信息的度量[编辑]
信息熵[编辑]
美国数学家克劳德·香农被称为“信息论之父”。人们通常将香农于1948年10月发表于《贝尔系统技术学报》上的论文《通信的数学理论》作为现代信息论研究的开端。这一文章部分基于哈里·奈奎斯特和拉尔夫·哈特利于1920年代先后发表的研究成果。在该文中,香农给出了信息熵的定义:
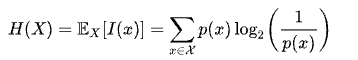
�(�)=��[�(�)]=∑�∈��(�)log2(1�(�))
![{\displaystyle H(X)=\mathbb {E} _{X}[I(x)]=\sum _{x\in {\mathcal {X}}}^{}p(x)\log _{2}\left({\frac {1}{p(x)}}\right)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a68cc322455e67276e7eea83b4b581d0479eebb)
其中�

信息熵与物理学中的热力学熵有着紧密的联系:
�(�)=���(�)

其中S(X)为热力学熵,H(X)为信息熵,��
信息熵是信源编码定理中,压缩率的下限。若编码所用的资讯量少于信息熵,则一定有资讯的损失。香农在大数定律和渐进均分性的基础上定义了典型集和典型序列。典型集是典型序列的集合。因为一个独立同分布的�
例子[编辑]
设有一个三个面的骰子,三面分别写有1,2,3
�(�=1)=1/5,�(�=2)=2/5,�(�=3)=2/5,

则
�(�)=15log2(5)+25log2(52)+25log2(52)≈1.522.

联合熵与条件熵[编辑]
联合熵(Joint Entropy)由熵的定义出发,计算联合分布的熵:
�(�,�)=∑�∈�∑�∈��(�,�)log(1�(�,�)).

条件熵(Conditional Entropy),顾名思义,是以条件机率�(�|�)
�(�|�)=∑�∈�∑�∈��(�,�)log(1�(�|�)).

由贝氏定理,有�(�,�)=�(�|�)�(�)
�(�,�)=�(�)+�(�|�)=�(�)+�(�|�)=�(�,�).

链式法则[编辑]
可以再对联合熵与条件熵的关系做推广,假设现在有�

�(�1,�2,...,��)=�(�1)+�(�2,...,��|�1)=�(�1)+�(�2|�1)+�(�3,...,��|�1,�2)=�(�1)+∑�=2��(��|�1,...,��−1).

其直观意义如下:假如接收一段数列{�1,�2,...,��}






互信息[编辑]
互信息(Mutual Information)是另一有用的信息度量,它是指两个事件集合之间的相关性。两个事件�
�(�;�)=�(�)−�(�|�)=�(�)+�(�)−�(�,�)=�(�)−�(�|�)=�(�;�).

其意义为,�


如果�,�


又因为�(�|�)≤�(�)
�(�;�)≤min(�(�),�(�)),

其中等号成立条件为�=�(�)

应用[编辑]
信息论被广泛应用在: