知识图谱综述
伴随着Web技术的不断演进与发展,人类先后经历了以文档互联为主要特征的“Web 1.0”时代与数据互联为特征的“Web 2.0”时代,正在迈向基于知识互联的崭新“Web 3.0”时代。知识互联的目标是构建一个人与机器都可理解的万维网,使得人们的网络更加智能化。然而,由于万维网上的内容多源异质,组织结构松散,给大数据环境下的知识互联带来了极大的挑战。因此,人们需要根据大数据环境下的知识组织原则,从新的视角去探索既符合网络信息资源发展变化又能适应用户认知需求的知识互联方法,从更深层次上揭示人类认知的整体性与关联性。
知识图谱( Knowledge Graph)的概念由谷歌2012年正式提出,旨在实现更智能的搜索引擎,并且于2013年以后开始在学术界和业界普及,并在智能问答、情报分析、反欺诈等应用中发挥重要作用。目前,随着智能信息服务应用的不断发展,知识图谱已被广泛应用于智能搜索、智能问答、个性化推荐等领域。另外,通过知识图谱能够将Web上的信息、数据以及链接关系聚集为知识,使信息资源更易于计算、理解以及评价,并且形成一套Web语义知识库。知识图谱以其强大的语义处理能力与开放互联能力,可为万维网上的知识互联奠定扎实的基础,使Web 3.0提出的“知识之网”愿景成为了可能。
1 知识图谱的定义与架构
1.1 知识图谱的定义
知识图谱本质上是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。现在的知识图谱已被用来泛指各种大规模的知识库。
三元组是知识图谱的一种通用表示方式,即 ,其中
是知识库中的实体集合,共包含
种不同实体;
是知识库中的关系集合,共
包含种不同关系;
代表知识库中的三元组集合。三元组的基本形式主要包括实体1、关系、实体2和概念、属性、属性值等,实体是知识图谱中的最基本元素,不同的实体间存在不同的关系。概念主要指集合、类别、对象类型、事物的种类,例如人物、地理等;属性主要指对象可能具有的属性、特征、特性、特点以及参数,例如国籍、生日等;属性值主要指对象指定属性的值,例如中国、1988-09-08等。每个实体(概念的外延)可用一个全局唯一确定的ID来标识,每个属性-属性值对(attribute-value pair,AVP)可用来刻画实体的内在特性,而关系可用来连接两个实体,刻画它们之间的关联。
1.2 知识图谱的架构
知识图谱的架构主要包括自身的逻辑结构以及体系架构。
1) 知识图谱的逻辑结构
知识图谱在逻辑上可分为模式层与数据层两个层次,数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。如果用(实体1,关系,实体2)、(实体、属性,属性值)这样的三元组来表达事实,则存储在图数据库中的所有数据将构成庞大的实体关系网络,形成知识的“图谱”,例如开源的Neo4j、Twitter的FlockDB、sones的GraphDB等。模式层构建在数据层之上,是知识图谱的核心,通常采用本体库来管理知识图谱的模式层,借助本体库对公理、规则和约束条件的支持能力来规范实体、关系以及实体的类型和属性等对象之间的联系。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。
2) 知识图谱的体系架构
知识图谱的体系架构是其指构建模式结构,如图1所示。其中虚线框内的部分为知识图谱的构建过程。知识图谱主要有自顶向下(top-down)与自底向上(bottom-up)两种构建方式。自顶向下指的是先为知识图谱定义好本体与数据模式,再将实体加入到知识库。该构建方式需要利用一些现有的结构化知识库作为其基础知识库。自底向上指的是从一些开放链接数据中提取出实体,选择其中置信度较高的加入到知识库,再构建顶层的本体模式。目前,大多数知识图谱都采用自底向上的方式进行构建,其中最典型就是Google的Knowledge Vault。
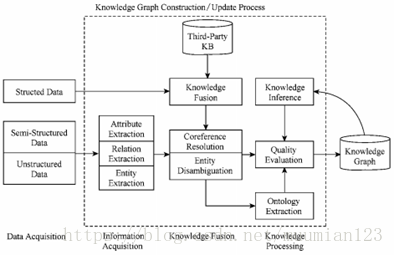
图1 知识图谱的体系架构
2 知识图谱技术地图
构建知识图谱的主要目的是获取大量的、让计算机可读的知识。目前知识大量存在于非结构化的文本数据、大量半结构化的表格和网页以及生产系统的结构化数据中。为了阐述如何构建知识图谱,画出知识图谱的技术地图如图 2 所示。整个技术图主要分为三个部分,第一个部分是知识获取,主要阐述如何从非结构化、半结构化、以及结构化数据中获取知识。第二部是数据融合,主要阐述如何将不同数据源获取的知识进行融合构建数据之间的关联,将在第三节说明。第三部分是知识计算及应用,这一部分关注的是基于知识图谱计算功能以及基于知识图谱的应用。
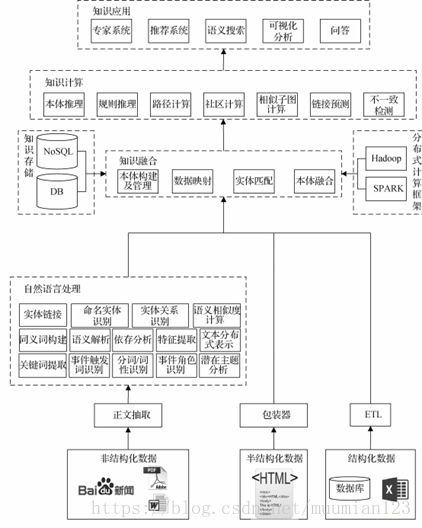
图2 知识图谱技术
2.1 知识获取
在处理非结构化数据方面,首先要对用户的非结构化数据提取正文。当得到正文文本后,需要通过自然语言技术识别文章中的实体。实体识别通常有两种方法,一种是用户本身有一个知识库则可以使用实体链接将文章中可能的候选实体链接到用户的知识库上;另一种是当用户没有知识库则需要使用命名实体识别技术识别文章中的实体。
在识别实体的过程中可能会用到分词、词性标注,以及深度学习模型中需要用到分布式表达如词向量。同时为了得到不同粒度的知识还可能需要提取文中的关键词,获取文章的潜在主题等。
在处理半结构化数据方面,主要的工作是通过包装器学习半结构化数据的抽取规则。由于半结构化数据具有大量的重复性的结构,因此对数据进行少量的标注,可以让机器学出一定的规则进而在整个站点下使用规则对同类型或者符合某种关系的数据进行抽取。最后当用户的数据存储在生产系统的数据库中时,需要通过 ETL 工具对用户生产系统下的数据进行重新组织、清洗、检测最后得到符合用户使用目的数据。
2.2 知识计算及应用
知识计算主要是根据图谱提供的信息得到更多隐含的知识,通过知识计算知识图谱可以产生大量的智能应用如可以提供精确的用户画像为精准营销系统提供潜在的客户;提供领域知识给专家系统提供决策数据,给律师、医生、公司 CEO 等提供辅助决策的意见;提供更智能的检索方式,使用户可以通过自然语言进行搜索;当然知识图谱也是问答必不可少的重要组建。
3 知识图谱的关键技术
大规模知识库的构建与应用需要多种智能信息处理技术的支持。通过知识抽取技术,可以从一些公开的半结构化、非结构化的数据中提取出实体、关系、属性等知识要素。通过知识融合,可消除实体、关系、属性等指称项与事实对象之间的歧义,形成高质量的知识库。知识推理则是在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。
3.1 信息抽取
信息抽取是知识图谱构建的第1步,其中的关键问题是如何从异构数据源中自动抽取信息得到候选知识单元。信息抽取是一种自动化地从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息的技术。涉及的关键技术包括:实体抽取、关系抽取和属性抽取。
3.1.1 实体抽取
早期的实体抽取也称为命名实体学习或命名实体识别,指的是从原始语料中自动识别出命名实体。由于实体是知识图谱中的最基本元素,其抽取的完整性、准确率、召回率等将直接影响到知识库的质量。因此,实体抽取是知识抽取中最为基础与关键的一步。
实体抽取的方法分为3种:基于规则与词典的方法、基于统计机器学习的方法以及面向开放域的抽取方法。基于规则的方法通常需要为目标实体编写模板,然后在原始语料中进行匹配;基于统计机器学习的方法主要是通过机器学习的方法对原始语料进行训练,然后再利用训练好的模型去识别实体;面向开放域的抽取将是面向海量的Web语料。
1) 基于规则与词典的实体抽取方法
早期的实体抽取主要采用的是基于规则与词典的方法,例如使用已定义的规则,抽取出文本中的人名、地名、组织机构名、特定时间等实体。RAULF首次实现了一套能够抽取公司名称的实体抽取系统,其中主要用到了启发式算法与规则模板相结合的方法。然而,基于规则模板的方法不仅需要依靠大量的专家来编写规则或模板,覆盖的领域范围有限,而且很难适应数据变化的新需求。
2) 基于统计机器学习的实体抽取方法
随后,研究者尝试将机器学习中的监督学习算法用于命名实体的抽取问题上。例如刘晓华等人利用KNN算法与条件随机场模型,实现了对Twitter文本数据中实体的识别。单纯的监督学习算法在性能上不仅受到训练集合的限制,并且算法的准确率与召回率都不够理想。相关研究者认识到监督学习算法的制约性后,尝试将监督学习算法与规则相互结合,取得了一定的成果。例如林一峰等人基于字典,使用最大熵算法在Medline论文摘要的GENIA数据集上进行了实体抽取实验,实验的准确率与召回率都在70%以上。
3) 面向开放域的实体抽取方法
针对如何从少量实体实例中自动发现具有区分力的模式,进而扩展到海量文本去给实体做分类与聚类的问题,WHITELAW C提出了一种通过迭代方式扩展实体语料库的解决方案,其基本思想是通过少量的实体实例建立特征模型,再通过该模型应用于新的数据集得到新的命名实体。JAIN A提出了一种基于无监督学习的开放域聚类算法,其基本思想是基于已知实体的语义特征去搜索日志中识别出命名的实体,然后进行聚类。
3.1.2 关系抽取
关系抽取的目标是解决实体间语义链接的问题,早期的关系抽取主要是通过人工构造语义规则以及模板的方法识别实体关系。随后,实体间的关系模型逐渐替代了人工预定义的语法与规则。但是仍需要提前定义实体间的关系类型。BANKOM提出了面向开放域的信息抽取框架(open information extraction, OIE)。但OIE方法在对实体的隐含关系抽取方面性能低下,因此部分研究者提出了基于马尔可夫逻辑网、基于本体推理的深层隐含关系抽取方法。
1) 开放式实体关系抽取
开放式实体关系抽取可分为二元开放式关系抽取和n元开放式关系抽取。在二元开放式关系抽取中,早期的研究有KnowItAll与TextRunner系统,在准确率与召回率上表现一般。WU F提出了一种基于Wikipedia的OIE方法WOE,经自监督学习得到抽取器,准确率较TextRunner有明显的提高。针对WOE的缺点,文献[40]提出了第二代OIE ReVerb系统,以动词关系抽取为主。SCHMITZMM提出了第三代OIE系统OLLIE(open language learning for information extraction),尝试弥补并扩展OIE的模型及相应的系统,抽取结果的准确度得到了增强。
