Python的网络爬虫框架-Scrapy爬虫框架的使用
一、前言
- 个人主页: ζ小菜鸡
- 大家好我是ζ小菜鸡,让我们一起来学习Python的网络爬虫框架-Scrapy爬虫框架的使用
- 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)
二、搭建 Scrapy 爬虫框架
由于Scrapy爬虫框架依赖的库比较多,尤其是Windows系统下,至少需要依赖的库有Twisted、lxml、PyOpenSSL以及pywin32。搭建Scrapy爬虫框架的具体步骤如下:
1.安装Twisted模块
(1)打开 https://pypi.org/project/Twisted/#files 网址,如下图所示:

(2)下载 Twisted模块文件,如下图所示:
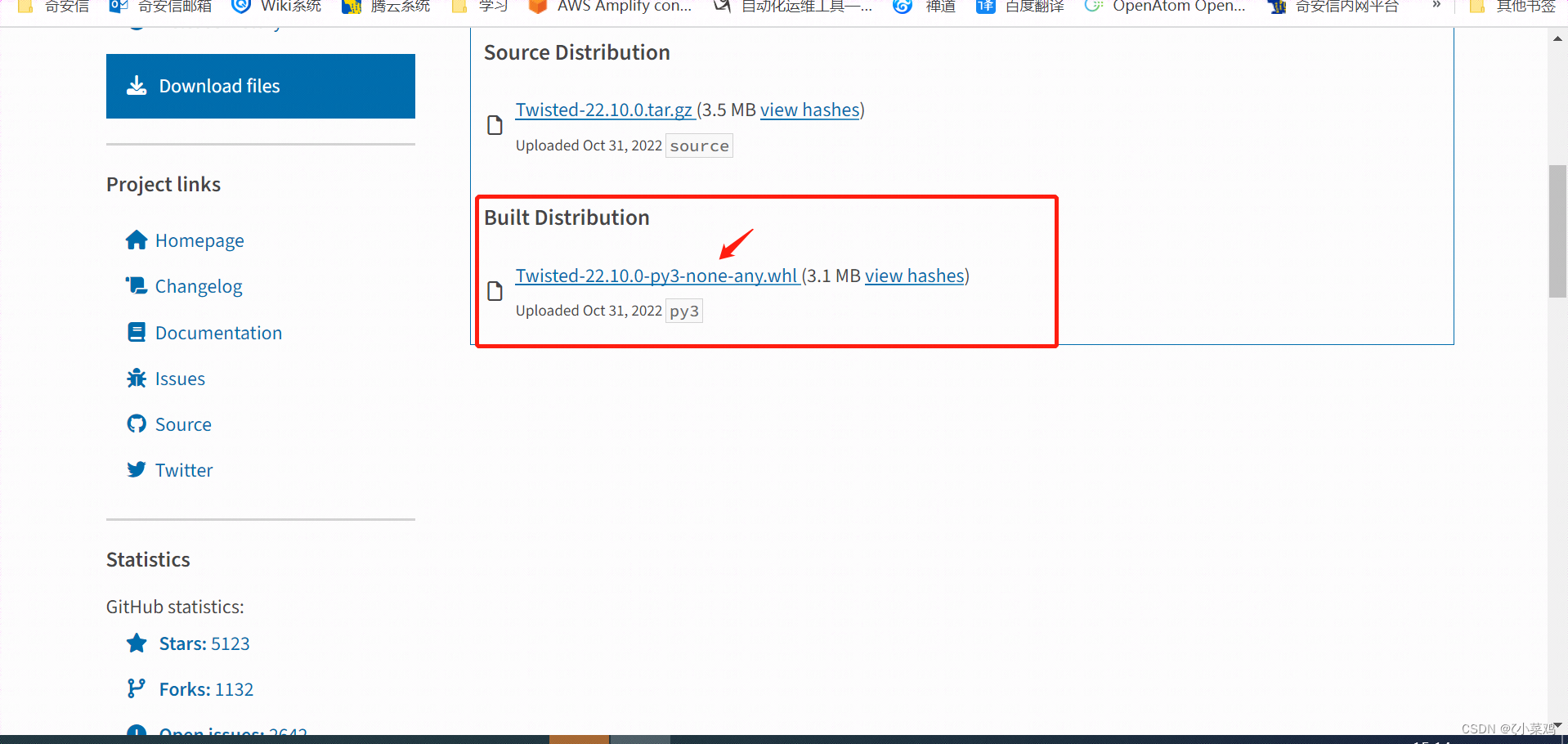
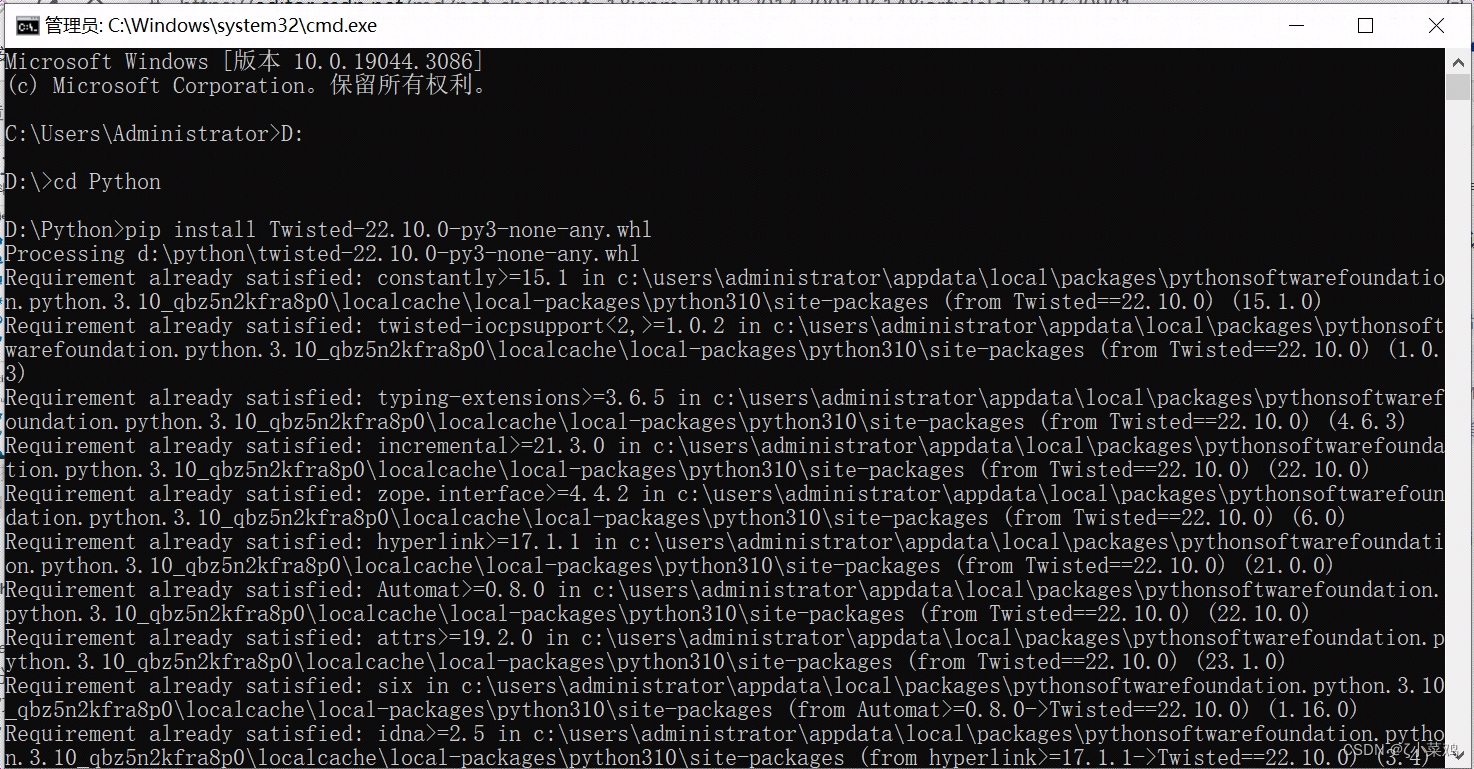
(3)“Twisted-22.10.0-py3-none-any.whl”二进制文件下载完成后,以管理员身份运行命令提示符窗口,然后使用cd命令打开“Twisted-22.10.0-py3-none-any.whl”文件所在的路径,最后在窗口输入“pip install Twisted-22.10.0-py3-none-any.whl”,安装Twisted模块,如图下图所示:
2.安装 Scrapy 框架
(1)打开命令行窗口,然后所输入“pip install Scrapy”命令,安装 Scrapy 框架,如下图所示:

