A Survey On Few-shot Knowledge Graph Completion with Structural and Commonsense Knowledge
标题:基于结构知识和常识知识的Few-Shot知识图补全研究综述
链接:https://arxiv.org/abs/2301.01172
作者:Haodi Ma,Daisy Zhe Wang
机构: University of Florida
一、摘要:
知识图已经成为各种自然语言处理应用的关键组成部分。常识知识图(CKG)是一种特殊类型的KG,其中的实体和关系由自由形式的文本组成。然而,以往的KG完备化和CKG完备化工作都存在长尾关系和新增关系,没有太多的已知三元组可供训练。有鉴于此,为了解决标注数据有限的问题,提出了需要图表示学习和少镜头学习的优点的Few-Shot KG补全(FKGC)。在本文中,我们以一系列方法和应用的形式全面综述了以前在这类任务上的尝试。具体来说,我们首先介绍FKGC挑战、常用KG和CKG。然后从知识几何的类型和方法两个方面对已有的研究成果进行了系统的分类和总结。最后,介绍了FKGC模型在不同领域预测任务中的应用,并对FKGC未来的研究方向进行了展望。
二、简介:
当今的大规模 KG 中存储了大量信息,但它们非常不完整,这使得知识图谱补全 (KGC) 对其下游应用程序构成了挑战。最近的趋势旨在学习实体的低维表示和缺失链接预测的关系 [(Bordes 等人,2013 年;Trouillon 等人,2016 年;Dettmers 等人,2017 年)]。这些方法的总体思路是根据 KG 中的已知事实对实体之间的各种关系模式进行建模和推理。例如,TransE 将关系建模为翻译,针对反转和组合模式。旋转作为一个代表,可以推断出对称、不对称、反转和合成模式。
然而,此类方法通常需要足够的训练三元组来让所有关系学习嵌入。以前的作品 [78] 表明,很大一部分 KG 关系是长尾的。例如,例如,维基数据中约 10% 的关系不超过 10 个三元组。此外,现实世界的 KGs 通常是动态的,这意味着每当获得新知识时都会添加新的关系和实体。为了应对这些挑战,该模型应该能够仅在少量示例的情况下预测新的三元组。
为了应对上述挑战,提出了两个基准,NELL-One 和 Wiki-One,用于少样本知识图完成(FKGC)和称为 GMatching 的基线模型。该模型引入了一个本地邻居编码器来学习昂贵的实体表示,每个查询关系只有几个样本。最近作品的一个分支遵循类似的方法,通过考虑局部图邻居来提高嵌入质量,从而取得了可观的性能。他们进一步争辩说,实体邻居应该具有与不同任务关系相关的不同影响。由于关系可以是多义的,参考三元组也应该对特定查询做出不同的贡献。例如,如果任务关系是 isPartOf,如图 1 所示,则这种关系具有不同的含义,例如,组织相关的(利物浦,isPartOf,英超联赛)或位置相关的(盖恩斯维尔,isPartOf,佛罗里达州) .显然,对于查询 (Dallas, isPartOf, Taxes),与位置相关的引用应该比其他引用更有影响力。这些模型 [43、54] 建议使用注意力网络来捕获实体和引用的动态属性。

FKGC 模型的另一个轨道是基于模型不可知元学习 (MAML) 开发的。
这些模型利用元学习来学习实体和关系的表达嵌入的学习过程,只有少数实例。特别是,他们使用训练集中的高频关系来捕获元信息,其中包括跨不同任务关系的共同特征。通过元信息提供的良好参数初始化,这些模型可以快速适应测试任务,其中每个任务关系只提供少量的几个实例。
另一方面,作为一种特殊类型的知识图谱,如 ATOMIC 和 ConceptNet等常识知识图谱 (CKG),其中实体和关系由自由格式的文本组成,很少受到基于嵌入的模型的关注. CKG 是动态的,因为不断引入具有看不见的文本的实体,这使它们成为 FKGC 的自然基准。此外,CKG 中的实体和属性通常是自由格式的文本。如图 3 所示,不同于一般的 KGs 具有结构化的实体和关系名称,CKGs 中的实体描述具有丰富的语义含义,隐含的语义关系可以直接推断常识知识,但这种特性也使得 CKGs 与general KGs,因为引用相同概念的实体可以是不同的节点。如[67]所示,与FB15K-237相比,ConceptNet和ATOMIC的平均入度仅为1/15和1/8。由于 CKG 不能完全适合比较具有关系的两个实体的模式,因此基于嵌入的方法仅限于捕获隐含的常识性知识。
同时,最近在训练基于 transformer 的上下文语言模型方面取得的进展激发了人们对使用语言模型 (LM) 作为知识库的兴趣。例如,最近的工作侧重于使用提示查询 LM(例如,“Beatles was formed in __”)。 COMET是一种基于 transformer 的 KG 完成模型,经过训练可以预测头部实体上看不见的尾部实体条件和 ATOMIC 上的关系。 BertNet更进一步,通过自动解释 FKGC/KGC 任务的初始提示,直接从预训练语言模型中提取未见实体的三元组。
最后,在本次研究中,我们涵盖了 FKGC 模型在数据科学、视觉提取和医学社区中的典型应用。我们根据观察到的当前模型的弱点,进一步讨论了 FKGC 在一般知识图谱和常识知识图谱上的未来研究方向。
三、 预文:
在本节中,我们首先回顾不同的 KG。然后我们正式定义知识图补全和少样本知识图补全。在本节的最后部分,我们简要介绍了 FKGC 任务中广泛使用的少样本学习和元学习。
3.1 知识图谱
设E和R表示实体和关系的集合,知识图G = {(푒푖, 푟푘, 푒푗 )} ⊂ E × R × E 是事实三元组的集合,其中E表示实体的集合, R 是关系集; 푒푖 和 푟푘 分别是第 푖 个实体和第 푘 个关系。我们通常将푒푖和푒푗称为头尾实体。知识图也可以表示为 X ∈ {0, 1} | E|×| R |×| E |,称为G的邻接张量。当三元组(푒푖, 푟푘, 푒푗)为真时,(푖, 푗, 푘)项X푖,푘,푗 = 1,否则X푖,푘,푗 = 0 . 表 1 2.1.1 结构化知识图显示了常用 KG 的列表及其来源、大小和示例。
如前所述,以前的工作倾向于提取半结构化文本来构建知识图谱。这些知识图谱通常通过众包构建或从众包中提取。
Freebase 是一个众包策划的 KG,于 2008 年首次推出,并已被用作许多任务的标准基线 KG,包括 KG 完成。 Freebase 的最新和完整版本包含大约 30 亿个三元组和大约 5000 万个实体 1。广泛使用的 Freebase 子集 FB15K-237 从 Freebase 中排除逆关系,包括 14541 个实体、237 个关系、和 272,155 个训练三元组。 Freebase 中包含的关系是分层的,它们形成了定义明确的实体和关系空间,激发了嵌入模型的线程。
维基数据也是一个众包 KG,包含大约 7800 万个数据项,约 23000 种类型和 1600 种关系。从一开始,它就被设计成一种管理维基百科信息的替代方法。除了提供事实信息外,维基数据还通过存储其来源提供事实的上下文。截至 2014 年,维基数据支持 287 种语言 。 2014 年,谷歌将存储在 Freebase 中的数据转移到维基数据中 。维基数据中的实体和关系是通过属性值对来描述的; YAGO。 YAGO 是一个从维基百科自动构建的大型知识库。知识图谱将来自维基百科的 10 种不同语言的信息组合成一个整体,以提供知识的多语言维度。它还将空间和时间信息附加到许多事实,从而允许用户查询空间和时间上的数据。 YAGO 从 Wikipedia 构建,继承了 Wikipedia 的层次结构,并为实体和关系使用结构文本。 YAGO存在多个迭代版本,包括YAGO2和YAGO3。YAGO3 包含 8700 万个事实、1080 万个实体和 7600 万个关键字。
3.1.2 常识性知识图谱
常识知识图谱是指为下游应用组织常识或特定领域的知识。尽管现有的 CKG通常也是由人类众包构建的,但它们对实体使用自由格式的文本。
ATOMIC 数据集包含 877K 个元组,涵盖了围绕特定事件提示(例如,“X 去商店”)的各种常识性社会知识。 ATOMIC 包含以 if-then 关系组织的日常常识性知识实体。它总共包含超过 300K 个实体,实体由平均 4.4 个单词的文本描述组成。具体来说,ATOMIC 在 9 个维度中提炼其常识,涵盖事件的原因(例如,“X 需要开车到那里”)、它对代理的影响(例如,“去拿食物”)以及它对其他直接(或隐含的)参与者的影响(例如,“其他人将被喂食”)。
ConceptNet 是一种多语言知识图谱,它将自然语言的单词和短语与标记边连接起来。它的知识是从许多来源收集的,包括专家创建的资源、众包和有目的的游戏。它代表了使用不同语言的单词和短语来理解语言所涉及的一般知识。这样的“概念”可以帮助自然语言应用程序更好地理解人们使用的词语背后的含义。 ConceptNet 包含这些概念之间超过 1300 万个链接。
Visual Genome 不仅使用自然语言资源,还从图像中收集常识知识。它收集对象、属性和与每个图像的关系的密集注释以构建知识。具体来说,Visual Genome 总共包含超过 10 万张图像,每张图像平均有 21 个对象、18 个属性和对象之间的 18 种关系。由于对象、属性和关系是从图像中提取的,因此数据集使用 WordNet [41] 同义词集对它们进行分类。在本节中,我们首先回顾不同的 KG。然后我们正式定义知识图补全和少样本知识图补全。在本节的最后部分,我们简要介绍了 FKGC 任务中广泛使用的少样本学习和元学习。

3.2 Few-shot Knowledge Graph Completion
3.2.1 Knowledge Graph Completion
知识图补全 (KGC) 的目标是预测 G 中有效但未观察到的三元组。正式地,给定一个头实体 ei (尾实体 ej )与 rk 的关系,模型期望找到尾实体 ej (头实体 ei )在 G 中形成最合理的三元组 (푒푖, 푟푘, 푒푗)。KGC 模型通常定义一个评分函数 푓: E × R × E → R 来为每个三元组 ( ei , rk , ej ) ∈ E × R × E 表示三元组的合理性。
3.2.2 知识图谱嵌入
知识图谱嵌入 (KGE) 建议将实体和关系投射到可以用高维向量建模的定义明确的空间中。知识嵌入 (KGE) 模型通常将每个实体 ei 和关系 rj 与嵌入空间中的向量表示 ei、rj相关联。然后他们定义了一个评分函数来模拟实体和关系之间的交互。
KGE 模型一般可分为平移模型和双线性模型。翻译模型的代表是 TransE ,它将实体之间的关系建模为它们嵌入之间的差异。这种方法在推断组合、反对称和反转模式方面很有效,但不能处理 1-to-N, N-to-1, 和 N-N 关系。 RotatE 将关系建模为复杂空间中的旋转,以便可以捕获对称关系,但在其他方面与 TransE 一样有限。 ComplEx 作为双线性模型的代表,引入了一个具有复数的对角矩阵来捕获反对称性。其他模型,如 BoxE 和 HAKE ,可以用复杂的 KG 嵌入表达多种类型的关系模式。
3.2.3 图神经网络模型
近年来,图神经网络 (GNN) 在 KGC 任务上获得了广泛关注。凭借 GNN 的高表现力,这些方法表现出了良好的性能。然而,与 KGE 模型相比,基于 SOTA GNN 的模型并没有显示出很大的优势,同时引入了额外的计算复杂性 。例如,NBFNet 和 RED-GNN 在 KGC 基准测试中取得了有竞争力的性能,但是需要通过整个知识图传播的 Bellman-Ford 算法的杠杆作用限制了它们在大图上的应用。
3.2.4 小样本学习
Few-shot Learning (FSL) 侧重于从现有任务中学习可迁移的一般先验知识,以用于具有有限标记数据的新任务。它通常采用元学习框架,将整个任务视为训练示例,以便模型可以快速适应新任务。具体来说,给定一组任务 T 及其训练数据,在元训练阶段,模型的目标是学习对 T 中所有任务有效的全局参数 Θ′ :

