知识图谱技术最早为谷歌所提出,随后在其搜索引擎中上线一系列产品。即使假设是谷歌首次提出这一概念,至今也有很长时间了,网上已经有了很多介绍知识图谱相关内容的文章。根据个人学习习惯,只有从宏观角度把握住问题的全局,才能在解决细节问题时不至于走偏路。因此,出于总结目的,写出此系列笔记。
本篇主要从宏观层面介绍知识图谱的产生、发展及一些概念问题。
1 知识图谱的定义与架构
1.1 知识图谱的定义
维基百科上对知识图谱的定义是这样的:知识图谱是谷歌及其提供的服务所使用的知识库,目的是通过从各种来源收集信息以增强其搜索结果的展示。从现在的发展来看,这显然是狭义的。目前许多公司都已经具备了构建知识图谱的技术,并有了一系列应用成果,可以说,知识图谱是已经从最初的被应用与改善搜索效果延伸到了许多其他的方面。
参考文献1中给出的知识图谱的定义是:
知识图谱, 是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。其基本组成单位是“实体-关系-实体”三元组,以及实体及其相关属性- 值对,实体间通过关系相互联结,构成网状的知识结构。
注意,知识图谱最初就是用来改善搜索效果的,因此在搜索方面应用的最多也最成熟。通过知识图谱,可以实现Web从网页链接向概念链接的转变,从而支持用户按主题而不是字符检索(Things, not strings),实现真正的基于语义的检索。
该定义有三方面的含义:
- 知识图谱本身是一个具有属性的实体通过关系链接而形成的网状知识库。从图的概念来看,知识图谱是对物理世界的一种符号表达。
- 知识图谱的研究价值在于:它是构建在当前Web基础上的一层覆盖网络,知识图谱的目标是在当前网页之间建立概念的链接,从而将互联网上的知识进行整合,成为“知识”。
- 知识图谱的应用价值在于,它可以帮助人们准确的锁定自己想要检索的内容,而不必从海量网页中人工过滤。
1.2 知识图谱的架构
主要是指两方面:逻辑架构和技术架构。
1.2.1 逻辑架构
所谓逻辑架构,指的是图谱的双层结构:数据层和模式层。在数据层,知识以事实(fact)为单位存储在图数据库中。事实一般以三元组的方式进行描述,例如“实体-关系-实体”、“实体-属性-属性值”,借此,图数据库中所有的数据将组成庞大的关系网络,形成所谓的“图谱”。
个人感觉知识图谱和中国的家谱在逻辑架构方面是及其类似的。如果从诞生家谱概念那一天开始就一直延续不曾间断,那么家谱的内容也将是极其庞大的。不同的是,图谱中实体的关系可能是错综复杂的,而家谱中三四代之后的人和之前的祖先几乎没有什么联系了。
模式层建立在数据层之上,按照字面意思理解就是:对数据层的知识设置一种过滤模式,从而减少知识的冗余。举个例子,比如一个人可能有两个名字,在数据层,不同的名字可能对应了不同的属性和关系,而模式层就是把这实质上是同一个人的实体及其关系进行融合(知识融合),去除不必要的冗余。
这里总结一下个人理解的误区

如图所示,底层是原始网页,我以前一直以为知识图谱中包含了所有的原始网页中的数据,而实际上知识图谱只是从原始数据中获取了它们之中的实体、关系、属性以及它们到原始网页的链接(第二层),再经过模式层进行知识融合。用户发出搜索请求后,通过前两层的知识查询,然后通过链接找到对应的原始网页返回给用户。也就是说,图谱只包含关系,但并不包含内容。
1.2.2 技术架构
知识图谱的整体技术流程如下图所示:
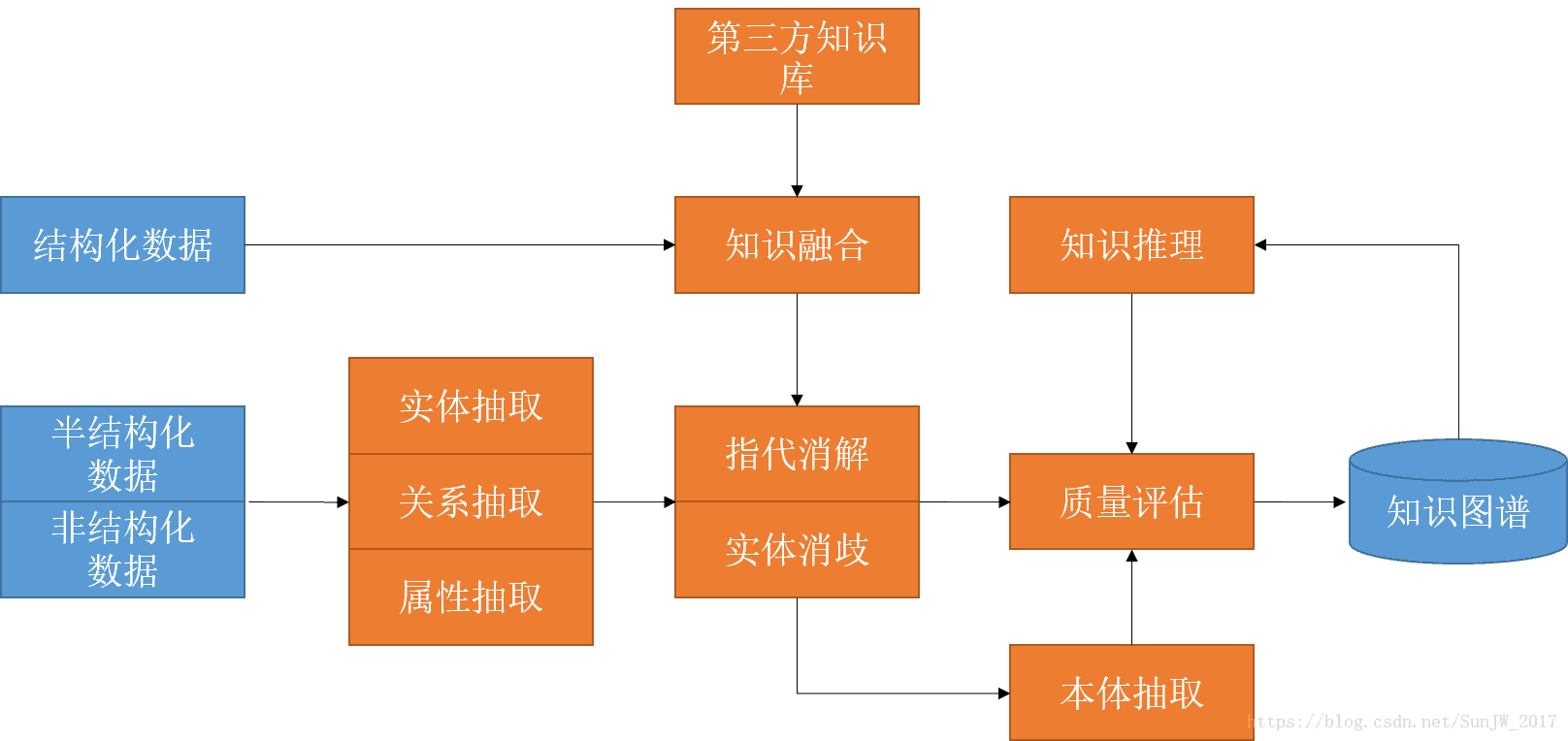
橘色部分代表着知识图谱的构建及迭代过程:知识抽取、知识融合、知识加工。一般人们会把知识图谱的构建分为自顶而下和自底而上两种不同的形式,随着技术的不断成熟,现在大都采用自底而上的方法,即从数据中提取资源模式,通过一定的技术手段,选择其中置信度较高的部分,加入到知识图谱中去。
2 知识图谱的构建技术
上文提到,知识图谱的构建及迭代主要是三个步骤,下面就每个步骤进行说明。
2.1 知识抽取(Knowledge Extraction)
知识抽取的目标就是从数据源中抽取出实体、关系及属性等信息,进而进行下一步的操作,所以这一项工作更准确地说应该叫做信息抽取,因为这一步骤并不能得到我们最终想要的“知识”。相应地,这一步骤涉及到的主要技术包括:实体抽取、关系抽取以及属性抽取。
2.1.1 实体抽取(Entity Extraction)
实体抽取,即所谓的命名实体识别(Named Entity Recognition, NER),指的就是如何从数据,特别是文本数据中准确获得其中的实体信息。实体的类型主要包括三大类七小类:
- 实体类(包括人名,地名,机构名)
- 时间类(日期,时间)
- 数字类(货币、百分比)
具体到特定领域,当然还可以对实体类别进行扩充。NER技术的发展,同样是经历了由基于规则的方法到基于统计的方法的转变,个人认为,随着语言习惯的变化,不可能找到一种一劳永逸的方法来彻底解决该问题,只能是结合特定领域,通过优秀的算法和丰富的预料来不断改善识别效果。因此,撇开应用谈技术是没有意义的。
2.1.2 关系抽取(Relation Extraction)
实体抽取获得了图数据库中的节点,那么关系抽取就是获得节点之间的连线的过程。
在早期的研究中,关系抽取同样基于规则,但这种方法本身的局限注定单基于规则建立模型不是长久之计。后来采用统计机器学习的方法,得到了不错的效果,但需要大量人工标注的语料,这对于特定领域的关系抽取来说,工作量无疑是巨大的。后来的基于半监督、无监督以及自监督模型,对模型的通用性有了一些提高,但整体来说,由于自然语言的复杂性,这一领域的学者仍然是任重而道远。
2.1.3 属性抽取(Attribution Extraction)
如果把实体的属性值看作是一种特殊的实体,那么属性抽取实际上也是一种关系抽取。 百科类网站提供的半结构化数据是通用领域属性抽取研究的主要数据来源,但具体到特定的应用领域,涉及大量的非结构化数据,属性抽取仍然是一个巨大的挑战。
2.2 知识融合(Knowledge Fusion)
上一步抽取出的三元组信息存入数据库后,具备了初步的“知识”,但这些知识仍然不能直接利用。例如,对于前美国总统奥巴马,我们可能用不同的词来称呼他,在实体识别中这些称呼都被看作是独立的实体,那么我们就应该把这些指向同一类实体的三元组进行合并。再举一个例子,同名同姓的两个不同的人,如何区分他们呢?这就涉及下面的技术。
2.2.1 指代消解(Coreference Resolution)
这个词可能不是很好理解,但理解它所代表的意思即可:消解那些指代不同实体的内容,这一技术就是处理对同一实体的不同语言描述问题(如上文对奥巴马的不同称呼)。利用这一技术,就可以将这些看似不同的实体归纳到一个统一的实体。这一技术本身也具有很多“称呼”:对象对齐,实体匹配,实体同义等。(我感觉都比指代消解更容易理解)
2.2.2 实体消歧(Entity Disambiguation)
相比而言,这个词就好理解多了,其作用也简单,就是对具有相同名称的实体进行区分。例如两个人同名,那就通过性别、工作、兴趣爱好等其他属性进行区分。
2.2.3 知识合并(Knowledge Fusion)
知识合并主要就是从结构化数据或者第三方库中获取知识并融合进图谱的过程。
我认为从关系型数据库中获取知识这一点在具体领域应用中是很重要的,通过资源描述框架模型,可以很方便地将企业地关系型数据库中的内容转化为三元组模式,进而用于图谱的构建。
2.3 知识加工(Knowledge Processing)
严格来讲,经过前两步骤处理后的数据仍不能称得上是“知识”,只能算是事实表达的集合,要想获得结构化的知识,还需要经过知识加工环节。知识加工主要包括3方面内容: 本体构建,知识推理和质量评估。
2.3.1 本体构建(Ontology Construction)
这又是一个不容易理解的概念。本体最早是一个哲学上的概念,在知识图谱上引用本体构建这一技术,目的是对相关领域的知识进行总结提取,确定在该领域内得到共识的术语,然后以格式规范的定义来描述这些内容。可以这样理解,前两阶段提取出来的实体及其属性关系,是本体的具体表现;而本体就是对它们的概括总结。
当然,这个概念我目前也没有搞明白,以后清晰了再加以补充。
2.3.2 知识推理(Knowledge Inference)
知识推理指的是从已有的知识中推理出新的知识。例如康熙是雍正的父亲,雍正是乾隆的父亲,那么尽管康熙和乾隆这两个实体之间通过知识推理,就可以获得他们之间是祖孙关系。
2.3.3 质量评估(Quality Evaluation)
顾名思义,质量评估就是对写入知识图谱中的知识做最后的判断,以提高知识库中内容的准确性。
2.4 知识更新(Knowledge Update)
知识图谱并不是一成不变的,随着人类知识的增加,图谱的内容也要定期进行更新,以满足最新的知识需求。更新的方式有两种,一种是“打补丁”,即增量更新,将新增加的人类知识经过处理加入到知识图谱中;另一种是“推倒重建”,即全局更新,就是从零开始重建新图谱。事实上,无论哪种方法都是一件消耗巨大的工作。
3 总结
本文写于工作之初,实际上是一篇整理思路的笔记,整体流程没什么问题,但具体细节可能有纰漏甚至错误。随着工作的深入,后续会不断改进,也会继续记录每一个技术细节的具体实施过程。
想要深入了解更多,请下载阅读参考文献及其相关引用内容。
- 《知识图谱构建技术综述》,刘峤等,计算机研究与发展。 ↩