
文章目录
- Recap: LMs and decoding algorithms
- NLG tasks and neural approaches to them
- 摘要
- 对话 Dialogue
- Storytelling
- Generating a story from an image
- Generating a story from a writing prompt
- Challenges in storytelling
- Event2event Story Generation
- Structured Story Generation
- Poetry generation
- Non-autoregressive generation for NMT
- NLG evaluation
- Thoughts on NLG research, current trends, and the future
- Exciting current trends in NLG
- Neural NLG community is rapidly maturing
- 8 things I’ve learnt from working in NLG
- Bizarre conversations between me and my chatbot
- 总结
Recap: LMs and decoding algorithms
Natural Language Generation (NLG)
- 自然语言生成是指我们生成(即编写)新文本的任何设置。
- NLG是以下任务的子组件:
- 机器翻译
- 摘要
- 对话(闲聊和任务型)
- 创意写作:讲故事,诗歌创作
- 自由问答(答案是产生的,而不是从文本或知识库中抽取的)
- 图像字幕
- ···
LM
- 给出目前已知的词序列,预测下一个词
- 产生这个概率分布的系统叫做语言模型
- 如果这个系统是一个RNN,那么就被称为RNN-LM
ConditionalLanguage Modeling
- 给定目前已知的词序列,并且还有一些其他输入
,预测下一个词
- 条件语言模型任务的例子
- 机器翻译(x = source sentence, y = target sentence)
- 摘要(x = input text, y = summarized text)
- 对话(x = dialogue history, y = next utterance)
- ···
training a (conditional) RNN-LM
例子:Neural Machine Translation

在训练时,解码时将gold(aka reference)target sentence 作为输入,而不管解码器预测的结果,这种训练方法叫做 Teacher Forcing
decoding algorithms
- 问题:一旦训练好(条件)语言模型,如何用它生成为本?
- 答案:解码算法就是一种用来从语言模型中生成文本的算法
- 我们已经学过两种解码算法
- Greedy decoding
- Beam search
greedy decoding
- 一种简单的算法
- 在每个时间步,选择概率最大的单词(i.e. argmax)
- 将其作为下一个单词,并输入到下一个时间步
- 直到产生<END>(或达到最大长度)停止

- 由于缺乏回溯,输出可能很差(比如,不和语法,不自然,无意义)
beam search decoding
- 一个搜索算法,通过同时跟踪多个可能的句子来在找到概率较高的概率(尽管不一定是最优的)
- 核心思想:在解码的每个时间步,跟踪概率最高的k个部分句子(我们称之为假设)
- k 是beam size
- 当达到某些停止规则时,选择概率最高的句子(根据句子长度对概率调整后)

What’s the effect of changing beam size k? - 较小的 k 会出现ugreedy decoding(k = 1)相同的问题
- 不合语法,不自然,无意义,不正确
- 较大的 k 意味着可以考虑更多的假设
- 增加 k 减少了上述的问题
- 更大的 k 需要更多的计算
- 但增加 k 会引入一些其他问题
- 对于 NMT,增加 k 太多会减小BLEU分数(Tu et al, Koehn et al),这主要是因为large-k beam search会产生非常短的翻译(即使是分数标准化!)
- 在诸如聊天对话之类的开放式任务中,更大的k可以使输出更通用(请参见下一张幻灯片)
Effect of beam size in chitchat dialogue