其中 p(T ) 是任务分布; DTi 是任务T〉的训练数据; L是下游任务的损失函数。然后在元测试阶段, θ *被作为初始化参数(先验知识)快速适应新任务 Tj :
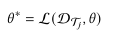
其中 Tj只有有限的标记数据。以前的 FSL 方法通常可以分为 (1) 基于度量的方法,利用特定于任务的相似性度量从支持集数据泛化到查询数据; (2) 基于优化的方法,旨在找到对任务变化敏感的模型参数,以便基础学习器可以通过少量梯度更新快速适应新的少样本任务。
3.2.5 小样本知识图补全
继 KGC 和 FSL 的定义之后,我们现在正式定义少样本知识图补全(FKGC)。
考虑一个知识图谱 G = {(ℎ, r, t)} ⊂ E × R × E 是事实三元组的集合,其中 E 代表实体集,R 是关系集。给定关系 r ∈ R 及其支持集 Sr = {( hk , tk )|(hk, r, tk) ∈ T },,任务是用尾实体完成三元组 (ℎ, r, t) ,t ∈ E 缺失。换句话说,模型需要从给定 (ℎ, r) 的候选实体集 C 中预测出t 。当 | Sr | = K 和 K 非常少,这个任务叫做 K-shot KG 完成。一个极端的情况是当 k = 0 时,这意味着没有支持的三元组。这样的任务也称为归纳 KGC、零样本 KGC 或图外 KGC,其中模型需要预测不可见实体的正确关系。
few-shot KGC 模型旨在将真实实体的排名高于虚假候选实体。在 FKGC 中,每个训练任务对应一个关系 r ∈ R 及其自己的支持/查询实体对,即 Tr = { Sr , Qr }。如前所述,S 包含 K-shot 支持实体对。 Qr = {( hm , tm )/ Chm ,r} 由所有查询和相应的候选 Chm ,r 组成,它们是根据实体类型约束选择的。我们进一步将训练中的所有任务表示为元训练集 Tmeta−training。
在元训练集上训练后,将通过预测新关系r ′ ∈ R′ 的事实来测试小样本学习模型。从元训练集中看不到测试关系,即 R ∪ R′ = ∅。测试阶段的每个关系也有它的小样本支持和查询集: Tr ′ = { Sr ′, Qr ′},与元训练中的定义类似。我们将测试中的所有任务表示为元测试集 Tmeta−testing。该模型还可以访问背景 KG G′,它是 G 的子集,具有所有关系,而不是Tmeta−training 和 Tmeta−testing中的关系。
四、 FKGC 模型
通常,具有结构知识的 FKGC 模型将 KGC 模型与用于各种应用的少样本学习相结合。除了 KGE 模型之外,基于 GNN 的方法在 FKGC 中也显示出有竞争力的性能,因为在每个 few-shot 任务的支持集中只提供了有限的标记数据。另一方面,利用语义特征的模型利用提示来组合结构和语义信息。
FKGC 任务 存在三个主要挑战:
• (1) 如何在少样本设置中学习三元组中最具代表性的信息?一般的机器学习算法需要大量的数据进行模型训练,而在few-shot场景下只有很少的参考数据。从有限的三元组中学习不同关系的代表性模式成为解决 FKGC 问题的关键。
• (2) 如何减少对背景幼儿园的过度依赖?大多数先前的小样本方法依赖于背景 KG 来访问来自实体邻域的信息或预训练实体嵌入。最近的一些模型认为,并不总是可以访问完整的背景知识图谱,并且将其存储在内存中也很耗费空间。
• (3) 如何利用负样本提升模型效能?最直观的匹配方法通常比较query和positive references之间的相似性,而忽略query和negative references之间的相似性,这可以提高triplet validity测量的准确性。
