点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文介绍我们在ICCV 2023上接收的论文《PointCLIP V2: Adapting CLIP for Powerful 3D Open-world Learning》。

论文:https://arxiv.org/abs/2211.11682
开源代码(已开源):
https://github.com/yangyangyang127/PointCLIP_V2
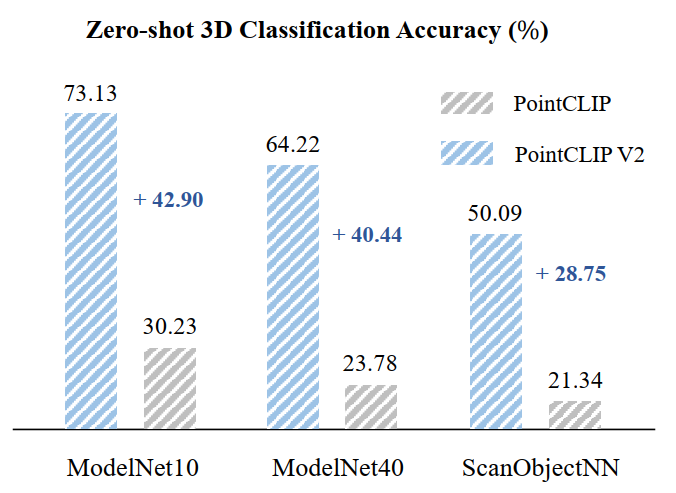
如下图,与baseline PointCLIP相比,本文方法在3个不同数据集的zero-shot分类准确率上,有了提升显著。
1. 概述
问题:当前,大规模数据预训练极大地提高了2D图像的open-world识别能力。但在3D领域,由于没有足够的可训练数据,各种3D open-world任务进展缓慢且性能较低如PointCLIP,所以提升3D open-world任务的性能是一个重要问题,这些任务包括zero-shot的分类,分割和检测等。
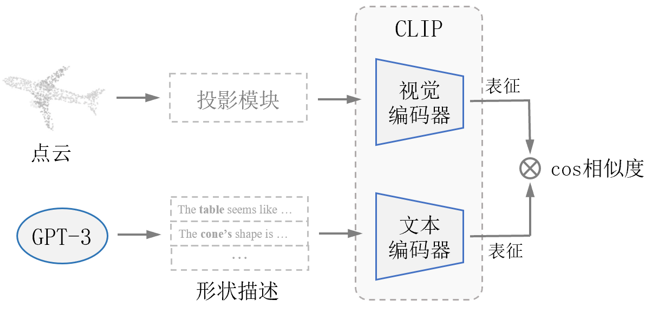
出发点:最近一段时间,大规模图像-文本预训练取得了较大的进步,比如CLIP,BLIP之于各种2D任务;同时大语言模型如GPT-3在文本理解上也有所突破。因此我们提问:是否能够结合图像文本模型和大语言模型来解决3D open-world任务?更具体地,能否实现CLIP + GPT-3 => 3D open-world tasks?
主要方法:为了结合两者,我们将3D点云投影成接近真实的2D图像,并使用GPT-3产生富含3D描述的文本,从而提升两种模态的匹配度。我们的实验证明,结合CLIP和GPT-3的方法,在3D open-world任务上取得了较好的性能,这些任务包括zero-shot和few-shot 3D classification,以及更一般的zero-shot 3D segmentation和3D detection任务。综上所述,论文的整体思路可以表示为下图:
2. 方法
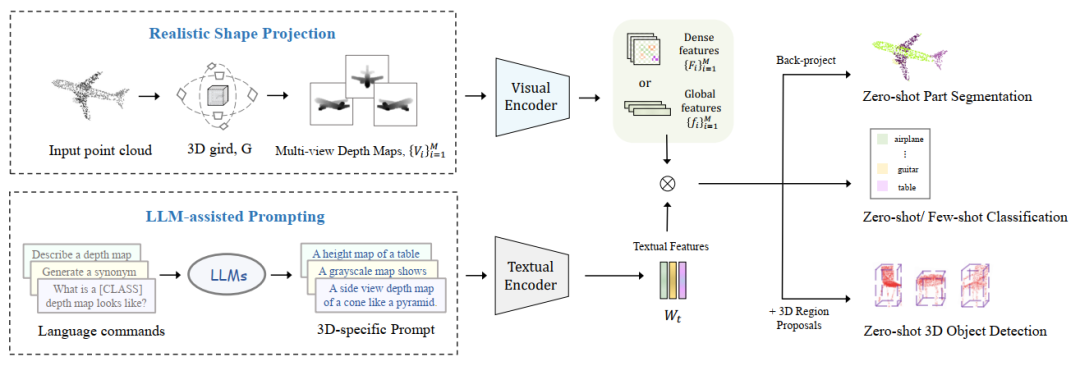
为了将点云适配到图像和文本,我们基于PointCLIP主要做了两点改进,这两点改进对应于CLIP的两个编码器:
(1) 对于视觉编码器,设计了新的投影模块将点云投影成更加真实的深度图;
(2) 对于文本编码器,使用GPT-3产生包含丰富形状描述的文本。
以上的两点改进虽然简单但能够用于不同的任务,我们在zero-shot和few-shot 3D classification,zero-shot 3D segmentation, 和3D detection任务上验证。综合以上,论文整体的框架如下图所示,输入部分(左边)是两点改进,输出部分(右边)对应于不同的任务。
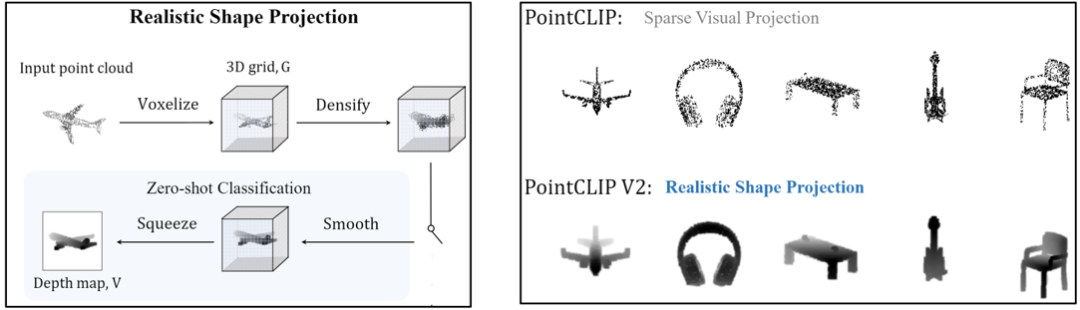
2.1 深度图合成
对于一个点云,我们主要通过量化(体素化),稠密化,平滑和维度压缩合成出一个比较贴近真实的深度图。首先一个不规则的点云被体素化,产生一个稀疏的3D网格,然后我们使用池化操作把网格变得稠密,接着我们使用高斯平滑消除噪声,最后在深度这个维度进行压缩,从3D网格得到一张2D图像。整体流程如下图左所示,最后的深度图与散点图相比,更加贴近现实中的深度图(图右)。
2.2 文本描述生成
大部分基于CLIP的工作都使用了形如“a photo of a {CLASS}.”的普通文本模板,这在一定程度上较为低效。考虑到当前大预言模型已经具有较强的文本生成能力,因此我们试图用GPT-3产生具有形状描述的prompt. 我们使用4种形式的命令激励GPT-3。(1)命令型,如:“Describe a depth map of a [window]:”;(2)疑问型,如:“How to describe a depth map of a [table]?”;(3)同义句,如:“Generate a synonym for the sentence: A grayscale depth map of an inclined [CLASS].”;(4)组词成句,如:“Make a sentence using these words: a [table], depth map, obscure.”。
使用GPT-3产生的文字描述能够与图像产生更好的匹配,如下图右的attention map所示。
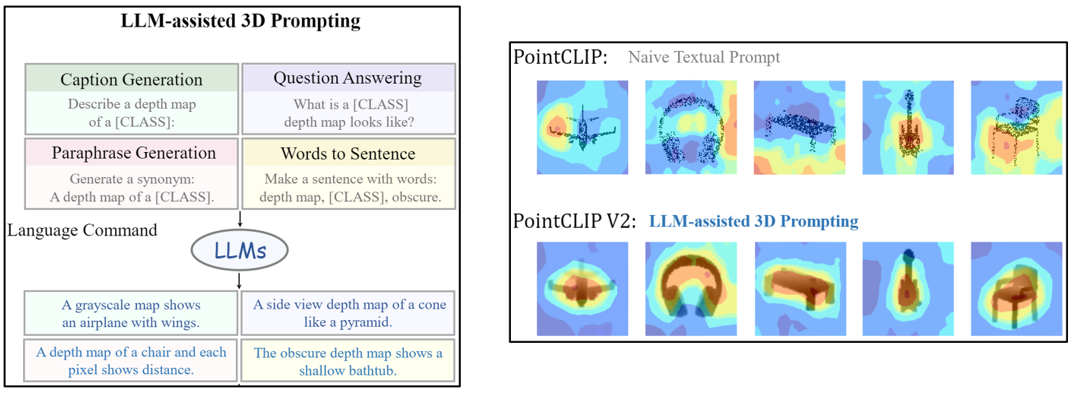
2.3 Open-world任务
我们将CLIP和GPT-3结合用于多种open-world的3D任务,包括3D zero-shot分类, 3D few-shot分类, 3D zero-shot segmentation和3D detection。
对于分割任务,我们在深度图上完成分割然后反映射到3D点云上,主要包括part segmentation和scene segmentation。对于检测任务,我们使用一个预训练的region proposal network产生3D框,并使用我们的方法作为一个open-world的分类头进行分类。
3. 结果
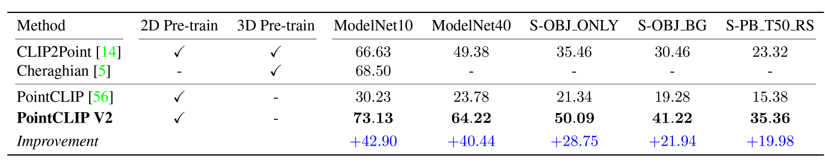
在ModelNet10, ModelNet40, ScanObjectNN的三个子数据集上的zero-shot分类结果在下表中,我们达到了当前的SOTA结果。
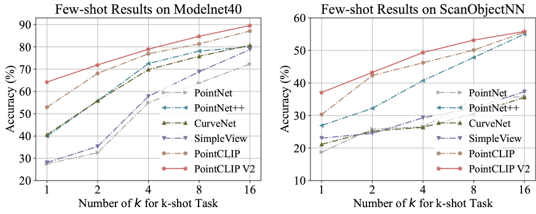
在ModelNet40和ScanObjectNN的三个子数据集上的few-shot分类结果,相比于之前的方法也获得了提升。
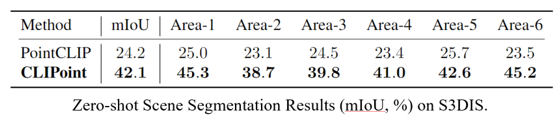
在zero-shot分割任务上,我们尝试了part和scene的分割,结果分别如下。因为当前没有类似的设定,因此我们只和PointCLIP做了比较。

在3D detection任务上,在ScanNet V2上的结果如下所示。

感谢您的阅读,更多的实现细节和比较请看我们的文章,我们的代码已开源。感谢您提出宝贵意见。
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集3D点云和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-3D点云或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如3D点云或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()