然而,基于语义角色标注的OIE分析显示:英文语句中40%的实体关系是n元的,如处理不当,可能会影响整体抽取的完整性。AKBIK A提出了一种可抽取任意英文语句中n元实体关系的方法KPAKEN,弥补了ReVerb的不足。但是由于算法对语句深层语法特征的提取导致其效率显著下降,并不适用于大规模开放域语料的情况。
2) 基于联合推理的实体关系抽取
联合推理的关系抽取中的典型方法是马尔可夫逻辑网MLN(Markov logic network),它是一种将马尔可夫网络与一阶逻辑相结合的统计关系学习框架,同时也是在OIE中融入推理的一种重要实体关系抽取模型。基于该模型,文献[45]提出了一种无监督学习模型StatSnowball,不同于传统的OIE,该方法可自动产生或选择模板生成抽取器。在StatSnowball的基础上,又有人提出了一种实体识别与关系抽取相结合的模型EntSum,主要由扩展的CRF命名实体识别模块与基于StatSnowball的关系抽取模块组成,在保证准确率的同时也提高了召回率。另有人提出了一种简易的Markov逻辑TML(tractable Markov logic),TML将领域知识分解为若干部分,各部分主要来源于事物类的层次化结构,并依据此结构,将各大部分进一步分解为若干个子部分,以此类推。TML具有较强的表示能力,能够较为简洁地表示概念以及关系的本体结构。
3.1.3 属性抽取
属性抽取主要是针对实体而言的,通过属性可形成对实体的完整勾画。由于实体的属性可以看成是实体与属性值之间的一种名称性关系,因此可将实体属性的抽取问题转换为关系抽取问题。有人提出基于规则与启发式算法的属性抽取方法能够从Wikipedia及WordNet的半结构化网页中自动抽取相应的属性名称与属性值,还可扩展为一套本体知识库。实验表明:该算法的抽取准确率可达到95%。
抽取属性的方法,一种是将上述从百科网站上抽取的结构化数据作为可用于属性抽取的训练集,然后再将该模型应用于开放域中的实体属性抽取;另一种是根据实体属性与属性值之间的关系模式,直接从开放域数据集上抽取属性。但是由于属性值附近普遍存在一些限定属性值含义的属性名等,所以该抽取方法的准确率并不高。
3.2 知识融合
知识融合(knowledge fusion)指的是将多个数据源抽取的知识进行融合。知识融合使用多个知识抽取工具为每个数据项从每个数据源中抽取相应的值,而数据融合未考虑多个抽取工具。由此,知识融合除了应对抽取出来的事实本身可能存在的噪音外,还比数据融合多引入了一个噪音,就是不同抽取工具通过实体链接和本体匹配可能产生不同的结果。另外,知识融合还需要考虑本体的融合和实例的融合。
Wang H首先从已有的数据融合方法中挑选出易于产生有意义概率的、便于使用基于MapReduce框架的、有前途的最新方法,然后对这些挑选出的方法做出以下改进以用于知识融合:将每个抽取工具同每个信息源配对,每对作为数据融合任务中的一个数据源,这样就变成了传统的数据融合任务;改进已有数据融合方法使其输出概率,代替原来的真假二值;根据知识融合中的数据特征修改基于MapReduce 的框架。Huber J提出一个将通过不同搜索引擎得到的知识卡片(即结构化的总结)融合起来的方法。针对一个实体查询,不同搜索引擎可能返回不同的知识卡片,即便同一个搜索引擎也可能返回多个知识卡片。将这些知识卡片融合起来时,同Wang H提出的方法类似,将知识融合中的三维问题将为二维问题,再应用传统的数据融合技术。不过,Huber J提出了一个新的概率打分算法,用于挑选一个知识卡片最有可能指向的实体,并设计了一个基于学习的方法来做属性匹配。
在知识融合技术中,本体匹配扮演着非常重要的角色,提供了概念或者实体之间的对应关系。一般可以分为模式匹配(schema matching)和实例匹配(instance matching),也有少量的同时考虑模式和实例的匹配。
1) 模式匹配
模式匹配主要寻找本体中属性和概念之间的对应关系,Jeanmary Y R提出一个自动的语义匹配方法,该方法首先利用像 WordNet 之类的词典以及本体的结构等信息进行模式匹配,然后将结果根据加权平均的方法整合起来,再利用一些模式(patterns)进行一致性检查,去除那些导致不一致的对应关系。该过程可循环的,直到不再找到新的对应关系为止。Lambrix P也是考虑多种匹配算法的结合,利用基于术语的一些相似度计算算法,例如 n-gram 和编辑距离,这里算法计算的结果根据加权求和进行合并,还考虑了概念的层次关系和一些背景知识,最后通过用户定义的权重进行合并。为了应对大规模的本体,Seddiqui M H提出一个使用锚(anchor)的系统,该系统以一对来自两个本体的相似概念为起点,根据这些概念的父概念和子概念等邻居信息逐渐地构建小片段,从中找出匹配的概念。新找出的匹配的概念对又可作为新的锚,然后再根据邻居信息构建新的片段。该过程不断地重复,直到未找到新的匹配概念对时停止。Hu W则以分而治之的思想处理大规模本体,该方法先根据本体的结构对其进行划分获得组块,然后从不同本体获得的组块进行基于锚的匹配,这里的锚是指事先匹配好的实体对,最后再从匹配的组块中找出对应的概念和属性。现有的匹配方法通常是将多个匹配算法相结合,采用加权平均或加权求和的方式进行合并。但是,由于本体结构的不对称性等特征,这种固定的加权方法显出不足。Li J基于贝叶斯决策的风险最小化提出一个动态的合并方法,该方法可以根据本体的特征,在计算每个实体对的相似度时动态地选择使用哪几个匹配算法,如何合并这些算法,其灵活性带来了很好的匹配结果。
2) 实例匹配
实例匹配是评估异构知识源之间实例对的相似度,用来判断这些实例是否指向给定领域的相同实体。最近几年,随着Web 2.0和语义Web技术的不断发展,越来越多的语义数据往往具有丰富实例和薄弱模式的特点,促使本体匹配的研究工作慢慢的从模式层转移到实例层。Hu W提出一个自训练的方法进行实例匹配,该方法首先根据 owl:sameAs、函数型属性(functional properties)和基数(cardinalities)构建一个核(kernel),再根据区别比较明显的属性值对递归的对该核进行扩展。Duan S利用现有的局部敏感哈希(locality-sensitive hashing)技术来大幅提高实例匹配的可扩展性,该方法首先需要定义用于实例相似性分析的粒度,然后使用分割好的字符串技术实例相似度。Li J首先使用向量空间模型表示实例的描述性信息,再基于规则采用倒排索引(inverted indexes)获取最初的匹配候选,在使用用户定义的属性值对候选进行过滤,最后计算出的匹配候选相似度用来作为整合的向量距离,由此抽取出匹配结果。虽然已有方法中已有不少用于处理大规模本体的实例匹配问题,但是同时保证高效和高精度仍然是个很大的挑战。Shao C提出了一个迭代的框架,充分利用特征明显的已有匹配方法来提高效率,同时基于相似度传播的方法利用一个加权指数函数来确保实例匹配的高精度。
3.3 实体链接技术
歧义性和多样性是自然语言的固有属性,也是实体链接的根本难点。如何挖掘更多、更加有效的消歧证据,设计更高性能的消歧算法依然是实体链接系统的核心研究问题,值得进一步研究。下面按照不同的实体消歧方法进行分类。
1) 基于概率生成模型方法
韩先培和孙乐提出了一种生成概率模型,将候选实体e出现在某页面中的概率、特定实体e被表示为实体指称项的概率以及实体e出现在特定上下文中的概率三者相乘,得到候选实体同实体指称项之间的相似度评分值。 Blanco 和 Ottaviano 等人提出了用于搜索查询实体链接的概率模型,该方法采用了散列技术与上下文知识,有效地提高了实体链接的效率。
2) 基于主题模型的方法
Zhang 等人通过模型自动对文本中的实体指称进行标注,生成训练数据集用于训练 LDA 主题模型,然后计算实体指称和候选实体的上下文语义相似度从而消歧得到目标实体。王建勇等人提出了对用户的兴趣主题建模的方法,首先构建关系图,图中包含了不同命名实体间的相互依赖关系,然后利用局部信息对关系图中每个命名实体赋予初始兴趣值,最后利用传播算法对不同命名实体的兴趣值进行传播得到最终兴趣值,选择具有最高兴趣值的候选实体。
3) 基于图的方法
Han等人构造了一种基于图的模型,其中图节点为所有实体指称和所有候选实体;图的边分为两类,一类是实体指称和其对应的候选实体之间的边,权重为实体指称和候选实体之间的局部文本相似度,采用词袋模型和余弦距离计算得出。另一类是候选实体之间的边,权重为候选实体之间的语义相关度,采用谷歌距离计算。算法首先采集不同实体的初始置信度,然后通过图中的边对置信度进行传播和增强。Gentile等人提出了基于图和语义关系的命名实体消歧方法,该方法在维基百科上建立基于图的模型,然后在该模型上计算各个命名实体的得分从而确定了目标实体,该方法在新闻数据上取得了较高的准确率。Alhelbawy 等人也采用基于图的方法,图中的节点为所有的候选实体,边采用两种方式构建,一种是实体之间的维基百科链接,另一种是使用实体在维基百科文章中句子的共现。图中的候选实体节点通过和实体指称的相似度值被赋予初始值,采用PageRank 选择目标实体。Hoffart等人使用实体的先验概率,实体指称和候选实体的上下文相似度,以及候选实体之间的内聚性构成一个加权图,从中选择出一个候选实体的密集子图作为最可能的目标实体分配给实体指称。
4) 基于深度神经网络的方法
周明和王厚峰等人提出了一种用于实体消歧的实体表示训练方法。该方法对文章内容进行自编码,利用深度神经网络模型以有监督的方式训练实体表示,依据语义表示相似度对候选实体进行排序,但该方法是一种局部性方法,没有考虑同一文本中共同出现的实体间相关性。黄洪钊和季姮等人基于深度神经网络和语义知识图谱,提出了一种基于图的半监督实体消歧义方法,将深度神经网络模型得到的实体间语义关联度作为图中的边权值。从实验 结 果 得 出:基于语义知识图谱的NGD和VSM方法比起Wikipedia anchor links无论在关联性测试上还是在消歧性能上都具有更好的测试结果。相比NGD和VSM,基于DNN的深度语义关联方法在关联性测试上还是在消歧性能上都具有更好的关联性和更高的准确性。但该方法存在两点不足,一方面在构建深度语义关联模型时采用词袋子方法,没有考虑上下文词之间位置关系,另外一方面在消歧的过程中,构建的图模型没有充分利用已消歧实体,边权值和顶点得分随着未消歧实体增加保持不变,并没有为后续的歧义实体增加信息量。
3.4 知识推理技术