在本节中,我们系统地将最近的具有结构知识的 FKGC 模型分为基于度量的方法和基于优化的方法,这取决于它们如何采用 FSL 技术以及它们如何解决上述三个问题。然后我们从基于提示的结构模型转向利用预训练语言模型的结构模型。表 2 中提供了具有代表性的 FKGC 列表及其开源数据集/代码。

4.1 基于度量的方法现有的基于度量的 FKGC 模型共享匹配网络或翻译网络的框架
对于基于匹配网络构建的模型,他们首先实现基于 GNN 的实体编码器来生成实体嵌入。然后将聚合模块应用于支持集中的实体对,以计算每个关系的嵌入。最后,该模型根据每个查询三元组与支持三元组的相似性计算其接受概率。像 TransE和 ConvE 这样的 KGE 模型也广泛用于实体编码器作为中间表示,以进一步增强其他信息。
遵循这个框架,GMatching是第一个解决一次性 KGC 问题的工作。它首先提出了一种邻居编码器,它利用局部图结构来生成更好的实体嵌入。这里的动机是,尽管以前 KGE 模型的实体嵌入可以编码关系信息,但以前的工作 表明,显式建模结构模式(如路径)仍然可以有益于关系预测。 GMatching 中的邻居编码器仅对每个给定实体的单跳邻居进行编码,即一组(关系,实体)元组,以保证它对大规模知识图谱具有通用性。具体来说,从单跳邻居集中每个元组的预训练 KGE 嵌入开始,GMatching 应用前馈层来编码每个元组中关系和实体之间的交互。然后将邻居编码器应用于支持实体对和查询实体对以生成每个表示。然后,该模型利用基于 LSTM 的循环处理块 在参考对和每个查询对之间执行多步匹配。匹配分数最终用于对每个查询的候选集中的每个实体进行排名。除了在 FKGC 任务上提出第一个基线模型外,该工作还提出了两个广泛使用的基准:NELL-One 和 Wiki-One 。两者都是按照 FKGC 任务设置构建的。表 3 和第 4.2 节提供了更多统计数据和详细信息。
共享相同的想法,FSRL将 GMatching 扩展到 few-shot 设置。它进一步提出了一种基于异构图结构和注意机制的关系感知异构邻居编码器来增强实体嵌入,使该模型可以编码不同邻居对任务关系的不同影响。这里的主要论点是不同的邻居应该以不同的方式影响任务关系,而像 GMatching 这样的模型忽略了。例如,以 ParentOfPerson 作为任务关系,邻居 (MarryTo, Melinda Gates) 应该比 (CeoOf, Microsoft) 具有更高的权重。为了解决这个问题,FSRL 引入了一个注意力模块,通过在对所有邻居进行编码时分配不同的注意力权重来生成实体嵌入。
通过应用注意力邻居编码器,FSRL 获取支持集中每个实体对的表示。然后,它实现了一个基于 RNN 的聚合器,为每个相关任务的支持实体对之间的交互建模,以生成整个支持集的信息表示。受聚合节点嵌入与递归神经网络 的启发,FSRL 在所有实体对上应用递归自动编码器聚合器。为了制定参考集的嵌入,它聚合了编码器的所有隐藏状态,并通过添加残差连接和注意力权重来扩展它们。
通过参考集的聚合表示,FSRL 应用匹配网络来发现参考集的相似实体对。不是将每个参考实体对与查询对进行比较,而是使用具有 LSTM 单元的类似循环匹配处理器来直接计算参考集和查询实体对之间的相似性,以进行最终答案排名。在训练期间,每次模型都会对任务关系进行采样并针对该任务优化模型。该模型将采样少量实体对作为支持集和一批查询实体对。通过污染查询实体对中的尾部实体来构造负训练集。元学习在梯度下降步骤中用于参数优化,因此 FSRL 可以很好地转换为测试小样本关系。
尽管 FSRL建议根据邻居与中央实体的相关性来区别对待邻居,它仍然在所有任务关系中为所有邻居分配固定权重。这样的解决方案导致静态实体嵌入到不同的任务中,损害了系统的有效性。 FAAN 更进一步,认为实体邻居应该对不同的任务关系产生不同的影响。例如,SteveJobs 与任务关系 HasJobPosition 和 HasChild 相关联。直观上,如果任务关系是 CeoOf,模型应该更关注实体 SteveJobs 的职位角色,而不是家庭角色。
此外,任务关系在不同的上下文中可以有不同的含义。例如,如果任务关系是 isPartOf,如图 1 所示,则这种关系具有不同的含义,例如与组织相关,如(利物浦,isPartOf,英超联赛)或与位置相关,如(盖恩斯维尔,isPartOf,佛罗里达州)。显然,对于查询 (Dallas, isPartOf, Taxes),与位置相关的引用应该比其他引用更有影响力。因此,参考(支持)三元组也应该对不同的查询有不同的贡献。
为了应对上述挑战,FAAN 提出了一种自适应注意邻居编码器来对具有单跳实体邻居的实体嵌入进行建模。他们还遵循 TransE 将任务关系嵌入建模为头实体嵌入和尾实体嵌入之间的转换,即 r ≈ h - t。然后,为了进一步模拟参考实体的各种角色,FAAN 基于实体邻居关系和任务关系的相关性训练注意力度量,以进一步获得参考集中每个实体的角色感知邻居嵌入。编码器允许动态注意力分数适应不同的任务关系。自适应机制有助于根据邻居的不同贡献捕获实体的不同角色。每个实体的最终表示都对预训练嵌入及其角色感知邻居嵌入进行编码。
通过编码器提供的增强实体表示,FAAN 进一步应用一堆 Transformer 块来支持和查询三元组,以捕获任务关系的各种含义。它借鉴了 中学习动态 KG 嵌入的思想。对于每个元素,它通过几个Transformer块传递元素嵌入和位置嵌入,以获得有意义的实体对嵌入。
然后,FAAN 在预测不同查询时不使用静态表示,而是通过聚合所有参考及其对任务关系的注意力得分来获得支持集的一般自适应表示。
FAAN 也以与 FSRL 相同的方式使用元训练,即模型在元训练集中针对不同的任务关系进行训练,以生成一组参数,这些参数在所有任务中都表现良好,并且可以快速适应测试集中的few-shot任务。综上所述,FAAN 通过捕获细粒度的含义来提高实体和参考表示的质量。与 FSRL 共享相似的匹配分数,FAAN 在 FKGC 任务上优于以前的模型。
另一方面,HARV 侧重于捕获相邻关系和实体之间的差异以及关系之间的交互,这些以前被忽略了。它通过分离头实体和关系(关系级别)之间以及关系和尾实体(实体级别)之间的信息,为中央实体表示引入了分层邻居聚合器。关系级注意力权重是根据头部实体和关系嵌入计算的。关系级嵌入是通过聚合具有这种注意力的头实体 ℎ 的邻居关系生成的。然后使用关系级嵌入和每个尾部实体的串联来生成实体级注意力权重。二级权重最终生成三级权重,用于计算增强的实体表示。关系编码器考虑了关系之间的交互。编码器是 FSRL 中带有 Bi-LSTM 的 LSTM 聚合器的扩展,它更新所有支持实体对的表示。支持实体对嵌入和 Bi-LSTM 编码器嵌入的串联用作每个实体对的最终表示,支持集由所有支持实体对的基于注意力的聚合表示。
此外,GEN 研究了一种图外 FKGC 场景,用于预测未见实体之间或已见实体与未见实体之间的关系。元学习是将知识从可见实体外推到不可见实体,并将知识从具有许多链接的实体转移到少数链接。 GEN 进一步开发了一个随机嵌入层,用于对不可见实体之间的链接预测中的模型不确定性进行转换推理。 Gen 与任何 GNN 兼容。具体来说,在元训练阶段使用两个 GEN 进行归纳和转导链接预测。第一个 GEN 是感应式 GEN。它学习对未观察到的未见实体进行编码,并预测已见和未见实体之间的联系。第二个 GNN 分别是转导 GEN。学习预测看不见的实体本身之间的联系需要更进一步。为了实现转导推理,GEN 中的元学习框架可以在元训练期间模拟看不见的实体,而它们在传统学习方案中是观察不到的。此外,由于对不可见实体的链接预测本质上是不可靠的,在每个实体只有几个三元组可用的少镜头场景中会变得更糟,因此 GEN 学习了随机嵌入的不可见表示的分布以解决不确定性。此外,我们应用迁移学习策略来模拟长尾分布。这些导致 GEN 代表看不见的实体,这些实体与看到的实体很好地对齐。如前所述,由于缺乏支持的三元组导致看不见的实体表示的不确定性,朴素的 GEN 可能会受到图外链接预测的内在不可靠性的影响。解决这个问题的随机层通过学习实体嵌入的分布来嵌入一个看不见的实体。GEN 还对来自具有蒙特卡洛丢失的转换 GEN 的输出嵌入的不确定性来源进行建模。
