论文
MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning
论文链接
MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning
模型结构
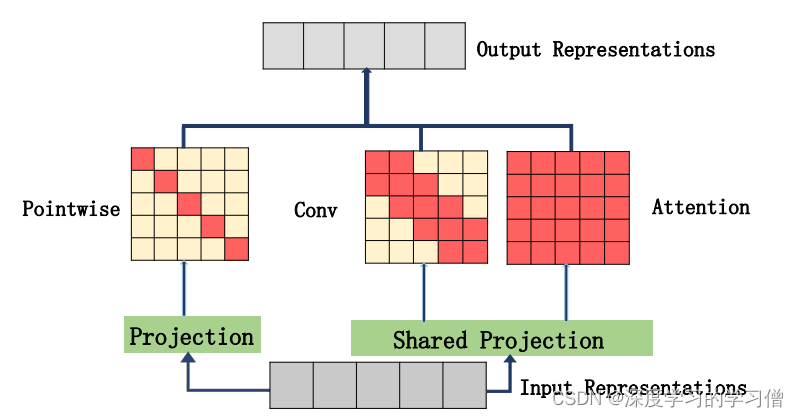
论文主要内容
在顺序学习中,自我注意机制被证明是非常有效的,并在许多任务中取得了显著的改善。然而,自我注意机制也并非没有缺陷。虽然自注意可以模拟极长的依赖关系,但深层的注意力往往过于集中在单一的表征上,导致对局部信息的充分利用,并难以表征长序列。在序列到序列学习中,如何同时捕捉输入序列的全局和局部上下文信息,并且在保证性能的前提下,减少计算量和内存消耗。作者提出了一种新颖的并行多尺度注意力机制,通过不同的尺度来捕捉输入的局部和全局上下文信息。本文提出了并行多尺度注意(MUSE)和MUSE-SIMPLE。MUSE模型采用了一种并行的多通道注意力机制,同时学习不同尺度的上下文表示。这种机制是通过对输入的不同子序列应用不同的卷积核来实现的,每个卷积核对应一个特定的上下文尺度。这种多通道卷积共享参数的设计,显著减少了计算和内存需求。
import numpy as np
import torch
from torch import nn
from torch.nn import init
# 定义深度可分离卷积
class Depth_Pointwise_Conv1d(nn.Module):
def __init__(self,in_ch,out_ch,k):
super().__init__()
# 如果 k=1,就返回输入
if(k==1):
self.depth_conv=nn.Identity()
else:
self.depth_conv=nn.Conv1d(
in_channels=in_ch,
out_channels=in_ch,
kernel_size=k,
groups=in_ch,
padding=k//2
)
self.pointwise_conv=nn.Conv1d(
in_channels=in_ch,
out_channels=out_ch,
kernel_size=1,
groups=1
)
def forward(self,x):
out=self.pointwise_conv(self.depth_conv(x))
return out
# 定义MUSEAttention模型
class MUSEAttention(nn.Module):
def __init__(self, d_model, d_k, d_v, h,dropout=.1):
super(MUSEAttention, self).__init__()
# 定义全连接层
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
# 定义深度可分离卷积层
self.conv1=Depth_Pointwise_Conv1d(h * d_v, d_model,1)
self.conv3=Depth_Pointwise_Conv1d(h * d_v, d_model,3)
self.conv5=Depth_Pointwise_Conv1d(h * d_v, d_model,5)
# 定义动态参数和softmax函数
self.dy_paras=nn.Parameter(torch.ones(3)) # 动态参数
self.softmax=nn.Softmax(-1) # softmax函数
# 定义模型参数
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
# 初始化参数
self.init_weights()
# 初始化权重
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
# 前向传播
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
# Self-Attention计算
b_s, nq = queries.shape[:2] # 图像尺寸
nk = keys.shape[1]
# 分别通过全连接层转换q,k,v
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
# 计算注意力权重
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att = torch.softmax(att, -1)
att=self.dropout(att)
# 计算输出
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
# 计算不同尺度的注意力分布
v2=v.permute(0,1,3,2).contiguous().view(b_s,-1,nk) #bs,dim,n
self.dy_paras=nn.Parameter(self.softmax(self.dy_paras))
out2=self.dy_paras[0]*self.conv1(v2)+self.dy_paras[1]*self.conv3(v2)+self.dy_paras[2]*self.conv5(v2)
out2=out2.permute(0,2,1) #bs.n.dim
# MUSE输出
out=out+out2
return out
# 测试模型
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
这段代码是MUSEAttention模型的实现,该模型由多个深度可分离卷积(Depthwise Separable Convolution)和Self-Attention组成,并使用动态权重控制不同范围(多个尺度)的序列特征。