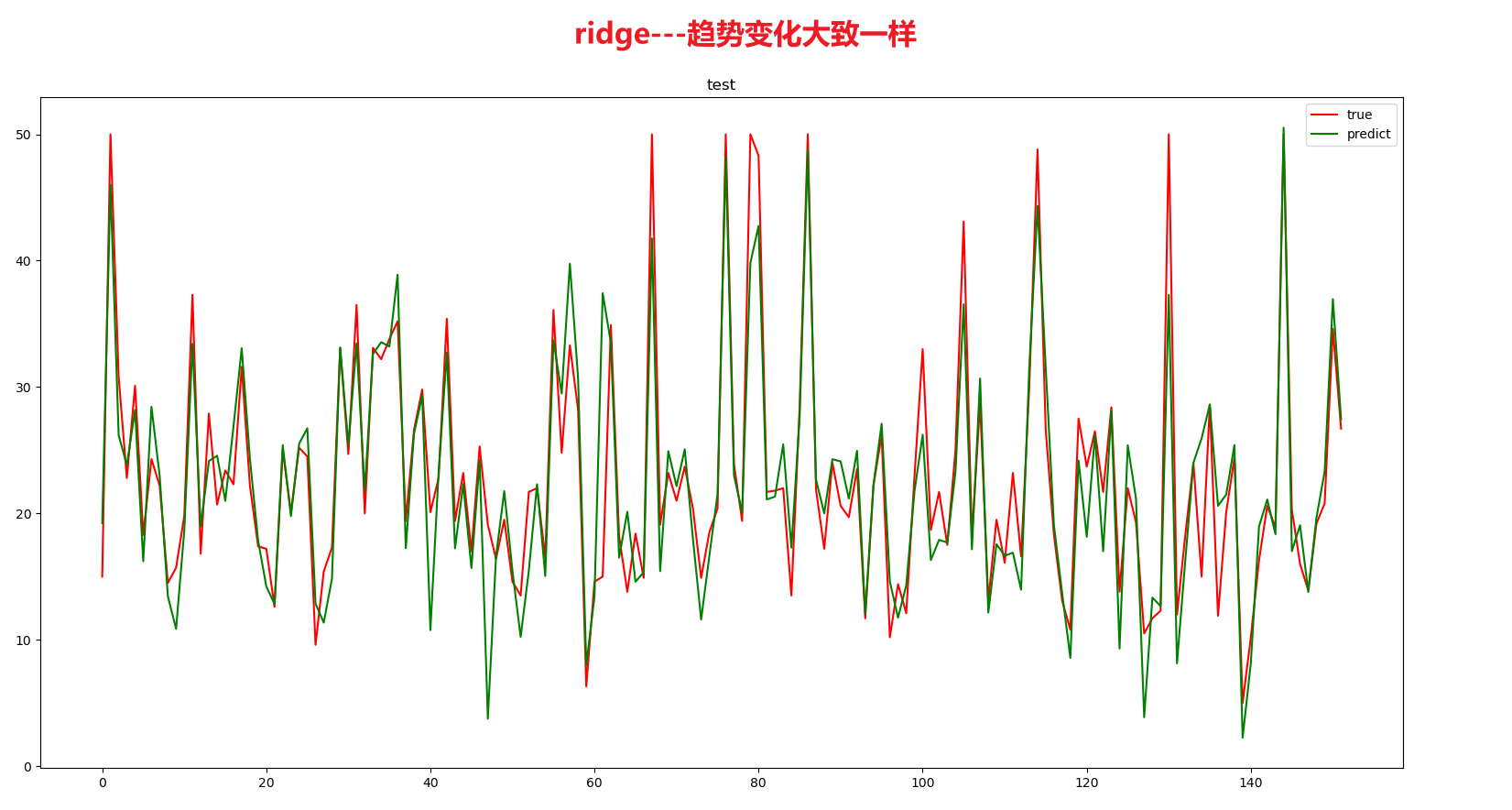
plt.figure(num="test")
plt.plot(range(len(xtest)), ytest, 'r', label=u'true')##ridge
plt.plot(range(len(xtest)), y_test_hat, 'g', label=u'predict')
plt.legend(loc='upper right')
plt.title("test")
plt.show()