最近,REFORM 提出了一个错误感知模块来控制影响 FKGC 的错误的负面影响。它与原始 FKGC 略有不同,从少样本关系类别中预测查询实体对的缺失关系类别。由于大多数现实世界的知识图谱都是自动构建的,因此许多错误在没有人工验证的情况下被合并到知识图谱中。此类错误显着降低了先前方法在 FKGC 上的性能,尤其是当只有少数支持三元组可依赖时。 REFORM 的邻居编码器专注于使用注意力机制选择最可靠的邻居来增强实体表示。注意权重矩阵使用预训练嵌入(在 REFORM 中,TransE)进行训练,以确保那些正确的邻居具有更高的权重。然后使用 softmax 函数对矩阵进行归一化,以获得每个实体的稳健嵌入。参考实体对由它们的头部和尾部实体嵌入的串联表示。然后,为了在支持集中为关系生成稳健的嵌入,REFORM 包含一个基于转换器编码器的交叉关系聚合模块,以捕获关系相关性和支持实例。 Transformer 编码器基于多头注意力机制使每个输入嵌入参与所有其他输入嵌入的编码。然后在错误缓解模块中,REFORM 利用图卷积网络 (GCN) 为每个查询任务生成各种关系的置信度权重。可以将置信度权重视为注意力权重以限制错误的影响。具体来说,REFORM 构建了一个面向查询的图来衡量不同支持实例对特定查询关系的影响。 GCN 被训练以最小化查询关系被分组到错误类别中的损失。
使用 Translation Network 的代表是 MetaR。这个想法是,MetaR 不是编码邻居信息,而是专注于将一个任务中的公共和共享信息从参考实例转移到查询三元组。此类信息在 MetaR 中称为关系元。关系元学习器从支持集中的头和尾实体嵌入生成实体对的表示。给定支持集中的头尾实体对,学习器首先通过使用 LeakyReLU 作为激活函数的全连接神经网络提取实体对特定关系元。任务的最终关系元是当前支持集中所有实体对特定关系元的平均值。
MetaR 还利用元学习来加速学习过程,这被称为梯度元。如第 3.2.5 节所述,模型应该能够快速更新新的小样本任务。 MetaR 继承了 TransE的思想,应用了类似的评分函数 || hi+RTr−ti ||用关系元计算每个实体对的分数。然后,通过使用所有正三元组和负三元组的分数最小化支持集的损失,参数的梯度可以指示它们应该如何更新。按照这个梯度更新规则,MetaR 可以对关系元进行快速更新,并使用更新后的元数据对具有相同评分函数的查询集进行评分。
该模型经过训练以最小化一批中所有任务的查询损失总和。与依赖背景知识图的 GMatching 相比,我们的 MetaR 独立于它们,因此,它更健壮,因为背景知识图可能无法用于实际场景中的少镜头链接预测。
GANA 更进一步,通过使用注意力机制和 LSTM 聚合器改进嵌入和关系元计算来扩展 MetaR。这里的动机是,当邻居是空闲的或者即使没有合适的邻居可用于表示小样本关系时,噪声邻居信息可能会损害模型。 GANA 提出了一个全球-本地框架。在全局阶段,构建了一个门控和细心的邻居聚合器来准确地集成少量关系邻域的语义,这有助于过滤噪声邻居,即使 KG 包含极其稀疏的邻域。将与few-shot关系相关联的头尾实体及其邻域相结合,以消除由于稀疏邻域引起的噪声邻域信息。门控机制可以确定邻域表示对表示小样本关系的重要性。具体来说,在全球阶段开发了一种基于图形注意力网络(GAT)的邻居编码器,以捕获邻居的不同影响,以提高实体嵌入的质量。编码器基于可训练的线性变换矩阵为每个邻居生成注意力权重。 GANA 使用带有线性变换的门值来消除由于稀疏邻域引起的噪声邻居,从而自动确定实体的邻居对少样本任务关系的影响。然后通过将实体嵌入与其邻居表示相结合来表示实体。支持集的最终三重邻居表示是头和尾表示的串联。通过对支持集进行编码,GANA 使用细心的 Bi-LSTM 编码器将查询关系的多个邻域表示集成到支持集中。查询关系表示是加权的通过组合支持集中的所有邻居嵌入,Bi-LSTM 的最终隐藏状态的总和。对于本地阶段,基于元学习的 TransH(MTransH) 方法旨在对复杂关系进行建模,并以少量学习的方式训练我们的模型。使用 TransH 的原因是它能够模拟复杂的关系。将类似的损失函数与 MAML 方法一起应用,以学习元训练集中所有小样本(查询)关系的初始化良好的参数。