(2)完成安装以后在命令行中输入“scrapy”的页面,如果没有出现异常信息或错误信息,则表示 Scrapy 框架安装成功。如下图所示:
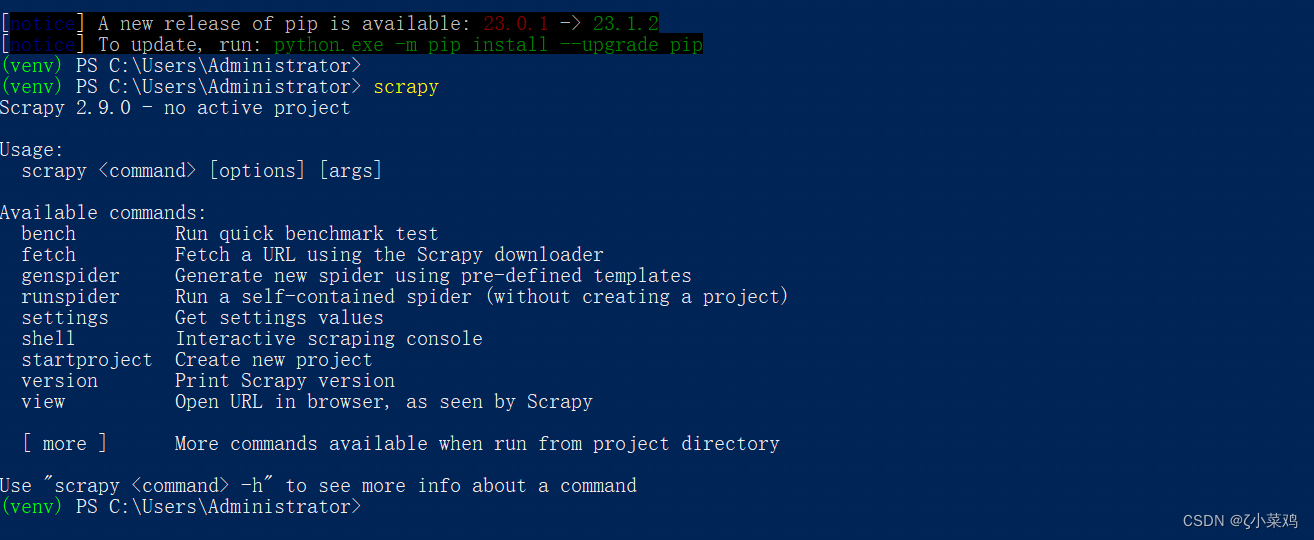
说明: Scrapy 框架安装过程中,同时会将 lxml 模块与 pyOpenSSL 模块也安装在Python环境中。
3. 安装pywin32模块
在打开命令窗口,然后输入“pip install pywin32”,如果没有提示错误信息,则表示安装成功。
三、创建Scrapy 项目
在任意路径下创建项目文件夹,例如,在“D:\python”文件夹内运行命令行窗口,然后输入“scrapy startproject scrapyDemo”即可创建一个名称为“scrapyDemo”的项目,如下图所示:
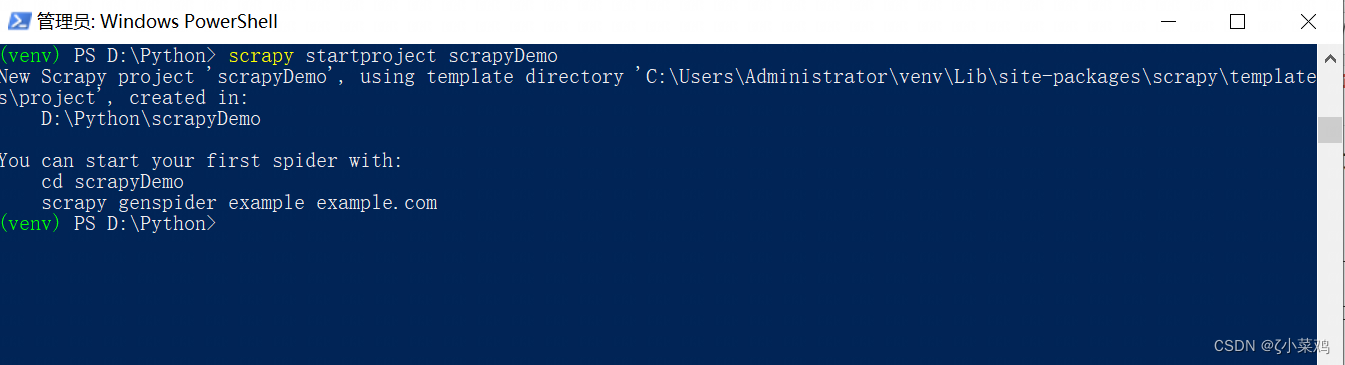
为了提升开发者效率,小菜鸡使用PyCharm 第三方开发工具,打开刚刚创建的 scrapyDemo 的项目,项目打开完成后,在左侧项目的目录结构中可以看到如下图所示的内容:
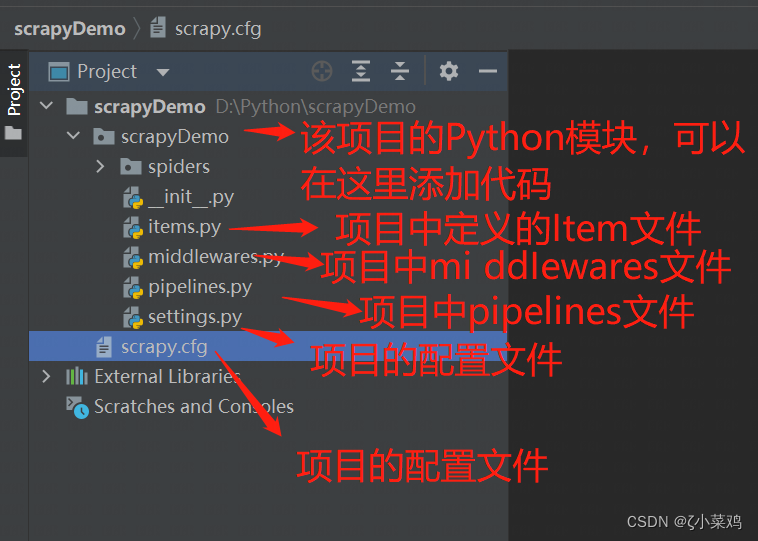
四、创建爬虫
在创建爬虫时,首先需要创建一个爬虫模块的文件,该文件需要放置在spiders 文件夹当中。爬虫模块是用于从一个网站或多个网站爬取数据的类,它需要继承 scrapy.Spider 类,下面通过一个爬虫示例,实现爬取网页的代码以HTML 文件保存至项目文件夹中,示例代码如下:
import scrapy # 导入框架
class QuotesSpider(scrapy.Spider):
name = "quotes" # 定义爬虫名称
