0 引言
1948年香农提出“信息熵”的概念,解决了对信息的量化度量问题。信息熵这个词是C.E.香农从热力学中借用过来的。热力学中的热熵是表示分子状态混乱程度的物理量。香农用信息熵的概念来描述信源的不确定度。
在信息增益中,衡量标准是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。对一个特征而言,系统有它和没它时信息量将发生变化,而前后信息量的差值就是这个特征给系统带来的信息量。信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好,在概率中定义为:待分类的集合的熵和选定某个特征的条件熵之差。
1信息熵与信息增益的计算
香农定义的信息熵的计算公式如下:

其中 表示的是随机变量,随机变量的取值为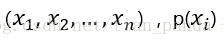
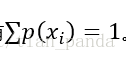
在香农1948年的论文《A Mathematical Theory ofCommunication》中,他通过论证信息熵函数需要满足的多条性质,推导出信息熵公式的唯一性。有兴趣的可以看看。
在《数学之美》中的例子:假如我错过了看世界杯,赛后我问一个知道决赛结果的观众“哪支球队是冠军?”他不愿意直接告诉我,而是让我猜,每猜一次需要1bit,他的回答是以下2个中的一个:是,否。假设我对这32支球队一无所知,即我认为每支球队获得冠军的概率是相等的,那么我至少需要付多少bit给他才能知道谁是冠军?
把球队编号为1到32,然后使用折半查找法的原理(如:冠军队在1-16吗?)每一次就可以减少一半的队伍,这样只需要5次,就能够知道冠军球队。也就是说,谁是世界杯冠军这条信息的信息量只值5bit。代入计算公式,在这种情况下(等概率假设)得到的信息熵即为5bit。
有五个硬币,四个等重,另外一个是假币所以质量相比其他4个要轻。事先不知道关于任何硬币的信息(即认为每一个硬币是假币的概率都是1/5)。这个例子和之前的猜球队冠军有一些相似,也是需要经过询问才能得到答案,且每问一次需要付1bit。但不同之处在于,现在我可以询问的对象变成了天平,天平每一次能够比较两堆硬币,且能够给出3个结果中的一个:左边比右边重,右边比左边重,两边同样重。问我至少需要付多少bit就能够确保知道哪个是假币?
通过自己的计算可知道,如果幸运的话我只需要1bit就能够把假币测出来(天平左右各两个硬币,结果等重,那么假币即为天平外的一个),但是通常情况下需要2bit才能知道假币。这个时候,会发现不能够按照之前的预测世界杯冠军的方式来计算信息熵了(按照之前的方法直接计算得到),毕竟之前问观众只能给出2种结果,现在问天平能够给出3种结果啊,需要的bit应该更少。
实际上不仅仅需要关心随机变量的信息熵,还应该关心被询问对象(例子中观众、天平)的表达能力(即被询问对象的信息熵)。正确的表达式应该是:
=1.46。世界杯冠军问题中之所以只计算随机变量的信息熵是因为被询问对象的信息熵刚好是1,所以忽略了。在计算机领域和通信领域,被询问对象一般都只能给出{0,1}两种结果,其信息熵为1,由此直接忽略。特殊情况下的忽略不代表不存在。
在经典熵的定义式中,对数的底是2,单位为bit。在我们之后的例子中,为了方便分析使用底数e。如果底数为e,那么单位是nat(奈特)。重新写一遍信息熵的公式:
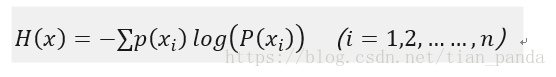
为此,研究函数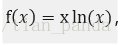
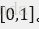
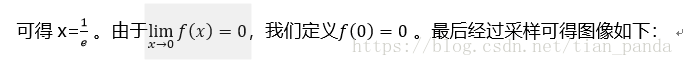
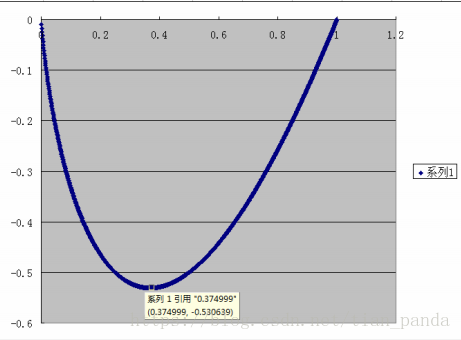
从之前的分析可以看出,熵其实定义了一个函数(概率分布函数)到一个值(信息熵H(X))的映射。而且从表达式中可以知道:随机变量不确定性越大,越小,熵值越大。由此,熵是随机变量不确定性的度量。一种极限情况是:当随机变量退化为定值时(概率为1),那么此时的熵值为0。另一个极限就是:当随机变量服从均匀分布的时候,此时的熵值最大。
信息增益表示得知特征X的信息而使得类Y的信息不确定性减少的程度,即用来衡量特征X区分数据集的能力。 当新增一个属性X时,信息熵H(Y)的变化大小即为信息增益。 I(Y|X)越大表示X越重要。