另一个类似的 FKGC 模型 HiRe [76],可以看作是 GANA 的扩展。它提出联合捕获三个级别的关系信息:实体级别、三级和上下文级别。对比学习用于将头实体和尾实体的邻居联合编码成一个三元组,以编码更广泛的上下文。 HiRe 为目标三元组提出了一个上下文编码器,以基于自注意力机制学习其真/假上下文的嵌入,以便上下文中的重要邻居将被赋予更高的权重。此外,使用对比损失将三元组拉近其实际上下文并将其与错误上下文分开。然后在三层关系学习阶段,HiRe 开发了一个基于 transformer 的元关系学习器来捕获参考三元组之间的交互,并生成目标关系的元关系表示,而不是 LSTM。最后,HiRe 采用基于 TransD 的元评分函数来捕获实体和关系的多样性。基于 MAML 的训练策略也类似地应用于 GANA。有了三级关系信息,与最先进的模型相比,HiRe 在 NELL-One 和 Wiki-One 上的表现更好。消融研究进一步证明,所有三个级别的关系信息对 HiRe 的性能都至关重要,未来的模型可以进一步利用这些信息。
Meta-iKG 是该轨道上的另一项近期工作,它提出利用局部子图来传输特定于子图的信息,并通过带有元学习的元梯度快速学习可传输模式。图神经网络最近被纳入归纳关系推理,以捕获目标三元组周围的多跳信息。例如,GraIL 提出了一个基于子图的关系推理框架来处理看不见的实体。 CoMPILE通过引入节点边缘通信消息传递机制来对有向子图进行建模来扩展该想法。 Meta-iKG 可以理解为 CoMPILE 方法对 FKGC 的扩展。 Meta-iKG 不再局限于转导设置并且无法处理看不见的实体,而是针对少量的归纳 KGC 任务,包括测试集中的新实体。该模型将关系分为小样本关系和大样本关系,在关系实例数和具有大样本关系的元训练上使用阈值 K 来找到初始化良好的参数,并按照 MAML 的框架在具有小样本关系的三元组上调整模型. Meta-iKG 继承了 MetaR 的结构,首先在关系特定学习阶段提取目标和尾部实体之间的直接封闭子图。然后应用归纳节点标记函数来识别子图中实体的不同角色。
节点嵌入由到目标实体的距离初始化,以嵌入子图中每个节点的相对位置。然后,Meta-iKG 遵循 CoMPILE 的思想,使用通信消息传递神经网络对每个子图进行评分,以将其目标三元组的合理性编码为任务损失。常规的元学习步骤保证了小样本关系的性能。然而,它们可能会给更新的参数带来偏差,因为任务关系查询集只更新最终参数。为了保证 Meta-iKG 在 large-shot 关系上的性能,它引入了 large-shot 关系更新程序,使用较低学习率的支持集进一步更新最终参数。此操作使 Meta-iKG 能够很好地泛化整个归纳数据集。
为了解决 KG 依赖问题并在训练阶段进一步利用负样本,提出了元模式学习框架 MetaP。数据中的模式是对数据进行分类的代表性规律。 KGs 中的三元组也遵循关系特定的模式,可以用来衡量三元组的有效性。关系的模式是指头实体、关系和尾实体的特征共现的规律性。 MetaP 设计了一个基于卷积滤波器的模式学习器来直接提取三元组的模式。它可以学习潜在的表征来自有限参考文献的特定关系模式,因此独立于背景 KG。此外,通过利用负引用,MetaP 可以更准确地衡量查询三元组的有效性。提出了一种具有有效性平衡机制(VBM)的模式匹配器来预测查询三元组的模式是正还是负的概率。
-未完待续-