知识库推理可以粗略地分为基于符号的推理和基于统计的推理。在人工智能的研究中,基于符号的推理一般是基于经典逻辑(一阶谓词逻辑或者命题逻辑)或者经典逻辑的变异(比如说缺省逻辑)。基于符号的推理可以从一个已有的知识图谱,利用规则,推理出新的实体间关系,还可以对知识图谱进行逻辑的冲突检测。基于统计的方法一般指关系机器学习方法,通过统计规律从知识图谱中学习到新的实体间关系。
3.4.1 基于符号逻辑的推理方法
为了使得语义网络同时具备形式化语义和高效推理,一些研究人员提出了易处理(tractable)概念语言,并且开发了一些商用化的语义网络系统。这些系统的提出,使得针对概念描述的一系列逻辑语言,统称描述逻辑(description logic),得到了学术界和业界广泛关注。但是这些系统的推理效率难以满足日益增长的数据的需求,最终没能得到广泛应用。这一困局被利物浦大学的 Ian Horrocks 教授打破,他开发的 FaCT 系统可以处理一个比较大的医疗术语本体 GALEN,而且性能比其他类似的推理机要好得多。描述逻辑最终成为了 W3C推荐的 Web 本体语言 OWL 的逻辑基础,但是还是跟不上数据增长的速度。
最近几年,研究人员开始考虑将描述逻辑和 RDFS 的推理并行来提升推理的效率和可扩展性,并且取得了很多成果。并行推理工作所借助的并行技术分为以下两类: 1)单机环境下的多核、多处理器技术,比如多线程, GPU 技术等; 2)多机环境下基于网络通信的分布式技术,比如MapReduce 计算框架、 Peer-To-Peer 网络框架等。很多工作尝试利用这些技术实现高效的并行推理。
单机环境下的并行技术以共享内存模型为特点,侧重于提升本体推理的时间效率。对于实时性要求较高的应用场景,这种方法成为首选。对于表达能力较低的语言,比如 RDFS、OWL EL,单机环境下的并行技术将显著地提升本体推理效率。 Goodman 等人利用高性能计算平台 Cray XMT 实现了大规模的 RDFS 本体推理,利用平台计算资源的优势限制所有推理任务在内存完成。然而对于计算资源有限的平台,内存使用率的优化成为了不可避免的问题。Motik等人将 RDFS,以及表达能力更高的 OWL RL 等价地转换为Datalog程序,然后利用Datalog 中的并行优化技术来解决内存的使用率问题,Motik尝试利用并行与串行的混合方法来提升 OWL RL 的推理效率。Kazakov 等人提出了利用多线程技术实现 OWLEL 分类(classification)的方法,并实现推理机ELK。
尽管单机环境的推理技术可以满足高推理性能的需求,但是由于计算资源有限(比如内存,存储容量),推理方法的可伸缩性(scalability)受到不同程度的限制。因此,很多工作利用分布式技术突破大规模数据的处理界限。这种方法利用多机搭建集群来实现本体推理。
Mavin是首个尝试利用Peer-To-Peer的分布式框架实现 RDF 数据推理的工作。实验结果表明,利用分布式技术可以完成很多在单机环境下无法完成的大数据量推理任务。很多工作基于MapReduce的开源实现(如 Hadoop,Spark 等)设计提出了大规模本体的推理方法。其中较为成功的一个尝试是Urbani 等人在 2010 年公布的推理系统 WebPIE。实验结果证实其在大集群上可以完成上百亿的RDF三元组的推理。他们又在这个基础上研究提出了基于 MapReduce 的 OWL RL 查询算法]。利用MapReduce 来实现OWLEL本体的推理算法,实验证明 MapReduce 技术同样可以解决大规模的OWLEL本体推理。
3.4.2 基于统计的推理方法
知识图谱中基于统计的推理方法一般指关系机器学习方法。下面介绍一些典型的方法。
1) 实体关系学习方法
实体关系学习的目的是学习知识图谱中实例和实例之间的关系。可以分为潜在特征模型和图特征模型两种。潜在特征模型通过实例的潜在特征来解释三元组。比如说,莫言获得诺贝尔文学奖的一个可能解释是他是一个有名的作家。Nickel 等人给出了一个关系潜在特征模型,称为双线性(bilinear)模型,该模型考虑了潜在特征的两两交互来学习潜在的实体关系。Drumond 等人应用两两交互的张量分解模型来学习知识图谱中的潜在关系。
基于图特征模型的方法从知识图谱中观察到的三元组的边的特征来预测一条可能的边的存在。典型的方法有基于归纳逻辑程序(ILP)的方法,基于关联规则挖掘(ARM)的方法和路径排序(path ranking)的方法。基于ILP的方法和基于 ARM 的方法的共同之处在于通过挖掘的方法从知识图谱中抽取一些规则,然后把这些规则应用到知识图谱上,推出新的关系。而路径排序方法则是根据两个实体间连通路径作为特征来判断两个实体是否属于某个关系。
翻译模型将实体与关系统一映射至低维向量空间中,且认为关系向量中承载了头实体翻译至尾实体的潜在特征。因此,通过发掘、对比向量空间中存在类似潜在特征的实体向量对,我们可以得到知识图谱中潜在的三元组关系。全息嵌入(Holographic Embedding,HolE)模型分别利用圆周相关计算三元组的组合表示及利用圆周卷积从组合表示中恢复出实体及关系的表示。与张量分解模型类似,HolE 可以获得大量的实体交互来学习潜在关系,而且有效减少了训练参数,提高了训练效率。
2) 类型推理(type inference)方法
知识图谱上的类型推理目的是学习知识图谱中的实例和概念之间的属于关系。 SDType利用三元组主语或谓语所连接属性的统计分布以预测实例的类型。该方法可以用在任意单数据源的知识图谱,但是无法做到跨数据集的类型推理。Tipalo与LHD均使用 DBpedia 中特有的 abstract 数据,利用特定模式进行实例类型的抽取。此类方法依赖于特定结构的文本数据,无法扩展到其他知识库。
3) 模式归纳(schema induction)方法
模式归纳方法学习概念之间的关系,主要有基于 ILP 的方法和基于 ARM 的方法。ILP 结合了机器学习和逻辑编程技术,使得人们可以从实例和背景知识中获得逻辑结论。Lehmann等提出用向下精化算子学习描述逻辑的概念定义公理的方法,即从最一般的概念(即顶概念)开始,采用启发式搜索方法使该概念不断特殊化,最终得到概念的定义。Völker 等人介绍了从知识图谱中生成概念关系的统计方法,该方法通过 SPARQL 查询来获取信息,用以构建事务表。然后使用 ARM 技术从事务表中挖掘出一些相关联的概念关系。在他们的后续工作中,使用负关联规则挖掘技术学习不交概念关系,并给出了丰富的试验结果。
4 开放知识图谱
4.1 开放链接知识库
在LOD项目的云图中,Freebase、Wikidata、DBpedia、YAGO这4个大规模知识库处于绝对核心的地位,它们中不仅包含大量的半结构化、非结构化数据,是知识图谱数据的重要来源。而且具有较高的领域覆盖面,与领域知识库存在大量的链接关系。
1) Freebase
Freebase知识库早期由Metaweb公司创建,后来被Google收购,成为Google知识图谱的重要组成部分。Freebase中的数据主要是由人工构建,另外一部分数据则主要来源于维基百科、IMDB、Flickr等网站或语料库。截止到2014年年底,Freebase已经包含了6800万个实体,10亿条关系信息,超过24亿条事实三元组信息,在2015年6月,Freebase整体移入至WikiData。
2) Wikidata
Wikidata是维基媒体基金会主持的一个自由的协作式多语言辅助知识库,旨在为维基百科、维基共享资源以及其他的维基媒体项目提供支持。它是Wikipedia、Wikivoyage、Wikisource中结构化数据的中央存储器,并支持免费使用。Wikidata中的数据主要以文档的形式进行存储,目前已包含了超过1 700万个文档。其中的每个文档都有一个主题或一个管理页面,且被唯一的数字标识。
3) DBpedia
DBpedia是由德国莱比锡大学和曼海姆大学的科研人员创建的多语言综合型知识库,在LOD项目中处于最核心的地位。DBpedia是从多种语言的维基百科中抽取结构化信息,并且将其以关联数据的形式发布到互联网上,提供给在线网络应用、社交网站以及其他在线知识库。由于DBpedia的直接数据来源覆盖范围广阔,所以它包含了众多领域的实体信息。截止至2014年年底,DBpedia中的事实三元组数量已经超过了30亿条。除上述优点外,DBpedia还能够自动与维基百科保持同步,覆盖多种语言。
4) YAGO
YAGO是由德国马普所(max planck institute,MPI)的科研人员构建的综合型知识库。YAGO整合了维基百科、WordNet以及GeoNames等数据源,特别是将维基百科中的分类体系与WordNet的分类体系进行了融合,构建了一个复杂的类别层次结构体系。第一个版本包含了超过100万的实体以及超过500万的事实。2012年,发布了它的第二个版本,在YAGO的基础上进行了大规模的扩展,引入了一个新的数据源GeoNames,被称为YAG02s。包含了超过1 000万的实体以及超过1.2亿的事实。
4.2 垂直行业知识库
行业知识库也可称为垂直型知识库,这类知识库的描述目标是特定的行业领域,通常需要依靠特定行业的数据才能构建,因此其描述范围极为有限。下面将以MusicBrainz、IMDB、豆瓣等为代表进行说明。
1) IMDB
IMDB(internet movie database)是一个关于电影演员、电影、电视节目、电视明星以及电影制作的资料库。截止到2012年2月,IMDB共收集了2 132 383部作品资料和4 530 159名人物资料。IMDB中的资料是按类型进行组织的。对于一个具体的条目,又包含了详细的元信息。
2) MusicBrainz
MusicBrainz是一个结构化的音乐维基百科,致力于收藏所有的音乐元数据,并向大众用户开放。MusicBrainz可通过数据库或Web服务两种方式将数据提供给社区。对于商业用户而言,MusicBrainz提供的在线服务可为用户提供本地化的数据库与复制包。
3) ConceptNet
ConceptNet是一个语义知识网络,主要由一系列的代表概念的结点构成,这些概念将主要采用自然语言单词或短语的表达形式,通过相互连接建立语义联系。ConceptNet包含了大量计算机可了解的世界的信息,这些信息将有助于计算机更好地实现搜索、问答以及理解人类的意图。ConceptNet 5是基于ConceptNet的一个开源项目,主要通过GPLv3协议进行开源。
4.3 中文开放知识图谱联盟