def start_requests(self):
# 设置爬取目标的地址
urls = [
"http://quotes.toscrape.com/page/1/",
"http://quotes.toscrape.com/page/2/",
]
# 获取所有地址,有几个地址发送几次请求
for url in urls:
# 发送网络请求
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 获取网页
page = response.url.split("/")[-2]
# 根据页面数据设置文件名称
filename = "quotes-%s.html" % page
# 写入文件的模式打开文件,如果没有该文件将创建该文件
with open(filename, "wb") as f:
f.write(response.body)
# 输出保存文件的名称
self.log("Saved file %s" % filename)
在运行Scrapy 所创建的爬虫项目时,需要在命令窗口中输入“scrapy crawl quotes”,其中“quotes”是自己定义的爬虫名称。由于小菜鸡使用的是PyCharm第三方开发工具,所以需要在底部的“Terminal”窗口中输入运行爬虫的命令行,运行完以后显示下图所示信息:
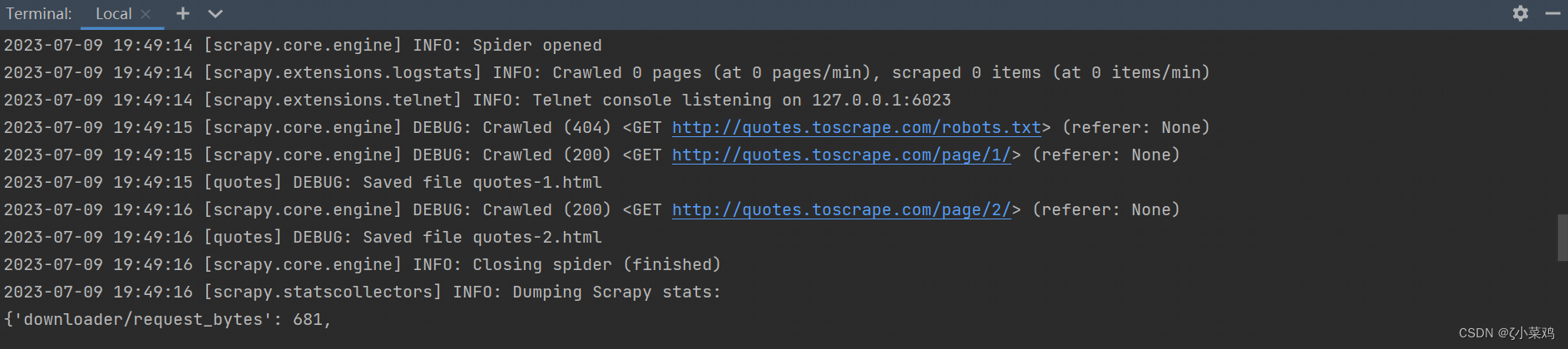
说明: 除了使用在命令窗口中输入命令“scrapy crawl quotes”以外,Scrapy 还提供了可以在程序中启动爬虫的API,也就是CrawlerProcess 类。首先需要在CrawlerProcess 初始化时传入项目的setting信息,然后在crawl() 方法中传入爬虫的名称,最后通过start()方法启动爬虫。代码如下:
# 导入CrawlerProcess类
from scrapy.crawler import CrawlerProcess
# 获取项目配置信息
from scrapy.utils.project import get_project_settings
# 程序入口
if __name__ == "__main__":
# 创建CrawlerProcess类对象并传入项目设置信息参数
process = CrawlerProcess(get_project_settings())
# 设置需要启动的爬虫名称
process.crawl("quotes")
# 启动爬虫
process.start()
五、获取数据
Scrapy 爬虫框架,可以通过特定的CSS或者Xpath表达式来选择HTML文件中的某一处,并且提取出相应的数据。CSS,用于控制HTML页面布局、字体、颜色、背景以及其他效果。Xpath是一门可以在XML文档中,根据元素和属性查找信息的语言。
1.CSS提取数据
使用CSS提取HTML 文件中的某一处数据时,可以指定HTML文件中的标签名称,例如,获取上面示例中网页的title 标签代码时,可以使用如下代码:
response.css("title").extract()
获取结果如图所示:
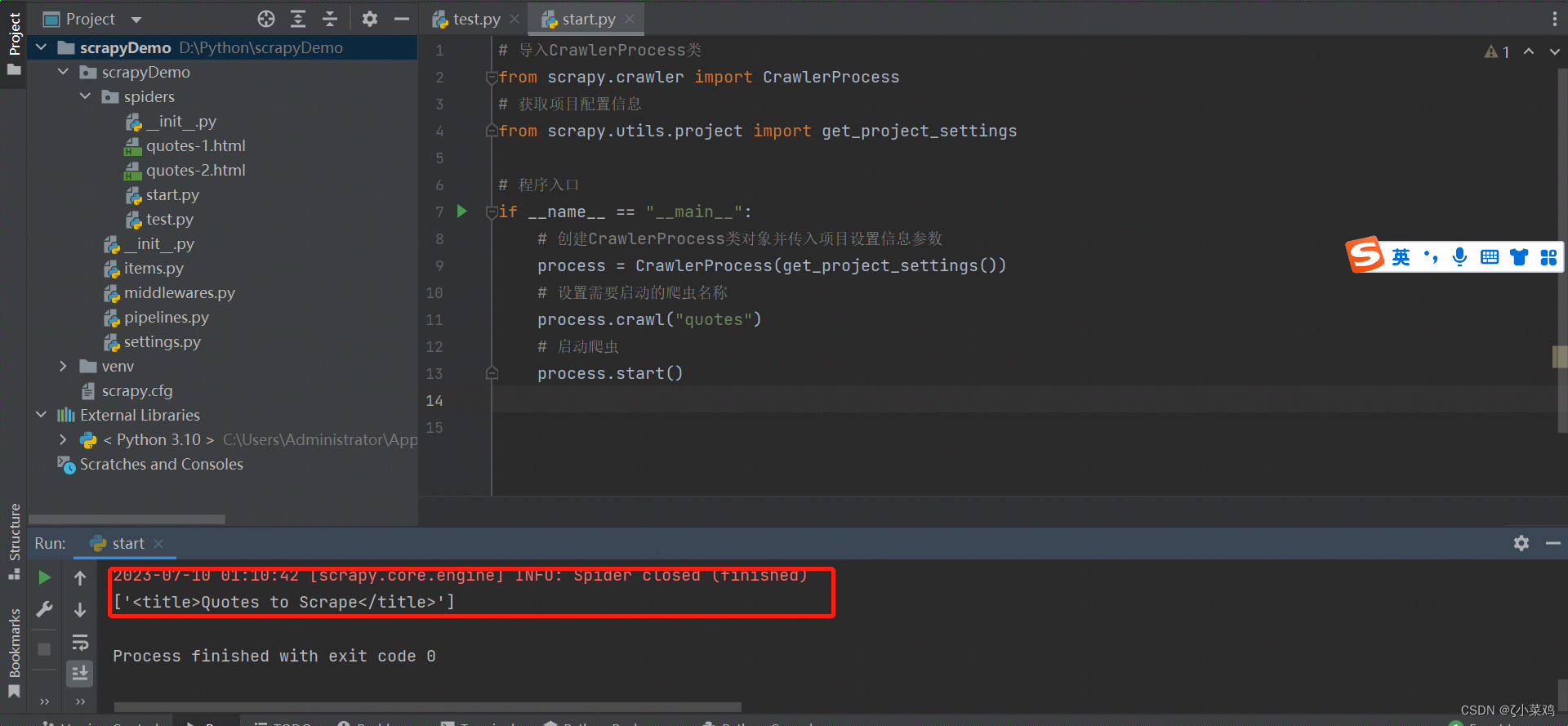
说明: 返回内容为CSS表达式所对应节点的list列表,所以在提取标签中的数据时,可以使用以下的代码:
response.css("title::text").extract_first()
或者是
response.css("title")[0].extract()
2.XPath 提取数据
使用Xpath表达式提取HTML文件中的某一处数据时,需要根据Xpath表达式的语法规定来获取指定的数据信息,例如,同样获取title标签内的信息时,可以使用以下代码:
response.xpath("//title/text()").extract_first()
下面通过一个示例,实现使用Xpath表达式获取上面示例中的多条信息,示例代码如下:
def parse(self, response):
# 获取信息
for quote in response.xpath(".//*[@class='quote']"):
# 获取名人名言文字信息
text = quote.xpath(".//*[@class='text']/text()").extract_first()
# 获取作者
author = quote.xpath(".//*[@class='author']/text()").extract_first()
# 获取标签
tags = quote.xpath(".//*[@class='tag']/text()").extract()
# 以字典的形式输出信息
print(dict(text=text, author=author, tags=tags))
3.翻页提取数据
以上的示例中已经实现了获取网页中的数据,如果需要获取整个网页的所有信息就需要使用翻页功能。例如,获取上面示例中整个网站的作者名称,可以使用以下代码:
# 响应信息
def parse(self, response):
# div.quote
# 获取所有信息
for quote in response.xpath(".//*[@class='quote']"):
# 获取作者
author = quote.xpath(".//*[@class='author']/text()").extract_first()
print(author) # 输出作者名称
# 实现翻页
for href in response.css("li.next a::attr(href)"):
yield response.follow(href, self.parse)
4.创建Items
在爬取网页数据的过程中,就是从非结构性的数据源中提取结构性数据。例如,在QuotesSpider类的parse()方法中以获取到可text、author以及tags信息,如果需要将这些数据包装成结构化数据,那么就需要scrapy所提供的Item类来满足这样的需求。Item对象是一个简单的容器,用于保存爬取的到的数据信息,它提供了一个类似于字典的API,用于声明其可用字段的便捷语法。Item使用简单的类定义语法和Field对象来声明。在创建scrapyDemo项目时,项目的目录结构中就已自动创建了一个items.py文件,用来定义存储数据信息的Item类,它需要继承scrapy.Item。示例代码如下:
import scrapy
class ScrapydemoItem(scrapy.Item):
# define the fields for your item here like:
# 定义获取名人名言文字信息
text = scrapy.Field()
# 定义获取的作者
author = scrapy.Field()
# 定义获取的标签
tags = scrapy.Field()
pass
Item创建完成以后,回到自己编写的爬虫代码中,在parse()方法中创建Item对象,然后输出item信息,代码如下:
def parse(self, response):
# 获取信息
for quote in response.xpath(".//*[@class='quote']"):
# 获取名人名言文字信息
text = quote.xpath(".//*[@class='text']/text()").extract_first()
# 获取作者
author = quote.xpath(".//*[@class='author']/text()").extract_first()
# 获取标签
tags = quote.xpath(".//*[@class='tag']/text()").extract()
# 以字典的形式输出信息
item = ScrapydemoItem(text=text, author=author, tags=tags)
yield item # 输出信息
说明: 由于Scrapy爬虫框架内容较多,这里仅简单介绍了该爬虫框架的安装、创建爬虫已经数据提取,详细教程可以登录 ( https://docs.scrapy.org/en/latest/) Scrapy 官方文档进行查询。
Python的网络爬虫框架-Scrapy爬虫框架的使用的介绍,到此就结束了,感谢大家阅读,如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)