训练数据集合D,|D|为样本容量,即样本的个数(D中元素个数),设有K个类Ck来表示,|Ck|为Ci的样本个数,|Ck|之和为|D|,k=1,2.....,根据特征A将D划分为n个子集D1,D2.....Dn,|Di|为Di的样本个数,|Di|之和为|D|,i=1,2,....,记Di中属于Ck的样本集合为Dik,即交集,|Dik|为Dik的样本个数,算法如下:
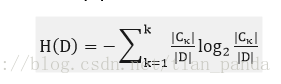
此处的概率计算是根据古典概率计算,由于训练数据集总个数为|D|,某个分类的个数为|Ck|,在某个分类的概率,或说随机变量取某值的概率为:|Ck|/|D|
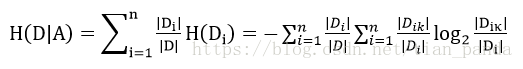
此处的概率计算同上,由于|Di|是选定特征的某个分类的样本个数,则|Di|/|D|,可以说为在选定特征某个分类的概率,后边的求和可以理解为在选定特征的某个类别下的条件概率的熵,即训练集为Di,交集Dik可以理解在Di条件下某个分类的样本个数,即k为某个分类,就是缩小训练集为Di的熵
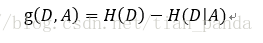
如何定量地衡量一个语言模型的好坏,当然,人们会很自然地想到,既然语言模型能减少语音识别和机器翻译的错误,那么就拿一个语音识别系统或者机器翻译软件来试试,好的语言模型必然导致错误率较低。这种想法是对的,而且今天的语音识别和机器翻译也是这么做的。但这种测试方法对于研发语言模型的人来讲,既不直接、又不方便,而且很难从错误率反过来定量度量语言模型。事实上,在贾里尼克(Fred Jelinek)的人研究语言模型时,世界上既没有像样的语音识别系统,更没有机器翻译。我们知道,语言模型是为了用上下文预测当前的文字,模型越好,预测得越准,那么当前文字的不确定性就越小。
信息熵正是对不确定性的衡量,因此信息熵可以直接用于衡量统计语言模型的好坏。贾里尼克从信息熵出发,定义了一个称为语言模型复杂度 (Perplexity)的概念,直接衡量语言模型的好坏。一个模型的复杂度越小,模型越好。李开复博士在介绍他发明的 Sphinx 语音识别系统时谈到,如果不用任何语言模型(即零元语言模型)时,复杂度为997,也就是说句子中每个位置有 997 个可能的单词可以填入。如果(二元)语言模型只考虑前后词的搭配不考虑搭配的概率时,复杂度为 60。虽然它比不用语言模型好很多,但是和考虑了搭配概率的二元语言模型相比要差很多,因为后者的复杂度只有 20。
信息论中仅次于熵的另外两个重要的概念是"互信息"(MutualInformation) 和"相对熵"(Kullback-Leibler Divergence)。
" 互信息"是信息熵的引申概念,它是对两个随机事件相关性的度量。比如说今天随机事件北京下雨和随机变量空气湿度的相关性就很大,但是和姚明所在的休斯敦火箭队是否能赢公牛队几乎无关。互信息就是用来量化度量这种相关性的。在自然语言处理中,经常要度量一些语言现象的相关性。比如在机器翻译中,最难的问题是词义的二义性(歧义性)问题。比如 Bush 一词可以是美国总统的名字,也可以是灌木丛。(有一个笑话,美国上届总统候选人凯里 Kerry 的名字被一些机器翻译系统翻译成了"爱尔兰的小母牛",Kerry 在英语中另外一个意思。)那么如何正确地翻译这个词呢?人们很容易想到要用语法、要分析语句等等。其实,至今为止,没有一种语法能很好解决这个问题,真正实用的方法是使用互信息。具体的解决办法大致如下:首先从大量文本中找出和总统布什一起出现的互信息最大的一些词,比如总统、美国、国会、华盛顿等等,当然,再用同样的方法找出和灌木丛一起出现的互信息最大的词,比如土壤、植物、野生等等。有了这两组词,在翻译 Bush 时,看看上下文中哪类相关的词多就可以了。这种方法最初是由吉尔(Gale),丘奇(Church)和雅让斯基(Yarowsky)提出的。
当时雅让斯基在宾西法尼亚大学是自然语言处理大师马库斯 (Mitch Marcus) 教授的博士生,他很多时间泡在贝尔实验室丘奇等人的研究室里。也许是急于毕业,他在吉尔等人的帮助下想出了一个最快也是最好地解决翻译中的二义性,就是上述的方法,这个看上去简单的方法效果好得让同行们大吃一惊。雅让斯基因而只花了三年就从马库斯那里拿到了博士,而他的师兄弟们平均要花六年时间。
信息论中另外一个重要的概念是"相对熵",在有些文献中它被称为成"交叉熵"。在英语中是Kullback-Leibler Divergence, 是以它的两个提出者库尔贝克和莱伯勒的名字命名的。相对熵用来衡量两个正函数是否相似,对于两个完全相同的函数,它们的相对熵等于零。在自然语言处理中可以用相对熵来衡量两个常用词(在语法上和语义上)是否同义,或者两篇文章的内容是否相近等等。利用相对熵,我们可以道出信息检索中最重要的一个概念:词频率-逆向文档频率(TF/IDF)。TF/IDF是一个非常重要的概念,在新闻的分类中也要用到相对熵和 TF/IDF。
信息熵的一个重要应用领域就是自然语言处理。在自然语言处理中,信息熵只反映内容的随机性(不确定性)和编码情况,与内容本身无关。例如,一本50万字的中文书平均有多少信息量。我们知道,常用的汉字约7000字。假如每个汉字等概率,那么大约需要约13比特(即13位二进制数,213213=8192)表示一个汉字。 应用信息熵就是,一个汉字有7000种可能性,每个可能性等概率,所以一个汉字的信息熵是:
H=-((1/7000)·log(1/7000)+(1/7000)·log(1/7000)+…(1/7000)·log(1/7000))=12.77(bit)
实际上由于前10%汉字占常用文本的95%以上,再考虑词语等上下文,每个汉字的信息熵大约是5比特左右。所以一本50万字的中文书,信息量大约是250万比特。需要注意这里的250万比特是个平均数。 再看下面两个句子。
(2)落日下的晚霞与孤独的大雁一同飞翔,晚秋的江水和深远的天空连成一片。
按照信息熵的计算,第二句比第一句的信息熵要高1倍以上,你会觉得第二句比第一句水平要高,信息量更大么?在自然语言处理中出现较大的信息熵,只表示可能出现的语言字符较多,并不意味着你可以从中得到更多的信息。
所以,信息熵高,不代表你说的话,写的文字中蕴含的信息量就比别人高了。更确切的,信息熵在自然语言处理中是用来对语言文字进行数据压缩的,与语言素养无关。当然条件熵、相对熵等应该是自然语言处理中更有用的概念。
由上面的公式可以知道:信息增益恰好是信息熵减去条件熵,换句话说,信息增益代表了在一个条件下,信息复杂度(不确定性)减少的程度。信息增益在决策树中应用的最为广泛,举一个非常经典的决策例子
有如下数据:
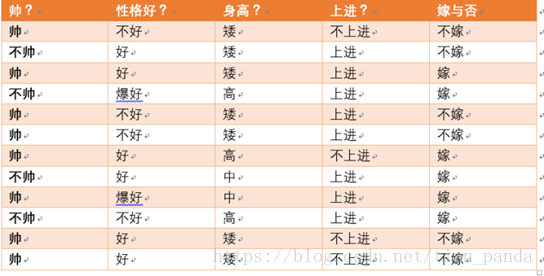
嫁的个数为6个,占1/2,那么信息熵为-1/2log1/2-1/2log1/2 =-log1/2=0.301
现在假如知道了一个男生的身高信息。身高有三个可能的取值{矮,中,高}
矮包括{1,2,3,5,6,11,12},嫁的个数为1个,不嫁的个数为6个
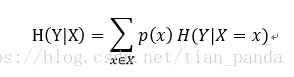
H(Y|X = 矮) = -1/7log1/7-6/7log6/7=0.178
p(X = 矮) = 7/12,p(X =中) = 2/12,p(X=高) = 3/12
7/12*0.178+2/12*0+3/12*0 = 0.103
所以我们可以得出我们在知道了身高这个信息之后,信息增益是0.198
我们可以知道,本来如果我对一个男生什么都不知道的话,作为他的女朋友决定是否嫁给他的不确定性有0.301这么大。当我们知道男朋友的身高信息后,不确定度减少了0.198.也就是说,身高这个特征对于我们广大女生同学来说,决定嫁不嫁给自己的男朋友是很重要的。
至少我们知道了身高特征后,我们原来没有底的心里(0.301)已经明朗一半多了,减少0.198了(大于原来的一半了)。
常见的关键词提取算法有TF-IDF,TextRank等算法。
如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率(另一说:TF词频(Term Frequency)指的是某一个给定的词语在该文件中出现的次数)。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大(见后续公式),则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。(另一说:IDF反文档频率(Inverse Document Frequency)是指果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。)但是实际上,有时候,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处.
TextRank 算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的PageRank算法, 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。和 LDA、HMM 等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
TextRank 一般模型可以表示为一个有向有权图 G =(V, E), 由点集合 V和边集合 E 组成, E 是V ×V的子集。图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的点 集 合 , Out(Vi) 为点 Vi 指向的点集合。点 Vi 的得分定义如下:
其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。
上述的关键词提取算法应用广泛,但是也有局限性。因此关于该算法的改进有很多,查阅资料发现李学明的《基于信息增益与信息熵的TFIDF算法》对TF-IDF算法做了改进。该文章指出:传统的特征词权重算法TFIDF忽略了特征词在类内、类间的分布对其权重的影响。针对该问题,引入信息熵的概念,对基于信息增益的TFIDF 算法(TFIDFIG)进行改进,提出一种基于信息增益与信息熵的TFIDF 算法(TFIDFIGE)。实验结果表明,与传统的TFIDF 算法和TFIDFIG 算法相比,TFIDFIGE 算法的查准率和查全率较高。
针对类间特征词分布的问题,在传统的TFIDF算法中加入信息增益的方法来改进特征词权重计算的精度。根据信息增益的定义,把信息增益公式引入到文本集合的类别间,即把文本集合看作一个符合某种规律分布的信息源,依靠训练数据集合的类别信息熵和文本类别中词语的条件熵之间信息量的增益关系来确定该词语在文本分类中所能提供的信息量,并把这个信息量反映到词语的权重中。
通过对熵的定义和性质的了解,可以知道一个特征词分布越均匀,熵的值越大;分布越不均匀,则熵值越小。考虑文本分类中某一类别类内的情况:若某一个特征词分布越均匀,则该词越能代表该类,该特征词应该赋予较高的权重。相反,如果某个特征词仅在几个文本中出现,则该词不能很好地代表该类别,该特征词应该赋予较低权重。通过分析可知,类内特征词分布熵值的大小与特征词所能提供的分类信息量是一致的,即熵值越大,特征词所提供的信息量越大,越能代表该类。因此,可以通过信息熵对特征词的权重公式进行调整。
从李光明老师的文章中知道,通过信息增益的方法来克服类间对其权重的影响,通过信息熵来克服类内对其权重的影响。将两者结合起来改进特征词的权重计算。由此我收到启发:能不能将信息增益与信息熵应用到textrank算法的改进。
回顾textrank算法,其中有一个固定值阻尼因子,由于textrank算法是根据pagerank推导得到,因此保留了阻尼因子。但是在文本处理时得到了词的权重,而每个词的权重不一样,所以就不需要对阻尼因子赋予同样的值,而可以根据权重灵活计算。再联系上述论文,可以通过信息熵计算这个权重。
在认真研究了信息熵与信息增益后,认为这个想法是可行了。这也是下一步要进行的工作。
1:Simon Haykin Neural Networks and Learning Machines[M] 北京:机械工业出版社,2016
2:李航 统计学习方法[M] 北京:清华大学出版社,2017
3:李学明基于信息增益与信息熵的TFIDF算法[J],计算机工程,2012,38(8)37-40
4:李海瑞基于信息增益和信息熵的特征词权重计算研究[D] 重庆:重庆大学,2012