基于深度学习知识图谱综述
摘要:随着现如今计算机设备的更新,计算能力的不断提高促使深度学习再一度推上热门技术,深度学习已经广泛应用于图像处理、文本挖掘、自然语言处理等方面,在医学、交通、教育、旅游等行业发挥极大地作用。知识图谱也在深度学习的技术下得到了很大的发展。
- 知识图谱的定义
- 知识图谱的构建流程
- 相关构建技术
知识图谱的定义
知识图谱(Knowledge Graph)最先由谷歌公司提出,其开发了基于知识图谱的项目,其将知识图谱应用在语义搜索方面,通过构建起来的知识图谱可以精准的搜索出需要的信息。谷歌给予的定义为:知识图谱是谷歌用于增强其搜索引擎功能的辅助知识库,总的来讲,知识图谱就是以结构化的信息通过图结构进行关联起来的一个知识库,而基于深度学习的知识图谱的构建是将某一领域的数据信息通过深度学习算法构建“实体——关系——实体”的三元组模型,并将其存储在图结构数据库中。
知识图谱的构建流程
知识图谱的结构是指实现构建知识图谱的技术体系,主要分为两大数据采集与处理两部分。数据采集(Data Acquisition )是指选择构建知识图谱的“原材料”,基于深度学习的知识图谱需要大量的训练数据进行模型训练,因此数据采集是知识图谱的重要的架构之一。数据处理是指针对采集的数据进行相关算法操作,完成相应的任务。如图1,知识图谱架构主要分为如下几个流程:
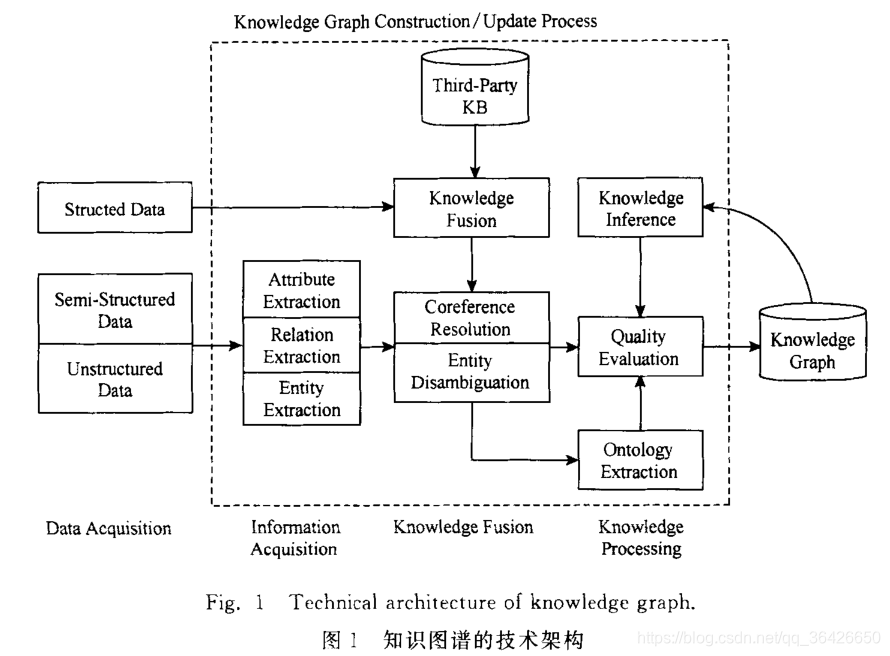
-
数据采集(Data Acquisition ) :采集数据集一般可以通过网络爬虫、数据库获取、人工制作数据或者在相应官网上下载处理过的数据,采集的数据一般由三种形态:
- 结构化数据(Structed Data):对于网络数据库现有的信息,可以直接进行数据库读写,这一类数据属于事先被筛选或整理成二维形式内容,因为其属于人工筛选,其置信度往往很高,因此这一类数据是作为知识图谱构建前期最主要的方式。但是由于结构化数据需要进行大量的人工操作,所以基于大量数据的情况下,以人工制作结构化数据需要的成本太高;
- 半结构化数据(Semi-Structed Data):半结构化数据是指以web形式显示的内容,例如百度百科、维基百科等,这一类数据往往是以XML、JSON等形式存在,介于结构化与非结构化之间。这一类数据需要进行一系列的数据预处理工作,将其转换为结构化数据;
- 非结构化数据(Unstructed Data):非结构化数据往往是没有任何结构的数据,例如图片、音频、文本等信息,这一类数据往往整体存储或读写。知识图谱的构建绝大多数需要对这些非结构化数据进行挖掘,因此知识图谱的构建主要数据来源为非结构化数据,同时相关的研究也主要以非结构化数据为“原材料”。
-
知识抽取(Information Extraction):
数据采集后需要进行相应的数据操作,在知识图谱中的数据操作的关键部分是知识抽取,知识抽取主要包括三个步骤:命名实体识别(NER)、实体关系抽取(RC)和属性抽取。
- 命名实体识别(NER):命名实体识别是对半结构化数据和非机构化数据进行信息抽取的第一步,往往实体是信息的主要载体。实体可以是人、地名等事物,也可以是某个概念。在早期通过字符串匹配或人工操作等方式将需要的实体提取出,随后人们通过自然语言处理和机器学习方式进行实体提取,而基于深度学习的知识图谱架构中,命名实体识别通过序列标注方法进行识别
- 实体关系抽取(RC):实体关系抽取又称关系分类,为了确定“实体——关系——实体”三元组,需要对实体之间的关系进行分类,这一过程也成为语义信息的提取。早起的关系抽取采用人工方式,根据语言的语法规则进行模式匹配,这一方式虽然精度很高,但是需要各个领域的专业人士进行操作,同时需要大量的劳动力成本。基于深度学习的知识图谱架构中,通过特征工程对含有具有关系的两个实体的句子进行关系标注,实现监督学习。现如今也有基于自监督学习方式进行关系抽取。另外,Zheng等人提出的联合NER和RC的学习,将两个步骤融合一起形成联合学习方式,在一定程度上提高了模型的精准度,因此
- 属性抽取:构建起三元组后,需要对实体和关系进行属性的抽取,属性抽取往往可以直接通过网络获取,同时也可以将属性视为实体或关系,通过NER或者RC方式进行处理。
命名实体识别、实体关系抽取以及属性抽取是知识图谱的构建的主要部分,也是为下一步操作做准备。
