基于相似度的本体匹配
2.1.sf(similiarity flooding)
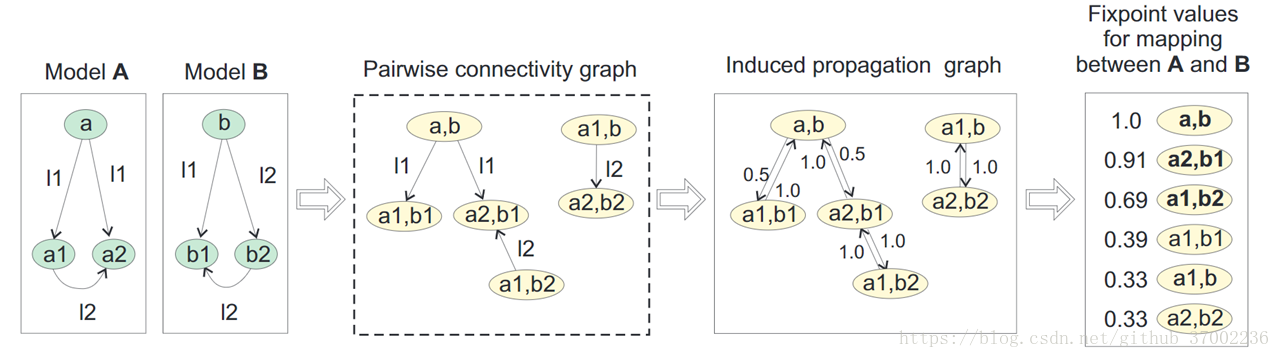
1)pairwise connectivity graph(PCG) : ((x; y); p; (x'; y')) 属于 PCG(A;B)<==>(x; p; x') € A and (y; p; y') € B。 关键是p要相同,也就是边的名字一样。式子从右向左推导,就可以A、B从两个模型建立起它们的PCG。图中的每个节点,都是A和B中的元素构成的2元组,叫做map pairs。
2)induced propagation graph。从PCG推导而来,加上了反向的边,边上注明了[传播系数],值为 1/n,n为相应的边的数目。
3)每次迭代中,ó-values 都会根据其邻居paris的 ó-values 乘以[传播系数] 来增加。例如,在第一次迭代 ó1(a1; b1) = ó0(a1; b1) + ó0(a; b) * 0.5 = 1.5。类似的,ó1(a, b) = ó0(a, b) + ó0(a1; b1) * 1.0 + ó0(a2, b1) *1.0 = 3.0。接下来,所有 ó 值进行正规化,比如除以当前迭代的 ó 的最大值,保证所有 ó 都不大于1。所以在正规化以后,ó1(a; b) = 1.0, ó1(a1, b1) = 1.5/3.0 = 0.5。
sf实现:https://github.com/dice89/owlSimilarityFlooding
sf方法缺陷
相似性只能传播到“等边”的元素,算法中并没有考虑边的相似
在繁殖图中,为双向边赋值繁殖系数,繁殖系数根据点对的出度均匀分配,相似度的计算只是简单地利用繁殖系进行迭代,因此元素的相似度只由与它同边的相似对决定而忽略了其他元素自身的某种联系。
2.2.改进sf
算法的主要流程为:
1)利用WordNet对元素相似度进行初始化.挑选出一组可信度较高的相似对种子;
2)基于改进的SF算法发现可能的相似对;
3)根据元素的特征(如元素的父类、子类、属性等)综合计算相似对的相似度;
4)更新相似对种子,迭代地用相似度传播算法发现相似对,计算相似度,直到收敛;
5)从最终的相似度矩阵中提取出匹配对。