Sampling-based decoding
- 纯采样
- 在每一步 t ,从概率分布 中随机抽样以获得下一个单词
- 像 greedy decoding一样,但是是采样而不是argmax
- Top-n sampling
- 在每一步 t ,从概率分布 中的前n个最有概率的单词中随机抽样
- 像纯采样一样,但截断概率分布
- n = 1 是greedy search,n = V 是纯采样
- 增加 n 获得更多样/冒险的输出
- 减小 n 获得更泛化/安全的输出
- 这两种比beam seatch更加有效,因为不用跟踪多个假设
Softmax temperature
- 复习:在时间步 t,语言模型通过softmax计算向量
的概率分布
- 你可以将温度(temperature)超参数
应用于 softmax:
- 提高KaTeX parse error: Undefined control sequence: \tao at position 1: \̲t̲a̲o̲:
变得更均匀
- 因此输出更加多样化(概率分布在整个词表中)
- 降低KaTeX parse error: Undefined control sequence: \tao at position 1: \̲t̲a̲o̲:
变得更尖锐
- 因此输出多样性较小(概率集中在顶层词汇上)
- 注:softmax temperature 不是一种解码算法
这是一种可以在测试时应用的技术,与解码算法(如波束搜索或采样)结合使用
Decoding algorithms: in summary
- Greedy decoding 是一种简单的方法;输出的质量较低
- Beam search(尤其是beam size较大时)搜索高概率输出
- 提供比贪心更好的质量,但如果beam search太大,可能会返回高概率但不合适的输出(例如通用、短)
- Sampling methods是一种获得多样性和随机性的方法
- 适合开放式/创造性的生成(诗歌、故事)
- Top-n sampling允许你来控制多样性
- Softmax temperature是另一种控制多样性的方法
- 它不是解码算法!它是一种可以和解码算法一起使用的技巧
NLG tasks and neural approaches to them
摘要
任务定义
任务:给出输入文本 x,写出一个较短的并且包含 x 主要信息的 y
摘要可以是单文档或者多文档的
- 单文档意味着我们写出一个单个文档 x 的总结 y
- 多文档意味着我们要写出多个文档 的总结 y
- 通常 有重叠的内容:例如关于同一事件的新闻文章
- 在单个文档摘要中,存在具有不同长度和样式的源文档的数据集:
- Gigaword:新闻文章的前一两句话→标题(又称句子压缩)
- LCSTS(中国微博):段落→单句摘要
- NYT,CNN/DailyMail:新闻文章→(多)句摘要
- Wikihow(新的):完整的指导文章→总结句
句子简化(Sentence simplification)是一个不同但相关的任务:
以更简单(有时更短)的方式重写源文本
- Simple Wikipedia:标准Wikipedia句子→简单版本
- Newsela:新闻文章→儿童版
List of summarization datasets, papers, and codebases: https://github.com/mathsyouth/awesome-text-summarization
两个主要策略
- 抽取型摘要(Extractive summarization)
选择原文的部分(通常是句子)形成摘要。- 更简单
- 限制性(无释义)
- 抽象式摘要(Abstractive summarization)
使用自然语言生成技巧生成新文本- 更难
- 更灵活(更人性化)
Pre-neural summarization

- 在神经网络之前,摘要系统主要是抽取式的
- 与神经网络之前的MT一样,它们通常有一条管道:
- 内容选择:选择一些句子
- 信息排序:为这些句子排序
- 句子实现:编辑句子序列(例如简化、删除部分、修复连续性问题)
- 句子评分功能基于:
- 存在主题关键字,通过例如tf idf计算
- 句子出现在文档中的位置等特征
- 基于图的算法将文档视为一组句子(节点),每个句子对之间有边
- 边缘权重与句子相似度成正比
- 使用图算法识别图中的中心句子
Summarization evaluation: ROUGE
ROUGE(Recall-Oriented Understudy for GistingEvaluation)

- 像 BLEU一样,它是基于n-gram重叠的。两者区别如下:
- ROUGE没有简短惩罚
- ROUGE基于召回率,而BLEU基于准确率
- 可以说,精确性对MT更为重要(然后加上简洁性惩罚以修复翻译不足),而召回率对于摘要更为重要(假设您有最大长度限制)
- 然而,无论如何,通常都会报告F1(精确性和召回率的组合)版本的分数
- BLEU是一个单一的数字,它是n=1,2,3,4 n-grams的精度的组合
- 对于每个n-gram分别计算ROUGE评分
- 最常用的ROUGE分数如下:
- ROUGE-1:unigram overlap
- ROUGE-2: bigram overlap
- ROUGE-L: longest common subsequence overlap
- 有一个简便的ROUGE的Python实现:https://github.com/google-research/google-research/tree/master/rouge
Neural summarization (2015 -present)
-
2015: Rush et al. 发布第一篇seq2seq摘要的论文
-
单文档抽象性摘要是一个翻译任务
-
因此我们可以使用标准seq2seq + attention NMT 模型

A Neural Attention Model for Abstractive Sentence Summarization, Rush et al, 2015 https://arxiv.org/pdf/1509.00685.pdf -
从2015年开始,有很多的发展
- 使其更容易复制
- 同时也避免太多的复制
- 分层/多层次的注意力机制
- 更多的 全局/高级 的内容选择
- 使用 RL(强化学习) 直接最大化 ROUGE 或者其他离散目标(例如长度)
- 恢复 pre-neural 思想(如内容选择的图形算法)并将其应用到神经系统中
- 使其更容易复制
List of summarization datasets, papers, and codebases: https://github.com/mathsyouth/awesome-text-summarization
A Survey on Neural Network-Based Summarization Methods, Dong, 2018 https://arxiv.org/pdf/1804.04589.pdf
copy mechanisms
- Seq2seq+attention 系统很擅长写出流利的输出,但不擅长正确地复制细节(如罕见的单词)
- 复制机制使用 attention 使 seq2seq 系统能够轻松地将单词和短语从输入复制到输出
- 很明显这对摘要很有用
- 允许复制和生成提供了一种混合的 提取/抽象 方法
- 有几篇论文提出了复制机制的变体:
- Language as a Latent Variable: Discrete Generative Models for Sentence Compression, Miao et al, 2016 https://arxiv.org/pdf/1609.07317.pdf
- Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond, Nallapatiet al, 2016 https://arxiv.org/pdf/1602.06023.pdf
- Incorporating Copying Mechanism in Sequence-to-Sequence Learning, Gu et al, 2016 https://arxiv.org/pdf/1603.06393.pdf
一个复制机制的例子

在解码的每个时间步,计算
,这是产生下一个单词的概率(而不是复制它),最终的分布是生成(也称为“词表”)分布和复制(即注意)分布的混合:
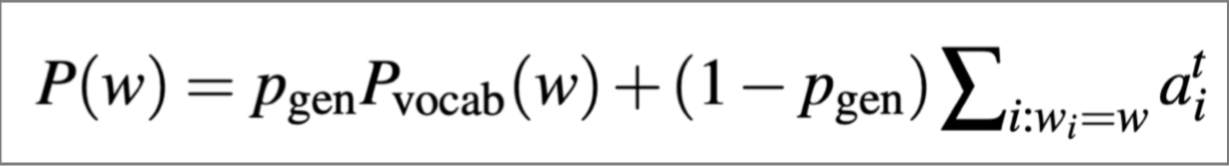
Summarization with Pointer-Generator Networks, See et al, 2017 https://arxiv.org/pdf/1704.04368.pdf
复制机制出现了一些问题
- 复制的太多了
- 大多数是长的短语,有时甚至是整个句子
- 本应是抽象系统,结果可能会崩溃成一个主要是抽取系统。
- 另一个问题
- 它们不善于选择整体内容,尤其是当输入文档很长时
- 没有选择内容的总体策略
better content selection
- 回忆:神经系统前的总结对于内容选择和表面实现(即文本生成)有单独的阶段
- 在一个标准的 seq2seq + attention 摘要系统内,这两个阶段混合在一起
- 在解码的每一步(即表面实现),我们实现了词汇级别内容的选择(attention)
- 这不好:没有全局内容选择策略
- 一个解决方法:自下向上摘要
Bottom-up summarization
- 内容选择阶段:使用一个神经序列标注模型来将单词标注为 include / don’t-include
- 自下向上注意力阶段:seq2seq + attention 系统不能处理 don’t-include 的单词(使用 mask )

Bottom-Up Abstractive Summarization, Gehrmannet al, 2018 https://arxiv.org/pdf/1808.10792v1.pdf
简单但是有效!
- 更好的整体内容选择策略
- 减少长序列的复制(即更摘要的输出)
- 因为长序列中包含了很多 don’t-include 的单词,所以模型必须学会跳过这些单词并将那些 include 的单词进行摘要与组合
Neural summarization via Reinforcement Learning
- 2017年,Paulus et al 发表了一个"deep reinforced"摘要模型
- 主要思想:使用强化学习(RL)直接优化ROUGE-L分数
- 相比之下,标准的最大似然(ML)训练不能直接优化ROUGE-L,因为它是一个不可微函数

A Deep Reinforced Model for Abstractive Summarization, Paulus et al, 2017 https://arxiv.org/pdf/1705.04304.pdf
Blog post: https://www.salesforce.com/products/einstein/ai-research/tl-dr-reinforced-model-abstractive-summarization/
- 相比之下,标准的最大似然(ML)训练不能直接优化ROUGE-L,因为它是一个不可微函数
对话 Dialogue
“对话”包含多种设置:
- 任务导向型对话
- 辅助(例如,客户服务、提供建议、回答问题、帮助用户完成购买或预订等任务)
- 合作(两名代理人通过对话解决任务)
- 对抗性(两个代理通过对话在一个任务中竞争)
- 社会性对话
- 闲聊(为了娱乐或陪伴)
- 治疗 / 精神健康
Pre-and post-neural dialogue
- 由于开放式自由形式NLG的困难,pre-neural 对话系统更常使用预先定义的模板,或者从一个反应语料库中检索适当的回复。
- 在总结研究中,自2015年以来,有许多论文将seq2seq方法应用到对话中,从而使人们对开放式自由形式对话系统产生了新的兴趣
- 一些早期的seq2seq文章包括
- A Neural Conversational Model, Vinyalset al, 2015
https://arxiv.org/pdf/1506.05869.pdf - Neural Responding Machine for Short-Text Conversation, Shang et al, 2015 https://www.aclweb.org/anthology/P15-1152
- A Neural Conversational Model, Vinyalset al, 2015
- 这是最近(主要是神经)对话人工智能工作的一个很好的概述:
https://medium.com/gobeyond-ai/a-reading-list-and-mini-survey-of-conversational-ai-32fceea97180
Seq2seq-based dialogue
然而,很快就发现,标准seq2seq+attention方法的简单应用对于(闲聊)对话具有严重的普遍缺陷:
- 一般性/无聊的回复
- 无关的回复(与上下文不够相关)
- 重复
- 缺乏上下文(不记得谈话历史)
- 缺乏一致的角色人格
Irrelevant response problem
问题:seq2seq经常产生与用户无关的话语
- 要么因为它是通用的(例如,“我不知道”)
- 或因为改变话题为无关的一些事情
一个解决方法:优化输入与响应T之间的最大互信息(MMI),而之前是给定 S 下生成概率最高的回复 T,这就会导致产生一些本来概率就很大的句子用于回复
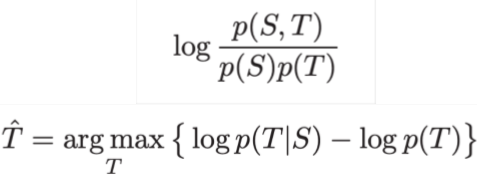
A Diversity-Promoting Objective Function for Neural Conversation Models, Li et al, 2016 https://arxiv.org/pdf/1510.03055.pdf
Genericness/ boring response problem
-
简单的测试时修复
- 直接在Beam搜索中增大罕见字的概率
- 使用抽样解码算法而不是Beam搜索
-
条件修复
- 用一些额外的内容训练解码器(如抽样一些内容词并处理)
- 训练 retrieve-and-refine 模型而不是 generate-from-scratch 模型
- 即从语料库采样人类话语并编辑以适应当前的场景
- 这通常产生更加多样化/人类/有趣的话语!
-
Why are Sequence-to-Sequence Models So Dull?, Jiang et al, 2018
https://staff.fnwi.uva.nl/m.derijke/wp-content/papercite-data/pdf/jiang-why-2018.pdf
Repetition problem
简单的解决方法:
- 直接在 Beam 搜索中禁止重复n-grams
- 通常非常有效
更复杂的解决方案
- 在seq2seq中训练覆盖机制,这是一个防止注意机制多次注意同一单词的目标。
- 定义训练目标以阻止重复
- 如果这是一个不可微函数生成的输出,然后将需要一些技术例如RL来训练
Lack of consistent persona problem
缺乏一致的人物角色问题
- 2016年,Li等人提出了seq2seq对话模型,该模型学习将对话双方的角色编码为嵌入
- 生成的话语是以嵌入为条件的
- 最近,有一个叫做PersonaChat的聊天数据集,它包括每次对话的人物角色(5个描述个人特征的句子的集合)。
- 这提供了一种轻量级的基础,使研究人员能够构建角色条件对话代理
A Persona-Based Neural Conversation Model, Li et al 2016, https://arxiv.org/pdf/1603.06155.pdf
Personalizing Dialogue Agents: I have a dog, do you have pets too?, Zhang et al, 2018 https://arxiv.org/pdf/1801.07243.pdf
Negotiation dialogue
2017,Lewis等人收集了一个谈判对话数据集
- 两个代理(通过自然语言)协商如何划分一些东西。
- 代理对东西具有不同的价值功能。
- 代理在达成协议前一直在交谈。

Deal or No Deal? End-to-End Learning for Negotiation Dialogues, Lewis et al, 2017 https://arxiv.org/pdf/1706.05125.pdf - 他们发现用标准的最大似然(ML)来训练seq2seq系统的产生了流利但是缺乏策略的对话代理
- 和Paulus等的摘要论文一样,他们使用强化学习来优化离散奖励(代理自己在训练自己)
- RL 的基于目的的目标函数与 ML 目标函数相结合
- 潜在的陷阱:如果两两对话时,代理优化的只是RL目标,他们可能会偏离英语(不满足语法)

在测试时,模型通过计算 rollouts,选择可能的反应:模拟剩余的谈话和预期的回报
- 2018年,Yarats 等提出了另一个谈判任务的对话模型,将策略和NLG方面分开
- 每个话语 都有一个对应的离散潜在变量
- 学习成为一个很好的预测对话中的未来事件的预测器(未来的消息,策略的最终收获),但不是 本身的预测器
- 这意味着 学会代表 对对话的影响,而不是 的话
- 因此 将任务的策略方面从 NLG方面分离出来,这对可控制性、可解释性和更容易学习策略等是有用的

Hierarchical Text Generation and Planning for Strategic Dialogue, Yarats et al, 2018 https://arxiv.org/pdf/1712.05846.pdf
Conversational question answering: CoQA

CoQA: a Conversational Question Answering Challenge, Reddy et al, 2018 https://arxiv.org/pdf/1808.07042.pdf
- 一个来自斯坦福NLP的新数据集
- 任务:回答关于以一段对话为上下文的文本的问题
- 答案必须具有摘要性(而不是复制)
- QA / 阅读理解任务,和对话任务
Storytelling
-
神经讲故事的大部分工作使用某种提示
- 给定图像,生成故事情节段落
- 给定一个简短的写作提示,生成一个故事
- 给定迄今为止的故事,生成故事的下一个句子(故事续写)
这和前两个不同,因为我们不关心系统在几个生成的句子上的性能
-
神经网络生成故事飞速发展
- 第一个故事研讨会于2018年举行
- 它举行比赛(使用五张图片的序列生成一个故事)
Storytelling Workshop 2019: http://www.visionandlanguage.net/workshop2019/
Generating a story from an image

有趣的是,这不是直接的监督图像字幕(supervised image-captioning)。没有可供学习的配对数据。
Generating Stories about Images, https://medium.com/@samim/generating-stories-about-images-d163ba41e4ed
问题:如何解决缺乏并行数据的问题
回答:使用一个通用的 sentence-encoding space
Skip-Thought Vectors, Kiros2015, https://arxiv.org/pdf/1506.06726v1.pdf
- Skip-thought 向量是一种通用的句子嵌入方法
- 想法类似于我们如何学通过预测其周围的单词来学习单词的嵌入
- 使用 COCO (图片标题数据集),学习从图像到其标题的 Skip-thought 编码的映射
- 使用目标样式语料库(Taylor Swift lyrics),训练一个RNN-LM来将Skip-thought向量解码为原文
- 把两个结合在一起
Generating a story from a writing prompt
- 2018年,Fan 等发布了一个新故事生成数据集 collected from Reddit’s WritingPrompts subreddit.
- 每个故事都有一个相关的简短写作提示

Fan 等也提出了一个复杂的 seq2seq prompt-to-story 模型
Hierarchical Neural Story Generation, Fan et al, 2018 https://arxiv.org/pdf/1805.04833.pdf - 基于卷积
- 这使得比基于RNN的seq2seq快
- 门控的多头多尺度自注意力
- self-attention 对捕获远程上下文而言十分重要
- 门控允许更有选择性的注意机制
- 不同的注意力头集中在不同的尺度上——这意味着有不同的注意力机制专门用于检索细粒度信息和粗粒度信息
- 模型融合
- 预训练一个seq2seq模型,然后训练第二个 seq2seq 模型访问的第一个 model 的隐状态
- 想法是,第一个seq2seq模型学习通用LM,第二个model学习基于提示的条件
结果令人印象深刻
- 与提示相关
- 多样化,并不普通
- 在文体上戏剧性

但是
- 主要是氛围/描述性/场景设定,很少是事件/情节
- 生成更长时,大多数停留在同样的想法并没有产生新的想法——一致性问题
Challenges in storytelling
由神经LM生成的故事听起来流畅…但是是曲折的,荒谬的,情节不连贯的
缺失的是什么?
LMs对单词序列进行建模。故事是事件序列
- 为了讲一个故事,我们需要理解和模拟
- 事件和它们之间的因果关系结构
- 人物,他们的个性、动机、历史、和其他人物之间的关系
- 世界的状态(谁、是什么、在哪里和为什么)
- 叙事结构(如说明 → 冲突 → 解决)
- 良好的叙事原则(不要引入一个故事元素然后从未使用它)
Event2event Story Generation


Event Representations for Automated Story Generation with Deep Neural Nets, Martin et al, 2018 https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/17046/15769
Structured Story Generation

Strategies for Structuring Story Generation, Fan et al, 2019 https://arxiv.org/pdf/1902.01109.pdf
Tracking events, entities, state, etc.
- 旁注:在神经NLU(自然语言理解)领域,已经有大量关于跟踪事件/实体/状态的工作
- 例如,Yejin Choi’s group 在这一领域做了很多工作
- 将这些方法应用到 NLG是更加困难的
- 如果你缩小范围,则更可控的
- 不采用自然语言生成开放域的故事,而是跟踪状态
- 在跟踪因素的状态中,生成一个recipe(基于给定的因素)
Tracking world state while generating a recipe
- 神经过程网络:基于 ingrdients 来生成 recipe instructions
- 显式地跟踪所有 ingredients 的状态,并用它来决定下一步要采取什么行动。

Simulating Action Dynamics with Neural Process Networks, Bosselutet al, 2018 https://arxiv.org/pdf/1711.05313.pdf
Poetry generation
Hafez
- Hafez:Ghazvininejad et al 的诗歌系统
- 主要思想:使用一个有限状态接收器(FSA)来定义所有可能的序列,服从希望满足的节奏约束。然后使用FSA约束RNN-LM的输出
例如
- 莎士比亚的十四行诗是14行的iambic pentameter
- 所以莎士比亚的十四行诗的FSA是
- 在Beam搜索解码中,只探索属于FSA的假设
Generating Topical Poetry, Ghazvininejadet al, 2016 http://www.aclweb.org/anthology/D16-1126
Hafez: an Interactive Poetry Generation System, Ghazvininejadet al, 2017 http://www.aclweb.org/anthology/P17-4008

- 全系统
- 用户提供主题字
- 得到一个与主题相关的词的集合
- 识别押韵主题词。这是每一行的结尾
- 使用受制于FSA的RNN-LM生成这首诗
- RNN-LM向后(自右向左)。这是必要的,因为每一行的最后一个词是固定的。
在后续的论文中,作者制作了一个交互式并且用户能够控制的系统
控制方法很简单:在 beam search 中,增大具有期望特征单词的分数

Poetry generation: Deep-speare
一种更加端到端的诗歌生成方法(Lau等人)
Deep-speare: A joint neural model of poetic language, meter and rhyme, Lau et al, 2018 http://aclweb.org/anthology/P18-1181
三个组件
- 语言模型
- pentameter(五音步诗律) model
- rhyme model 韵律模型……
作为一个多任务学习问题共同学习
- 作者发现 meter 和押韵是相对容易的,但生成的诗歌上有些缺乏“情感和可读性”

Non-autoregressive generation for NMT
- 2018年,Gu等人发表了一个“Non-autoregressive Neural Machine Translation”模型 https://arxiv.org/pdf/1711.02281.pdf
- 意义:它不是根据之前的每个单词,从左到右产生翻译
- 它并行生成翻译
- 这具有明显的效率优势,但从文本生成的角度来看也很有趣
- 架构是基于Transformer 的;最大的区别是,解码器可以运行在测试时并行

NLG evaluation
Automatic evaluation metrics for NLG
基于词重叠的指标(BLEU,ROUGE,METROR,F1,等等)
- 我们知道他们不适合机器翻译
- 对于摘要而言是更差的评价标准,因为摘要比机器翻译更开放
- 不幸的是,与抽象摘要系统相比,抽取摘要系统更受ROUGE青睐
- 对于对话甚至更糟,这比摘要更开放
- 类似的例子还有故事生成
Word overlap metrics are not good for dialogue