- 知识融合(Knowledge Fusion):
通过知识抽取工作获得的三元组往往有一定程度的错误信息。在通过NER、RC的模型优化角度考虑,模型的精度往往不是100%,因此会有被错误识别的实体或被错误分类的关系,因此为了提高知识图谱的置信度,需要对其进行处理,主要方式有:
- 实体消歧:同一个实体可能有不同种名称,同一个名称可能表示不同类型实体。例如“华东师大”和“华东师范大学”都是同一个事物,而在知识抽取过程中,并没有将其合并,因此实体消歧的主要目的是消除同名实体产生的歧义问题。参考文献[1]提供的四种方法:空间向量模型、语义模型、社会网络模型和百科知识模型可以实现实体消歧。
- 共指消解:在一个句子中,往往有多种指称项指向同一个实体,这一类问题可以通过句法分析方式进行处理,也可以通过基于机器学习算法方式转化为分类或聚类问题。
- 知识合并:往往自主建立的知识体系相对孤立,信息量有限。为了使自主构建的知识体系可以与网络现有的知识库相呼应,需要对知识进行合并,可以将以构建的知识体系以图结构存储在图形数据库中,通过实体消歧进行合并,也可以将知识体系以关系型存储在关系数据库中,并通过数据库技术进行合并。知识合并是扩大自主学习构建知识库的重要步骤。
在自主构建知识图谱过程中,知识融合往往会被忽略,但也格外重要。
- 知识加工(Know Processing):
通过信息抽取,可以从原始语料中提取出实体、关系与属性等知识要素.再经过知识融合,可以消除实体指称项与实体对象之间的歧义,得到一系列基本的事实表达.然而,事实本身并不等于知识,要想最终获得结构化、网络化的知识体系,还需要经历知识加工的过程.知识加工主要包括3方面内容:本体构建、知识推理和质量评估。
- 本体构建:本体是用于描述一个领域的术语集合(如下图),本体的目标是获取、描述和表示相关领域的知识,提供对该领域知识的共同理解,确定领域内共同认可的词汇,并从不同层次的形式化模式上给出了这些词汇(术语)和词汇间相互关系的明确定义。本体的构建可参考:领域本体的构建方法研究

- 知识推理:顾名思义,是对知识之间的关系推理,知识推理包括逻辑关系推理和图关系推理。逻辑关系推理属于语义分析部分。例如命题“985高校一定是211,而211高校不一定是985”,由此可以推理出华东师范大学是985也是211。图关系推理根据图模型进行关系拓展,例如建立的三元组有“华东师范大学在普陀区”,“普陀区在上海市”,可以推理出“华东师范大学在上海市”。
- 知识更新:知识是不断的更新迭代的,构建好的知识图谱需要不断的进行更新。更新方式一般有两种:全面更新和增量更新。
知识图谱构建技术
基于深度学习的知识图谱构建,主要应用深度学习框架,技术主要包括:
(1)数据采集:基于Python网络爬虫的数据采集;
(2)词向量训练:word-embedding训练,包括CBOW、Skip-gram模型以及哈夫曼树和负采样加速方法;
(3)命名实体识别:RNN,BiRNN,LSTM,BiLSTM,CRF;
(4)实体关系抽取:基于CNN的关系分类,TextCNN;
(5)联合实体与关系抽取:复合神经网络模型;
(6)深度学习框架:Tensorflow;
(7)数据标注:特征工程;
(8)图数据库:较为流行的图数据库有 Neo4j,Titan,OrientDB和 ArangoDB,本人常用的是Neo4j;
(8)涉及到数学知识:矩阵论、概率论与数理统计、最优化方法(神经网络主要以梯度下降法调参)。
Ps:现如今知识图谱的构建在科研领域是一个庞大的课程研究体系,涉及诸多技术,本人在学习过程中将不断更新和增加相关技术以适应知识图谱的发展。
总结
知识图谱已经广泛应用于各个领域中,常用的应用包括智能问答系统,精准搜索等,知识图谱作为当今非常火的人工智能研究方向,在未来将有很大的上升空间。
参考文献:
[1]: 段宏等. 知识图谱构建技术综述[J]. 计算机研究与发展(03).
[2]: 袁凯琦等.医学知识图谱构建技术与研究进展[j].计算机应用研究.
[3]: https://blog.csdn.net/github_37002236/article/details/81907721
博客记录着学习的脚步,分享着最新的技术,非常感谢您的阅读,本博客将不断进行更新,希望能够给您在技术上带来帮助。