中文开放知识图谱联盟OpenKG旨在推动中文知识图谱的开放与互联,推动知识图谱技术在中国的普及与应用,为中国人工智能的发展以及创新创业做出贡献。联盟已经搭建有OpenKG.CN 技术平台,目前已有 35 家机构入驻。吸引了国内最著名知识图谱资源的加入,如 Zhishi.me,CN-DBPedia,PKUBase,并包含了来自于常识、医疗、金融、城市、出行等15个类目的开放知识图谱。
5 知识图谱的典型应用
知识图谱为互联网上海量、异构、动态的大数据表达、组织、管理以及利用提供了一种更为有效的方式,使得网络的智能化水平更高,更加接近于人类的认知思维。目前,知识图谱已在智能搜索、深度问答、社交网络以及一些垂直行业中有所应用,成为支撑这些应用发展的动力源泉。
5.1 智能搜索
基于知识图谱的智能搜索是一种基于长尾的搜索,搜索引擎以知识卡片的形式将搜索结果展现出来。用户的查询请求将经过查询式语义理解与知识检索两个阶段:1) 查询式语义理解。知识图谱对查询式的语义分析主要包括:①对查询请求文本进行分词、词性标注以及纠错;②描述归一化,使其与知识库中的相关知识进行匹配[114];③语境分析;④查询扩展。明确了用户的查询意图以及相关概念后,需要加入当前语境下的相关概念进行扩展。2) 知识检索。经过查询式分析后的标准查询语句进入知识库检索引擎,引擎会在知识库中检索相应的实体以及与其在类别、关系、相关性等方面匹配度较高的实体。通过对知识库的深层挖掘与提炼后,引擎将给出具有重要性排序的完整知识体系。
智能搜索引擎主要以3种形式展现知识:1) 集成的语义数据。例如当用户搜索梵高,搜索引擎将以知识卡片的形式给出梵高的详细生平,并配合以图片等信息;2) 直接给出用户查询问题的答案。例如当用户搜索“姚明的身高是多少?”,搜索引擎的结果是“226 cm”;3) 根据用户的查询给出推荐列表等。
国外的搜索引擎以谷歌的Google Search、微软的Bing Search最为典型。谷歌的知识图谱相继融入了维基百科、CIA世界概览等公共资源以及从其他网站搜集、整理的大量语义数据,微软的BingSearch和Facebook、Twitter等大型社交服务站点达成了合作协议,在用户个性化内容的搜集、定制化方面具有显著的优势。
搜狗的知立方是国内搜索引擎行业的第一款知识图谱产品,它通过整合互联网上的碎片化语义信息,对用户的搜索进行逻辑推荐与计算,并将最核心的知识反馈给用户。百度将知识图谱命名为知心,主要致力于构建一个庞大的通用型知识网络,以图文并茂的形式展现知识的方方面面。
5.2 深度问答
问答系统是信息检索系统的一种高级形式,能够以准确简洁的自然语言为用户提供问题的解答。在问答系统中同样有查询式理解与知识检索这两个重要的过程,与智能搜索中相应过程中的相关细节是完全一致的。多数问答系统倾向于将给定的问题分解为多个小的问题,然后逐一去知识库中抽取匹配的答案,并自动检测其在时间与空间上的吻合度等,最后将答案合并,以直观的方式展现给用户。
5.3 社交网络
社交网站 Facebook 于2013年推出了Graph Search产品,其核心技术就是通过知识图谱将人、地点、事情等联系在一起,并以直观的方式支持精确的自然语言查询,例如输入查询式:“我朋友喜欢的餐厅”“住在纽约并且喜欢篮球和中国电影的朋友”等,知识图谱会帮助用户在庞大的社交网络中找到与自己最具相关性的人、照片、地点和兴趣等。Graph Search提供的上述服务贴近个人的生活,满足了用户发现知识以及寻找最具相关性的人的需求。
5.4 垂直行业应用
下面将以金融、医疗、电商行业为例,说明知识图谱在其行业中的典型应用。
1) 金融行业
在金融行业中,反欺诈是一个重要的环节。它的难点在于如何将不同税务子系统中的数据整合在一起。通过知识图谱,一方面有利于组织相关的知识碎片,通过深入的语义分析与推理,可对信息内容的一致性充分验证,从而识别或提前发现欺诈行为;另一方面,知识图谱本身就是一种基于图结构的关系网络,基于这种图结构能够帮助人们更有效地分析复杂税务关系中存在的潜在风险。在精准营销方面,知识图谱可通过链接的多个数据源,形成对用户或用户群体的完整知识体系描述,从而更好地去认识、理解、分析用户或用户群体的行为。
2) 医疗行业
耶鲁大学拥有全球最大的神经科学数据库Senselab,然而,脑科学研究还需要综合从微观分子层面一直到宏观行为层面的各个层次的知识。因此,耶鲁大学的脑计划研究人员将不同层次的,与脑研究相关的数据进行检索、比较、分析、整合、建模、仿真,绘制出了描述脑结构的神经网络图谱,从而解决了当前神经科学所面临的海量数据问题,从微观基因到宏观行为,从多个层次上加深了人类对大脑的理解,达到了“认识大脑、保护大脑、创造大脑”的目标。
3) 电商行业
电商网站的主要目的之一就是通过对商品的文字描述、图片展示、相关信息罗列等可视化的知识展现,为消费者提供最满意的购物服务与体验。通过知识图谱,可以提升电商平台的技术性、易用性、交互性等影响用户体验的因素。
除此之外,另外一些垂直行业也需要引入知识图谱,如教育科研行业、图书馆、证券业、生物医疗以及需要进行大数据分析的一些行业。这些行业对整合性和关联性的资源需求迫切,知识图谱可以为其提供更加精确规范的行业数据以及丰富的表达,帮助用户更加便捷地获取行业知识。