How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation, Liu etal,2017 https://arxiv.org/pdf/1603.08023.pdf

Why We Need New Evaluation Metrics for NLG, Novikovaet al, 2017 https://arxiv.org/pdf/1707.06875.pdf
-
迷惑度如何?
- 捕捉你的LM有多强大,但不告诉你关于生成的任何事情(例如,如果你的解码算法不好,困惑是不受影响的)
-
词嵌入基础指标?
- 主要思想:比较词嵌入的相似度(或词嵌入的均值),而不仅仅是单词的重叠。以更灵活的方式捕获语义。
- 不幸的是,仍然没有与类似对话的开放式任务的人类判断,产生很好的联系
-
我们没有自动指标充分捕捉整体质量(即代表人类的质量判断)
-
但我们可以定义更多的集中自动度量来捕捉生成文本的特定方面
- 流利性(使用训练好的LM计算概率)
- 正确的风格(使用目标语料库上训练好的LM的概率)
- 多样性(罕见的用词,n-grams 的独特性)
- 相关输入(语义相似性度量)
- 长度和重复
- 特定于任务的指标,如摘要的压缩率
-
虽然这些不衡量整体质量,他们可以帮助我们跟踪一些我们关心的重要品质
Human evaluation
- 人类的判断被认为是黄金标准
- 当然,我们知道人类评价是缓慢而昂贵的
- 但这是仅有的问题吗?
- 假如你能达到人类的评估:人类评估解决了你所有的问题吗?
- 不!
- 进行人类有效评估非常困难
- 人类
- 是不一致的
- 可能是不合逻辑的
- 失去注意力
- 误解了你的问题
- 不能总是解释为什么他们会这样做
Detailed human eval of controllable chatbots
详细的人类评估可控聊天机器人
-
在聊天机器人项目(PersonaChat)工作的个人经验:
-
我们研究了可控性(特别是对生成的话语的控制方面,如重复性、特异性、反应相关性和提问)。

What makes a good conversation? How controllable attributes affect human judgments, See et al, 2019 https://arxiv.org/pdf/1902.08654.pdf -
如何要求人的质量判断?
-
我们尝试了简单的整体质量(多项选择)问题,例如:
- 这次对话有多好?
- 这个用户有多吸引人?
- 这些用户中哪一个给出了更好的响应?
- 您想再次与该用户交谈吗?
- 您认为该用户是人还是机器人?
-
主要问题:
- 必然非常主观
- 回答者有不同的期望;这会影响他们的判断
- 对问题的灾难性误解(例如“聊天机器人非常吸引人,因为它总是回写”)
- 总体质量取决于许多潜在因素;他们应该如何被称重和/或比较?
最终,我们设计了一个详细的人类评估系统,将影响聊天机器人整体质量的重要因素分离出来:

What makes a good conversation? How controllable attributes affect human judgments, See et al, 2019 https://arxiv.org/pdf/1902.08654.pdf
- 发现:
- 控制重复对于所有人类判断都非常重要
- 提出更多问题可以提高参与度
- 控制特异性(较少的通用话语)提高了聊天机器人的吸引力,趣味性和感知的听力能力。
- 但是,人类评估人员对风险的容忍度较低(例如无意义或非流利的输出)与较不通用的机器人相关联
- 总体度量“吸引力”(即享受)很容易最大化 - 我们的机器人达到了近乎人性化的表现
- 整体度量“人性化”(即图灵测试)根本不容易最大化 - 所有机器人远远低于人类表现
- 人性化与会话质量不一样!
- 人类是次优的会话主义者:他们在有趣,流利,倾听上得分很低,并且问的问题太少
Possible new avenues for NLG eval
NLG评估的可能新途径
- 语料库级别的评价指标
- 评估指标应该独立地应用于测试集中的每个样例,还是应用于整个语料库的函数?
- 例如,如果对话模型对测试集中的每一个例子回答相同的通用答案,它应该被惩罚
- 评估衡量多样性安全权衡的评估指标
- 免费的人类评估
- 游戏化:使任务(例如与聊天机器人交谈)变得有趣,这样人类就可以为免费提供监督和隐式评估,作为评估指标
- 对抗性鉴别器作为评价指标
- 测试NLG系统是否能愚弄经过训练能够区分人类文本和AI生成的文本的识别器
Thoughts on NLG research, current trends, and the future
Exciting current trends in NLG
- 将离散潜在变量纳入NLG
- 可以帮助在真正需要它的任务中建模结构,例如讲故事,任务导向对话等
- 严格的从左到右生成的替代方案
- 并行生成,迭代细化,自上而下生成较长的文本
- teacher forcing 是最大似然训练的另一种选择
- 更全面的句子级别的目标函数(而不是单词级别)

Neural NLG community is rapidly maturing
- 在NLP+深度学习的早期,社区主要是将成功的NMT方法转化为NLG任务。
- 现在,越来越多的创造性的NLG技术出现,特别是非NMT生成设置。
- 越来越多的(神经)NLG研讨会和比赛,特别是针对开放式NLG:
- NeuralGen workshop
- Storytelling workshop
- Alexa challenge
- ConvAI2 NeurIPS challenge
- 这些对于组织社区、提高再现性、标准化评估特别有用
- 最大障碍是评估
8 things I’ve learnt from working in NLG
- 任务越开放,一切就越困难。
约束有时是受欢迎的 - 针对某一特定改进的目标要比旨在提高整体生成质量的目标更易于实现。
- 如果你使用NLG的LM:改进LM(即困惑度)将极有可能提高生成质量。
但这并不是提高生成质量的唯一途径。 - 多看看你的输出
- 你需要一个自动的度量,即使它不完美。
你或许需要几个自动度量 - 如果你做人类评估,让问题尽可能集中。
- 再现性是当今NLP+深度学习中的一个大问题,也是NLG中一个更大的问题。
请公开发布你所有的输出与你的论文! - 在NLG领域工作会很令人沮丧。但也很有趣…
Bizarre conversations between me and my chatbot
我和聊天机器人之间奇怪的对话

总结
- 语言模型
- 条件性语言模型:MT、摘要、对话
- 解码算法
- Greedy decoding
- Beam search:beam size变化,会引起哪些效果
- Sampling-based decoding
- Pure sampling
- Top-n sampling:n = 1就是greedy search, n = V 就是pure sampling
- 一种解码技巧:sotmax temperature
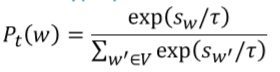
增大 : 变得更均匀,因此输出更多样
减小 ,效果相反,输出多样i性减小
各种NLG任务,和神经网络方法
-
摘要
- 单文档、多文档
- 抽取式、抽象式
- 神经网络前大多是管道方法
- 评判标准:ROUGE
- 复制技巧:attention
- 同时使用复制技巧和生成能构建一个混合 抽取/抽象 的方法
- 自底向上的摘要:将内容选择和表面实现分开
- 使用强化学习来专门以提高ROUGE分数为目标,得到的结果虽然有更高的ROUGE分数,但人类评分更低
-
对话
- 任务导向型对话
- 社会性对话
- 聊天型、治疗/精神健康
- 由于NLG自由性的难度,因此在神经网络之前使用预先设置的模板方法(templates)
- 基于seq2seq的对话:优化MMI能得到更好的结果
- CoQA:QA/ 阅读理解 / 对话任务
-
Storytelling
- 根据某种提示:图片、写作提示、给出故事的下一句
- 图片:Skip-thought
- 写作提示 Hierarchical Neural Story Generation
其思想是,第一个seq2seq模型学习一般LM,第二个模型学习在提示时进行条件处理 - Event2event Story Generation
-
诗歌生成
- Hafez:使用一个FSA来定义满足韵律限制的序列,然后使用FSA来限制RNN-LM的输出
- Deep-speare:LM,pentameter model,rhyme model
-
Non-autoregressive generation for NMT
NMT的非自回归生成- 不是从左到右生成翻译,每次依赖前一个单词
- 基于Transformer,可以并行
NLG 评测
- 自动评测
- BLEU, ROUGE, METEOR, F1, etc. 都不适合,与人类评判不相似
- 没有评价整体质量的自动评测方法,但可以评价多个方面
- 人工评价
- 被视为标准答案
- 但也有很多问题:不一致、可能不合理、误解问题
- NLG可能的新的评价方式
对NLG当前趋势,未来的思考
- 任务限制越少,越难。因此有时候限制是受欢迎的
- 自动评价对于任务的提升很重要,即使不是自动评价不是太完美