6 知识图谱面临的挑战
知识图谱技术是对语义网标准与技术的一次扬弃与升华,但知识图谱中的知识获取、知识表示、知识推理等技术依然面临着一些困难与挑战,很多重要的开放问题急待学术界与工业界协力来解决。在未来的几年时间内,知识图谱仍将是大数据智能的前沿研究问题。
6.1 知识获取
知识抽取是知识图谱组织构建、进行问答检索的主要任务,对于深层语义的理解以及处理具有重要的意义。一些传统的知识元素(实体、关系、属性)抽取技术与方法,它们在限定领域、主题的数据集上获得了较好的效果,但由于制约条件较多,方法的可扩展能力不够强,未能很好地适应大规模、领域独立、高效的开放式信息抽取要求。目前,基于大规模开放域的知识抽取研究仍处于起步阶段,尚需研究者努力去攻关开垦。
KnowItAll、TextRunner、WOE、ReVerb、R2A2、KPAKEN这些系统已为开放域环境下,实体关系抽取中的二元关系抽取、n元关系抽取发展开创了先河,具有广阔的研究前景。再者,对于隐含关系的抽取,目前主流的开放式信息抽取方法性能低下或尚无法实现。因此,以马尔可夫逻辑网、本体推理的联合推理方法将成为学术界的研究热点。联合推理方法不仅能够推断文本语料所不能显示的深层隐含信息,还能够综合信息抽取各阶段的子任务,像杠杆一样在各方面之间寻求平衡,以趋向整体向上的理想效果,为大规模开放域下的知识抽取提供了一种新的思路。另外,跨语言的知识抽取方法也成为了当前的研究热点。
6.2 知识表示
知识表示对知识图谱的构建、推理、融合以及应用均具有重要的意义。目前存在的表示方式仍是基于三元组形式完成的语义映射,在面对复杂的知识类型、多源融合的信息时,其表达能力仍然有限。因此有研究者提出,应针对不同的应用场景设计不同的知识表示方法。
1) 复杂关系中的知识表示
已有的工作将知识库中的实体关系类型分为1-to-1、1-to-N、N-to-1、N-to-N这4种,这种划分方法无法直观地解释知识的本质类型特点,也无法更有针对性地表示复杂关系中的知识。但发现分布式的知识表示方法来源于认知科学,具有灵活的可扩展能力。基于上述,对认知科学领域人类知识类型的探索将有助于知识类型的划分、表示以及处理,是未来知识表示研究的重要发展方向。
2) 多源信息融合中的知识表示
对于多源信息融合中的知识表示研究尚处于起步阶段,涉及的信息来源也极为有限,已有的少数工作都是围绕文本与知识库的融合而展开的。另外,文献将注意力转向面向关系表示的多源信息融合领域,并已在CNN上进行了一定的实现。
6.3 知识融合
知识融合对于知识图谱的构建、表示均具有重要的意义。实体对齐是知识融合中的关键步骤,虽然相关研究已取得了丰硕的成果,但仍有广阔的发展空间。下面将具体说明实体对齐在大规模知识库环境下所遇到的挑战以及未来的研究方向。
1) 并行与分布式算法
大规模的知识库不仅蕴含了海量的知识,其结构、数据特征也极其复杂,这些对知识库实体对齐算法的准确率、执行效率提出了一定的挑战。目前,不少研究者正着力研究对齐算法的并行化或分布式版本,在兼顾算法准确率与召回率的同时,将进一步利用并行编程环境MPI,分布式计算框架Hadoop、Spark等平台,提升知识库对齐的整体效果。
2) 众包算法
人机结合的众包算法可以有效地提高知识融合的质量。众包算法的设计讲求数据量、知识库对齐质量以及人工标注三者的权衡。将众包平台与知识库对齐模型有机结合起来,并且能够有效判别人工标注的质量,这些均具有较为广阔的研究前景。
3) 跨语言知识库对齐
多语言的知识库越来越多,多语言知识库的互补能力将为知识图谱在多语言搜索、问答、翻译等领域的实际应用提供更多的可能。WANG Z已在这方面取得了一定的进展,但知识库对齐的质量不高,这方面仍有广阔的研究空间。
知识加工是形成高质量知识的重要途径,其中本体自动构建、本体抽取、本体聚类等问题是目前的研究热点。在知识质量评估方面,构建完善的质量评估技术标准或指标体系是该领域未来的研究目标。而增量更新技术将是知识图谱未来实现自动化更新的重要研究方向。如何确保自动化更新的有效性,是更新过程中面临的又一重大挑战。
6.4 知识应用
目前,大规模知识图谱的应用场景和方式还比较有限,其在智能搜索、深度问答、社交网络以及其他行业中的使用也只是处于初级阶段,仍具有广阔的可扩展空间。人们在挖掘需求、探索知识图谱的应用场景时,应充分考虑知识图谱的以下优势:1) 对海量、异构、动态的半结构化、非结构化数据的有效组织与表达能力;2) 依托于强大知识库的深度知识推理能力;3) 与深度学习、类脑科学等领域相结合,逐步扩展的认知能力。在对知识图谱技术有丰富积累的基础上,敏锐的感知人们的需求,可为大规模知识图谱的应用找到更宽广、更合适的应用之道。
[1] 刘峤 李杨.知识图谱构建技术综述[J].计算机研究与发展,2016,53(3):582-600
[2] 李涓子 侯磊.知识图谱研究综述[A].山西大学学报(自然科学版),2017,40(3):454-459
[3] 漆桂林 高桓.知识图谱研究进展[J].情报工程,2017年第3卷第1期:4-25
[4] 徐增林 盛泳潘.知识图谱技术综述[A].电子科技大学学报,2016 Vol.45 No.4
[5] 张萌.课程知识图谱组织与搜索技术研究[D].武汉:武汉大学,2016,3-5