最近在做的一个小项目,进行简单的分享。现在不论是手机APP、网页、电脑客户端等,只要涉及用户登录的界面基本都需要输入验证码核实身份真伪。因此有时,我们也会有自动识别验证码的需求,例如:希望实现业务流程自动化时,用户登录作为流程第一步可能就会用到验证码的识别,将该模型部署为接口进行调用就可以完成该功能。
本项目基于非常经典的文本识别算法CRNN来进行验证码识别模型的训练,整个流程是基于PaddlePaddle来训练的,后边也会放上Pytorch版本的模型代码。项目中代码直接使用时,需要自己加上 import python包 的部分。
1. 数据准备
1.1 数据集准备
这次分享的项目其实是一个简单的示例,使用一个比较简单的大写字母加数字的数据集进行训练,因此字符的丰富度可能比较有限,在真实场景下可以基于自己的需要找更加合适的数据集进行训练。这里把我找数据集的链接发给大家,就不放自己的数据集了,把大概准备数据的过程分享给大家。
1.2 准备标签文件
准备标签文件,这里因为我的数据集图片命名就是label的值,所以准备标签的方式比较简单。这里只是一种比较简单的数据准备方式,大家可以根据自己数据的情况进行标注和标签文件的准备。
#生成总的标签文件
train_path = "pic"
SUM = []
for root,dirs, files in os.walk(train_path): # 分别代表根目录、文件夹、文件
for file in files:
imgpath = os.path.join(root, file)
SUM.append(imgpath+"\t"+file.split(".")[0]+"\n")
# 生成总标签文件
allstr = ''.join(SUM)
f = open('total_list.txt','w',encoding='utf-8')
f.write(allstr)
f.close
print("数据集数量:{}".format(len(SUM)))
生成总的标签文件后就可以划分训练集和验证集,训练集和验证集的比例也可以自己去定。
random.shuffle(SUM)
train_len = int(len(SUM) * 0.8)
test_list = SUM[:train_len]
train_list = SUM[:train_len]
print('训练集数量: {}, 验证集数量: {}'.format(len(train_list),len(test_list)))
#生成训练集的标签文件
train_txt = ''.join(train_list)
f_train = open('train_list.txt','w',encoding='utf-8')
f_train.write(train_txt)
f_train.close()
#生成测试集的标签文件
test_txt = ''.join(test_list)
f_test = open('test_list.txt','w',encoding='utf-8')
f_test.write(test_txt)
f_test.close()
1.3 准备数据字典
在OCR-文本识别任务中,有一个特别需要准备的文件就是字典。文本识别的结果最终包含于字典文件中的字符集,也就是字典文件中有的字符才有可能作为最终识别的结果,没有的字符也就不会作为结果进行输出。在这个项目里,字典中的字符集也就应该是所有大写字母加上数字的集合。
#准备字典
class_set = set()
lines = []
file = open("total_list.txt","r",encoding="utf-8")#待转换文档,这里我们使用的是数据集的标签文件
for i in file:
a=i.strip('\n').split('\t')[-1]
lines.append(a)
file.close
for line in lines:
for e in line:
class_set.add(e)
class_list = list(class_set)
class_list.sort()
print("class num: {0}".format(len(class_list)))
with codecs.open("new_dict.txt", "w", encoding='utf-8') as label_list:
for id, c in enumerate(class_list):
label_list.write("{0}\n".format(c))
1.4 可视化观察一张样本
img = Image.open('9APK.png')
img = np.array(img)
# 画出读取的图片
plt.figure(figsize=(10, 10))
plt.imshow(img)
2. 数据预处理
在数据灌入模型前,需要对数据进行预处理操作,使得图片和标签满足网络训练和预测的需要。这里简单实现了如下方法:
- 图像解码:将图像转为Numpy格式;
- 编码标签:将标签按照CTC(Connectionist temporal classification)算法要求进行编码。其中,字符串中每个字符替换为其在字符字典中的索引值,规定标签的最大长度max_text_len,如果标签中字符个数小于max_text_len,则剩余位置补0,例如规定max_text_len=10,标签为[2322],字符字典为[0,1,2,3,4,5,6,7,8,9],则编码后的标签为[2,3,2,2,0,0,0,0,0,0];
- 缩放图像并归一化:将原图片的高度统一缩放到32,归一化后贴在尺寸为[3,32,100]的空白画布上;
- 返回图像、标签、长度:将保存在字典中的数据取出,以列表的形式返回,列表中元素顺序分别为 image, label, length。
图像解码
class DecodeImage(object):
# 图像解码
def __init__(self, img_mode='BGR', channel_first=False):
self.img_mode = img_mode
self.channel_first = channel_first
def __call__(self, data):
# 解码图像并返回结果
img = data['image']
img = np.frombuffer(img, dtype='uint8')
img = cv2.imdecode(img, 1)
if img is None:
return None
if self.img_mode == 'GRAY':
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
elif self.img_mode == 'RGB':
assert img.shape[2] == 3, 'invalid shape of image[%s]' % (img.shape)
img = img[:, :, ::-1]
if self.channel_first:
img = img.transpose((2, 0, 1))
data['image'] = img
return data
编码标签
将字符格式的标签转换为索引格式,如果不足 max_text_len 个,则在最后进行补零。
def encode(text, max_text_len, dict_index):
# 将字符标签转换为对应的索引值
# 如果没有字符或字符个数超过上限,返回None
if len(text) == 0 or len(text) > max_text_len:
return None
# 将字符的索引值依次保存到text_list
text_list = []
for char in text:
# 如果字符在字符字典没有出现,不进行保存
if char not in dict_index:
continue
text_list.append(dict_index[char])
if len(text_list) == 0:
return None
return text_list
class CTCLabelEncode(object):
# 编码标签
def __init__(self, max_text_length=25, character_dict_path='new_dict.txt'):
self.max_text_length = max_text_length
# 将标签编码为CTC格式
character_str = ""
# 读取字符字典
with open(character_dict_path, "rb") as fin:
lines = fin.readlines()
for line in lines:
line = line.decode('utf-8').strip("\n").strip("\r\n")
character_str += line
dict_character = list(character_str)
# 添加类别:分隔符
dict_character = ['blank'] + dict_character
# 将每个类别对应的索引保存到字典中
self.dict_index = {
}
for i, char in enumerate(dict_character):
self.dict_index[char] = i
def __call__(self, data):
# 获取数据的标签
text = data['label']
# 将标签转换为索引
text = encode(text, self.max_text_length, self.dict_index)
if text is None:
return None
data['length'] = np.array(len(text))
text = text + [0] * (self.max_text_length - len(text))
data['label'] = np.array(text)
return data
缩放图像并标准化
class RecResizeImg(object):
def __init__(self, image_shape=[3, 32, 100]):
self.image_shape = image_shape
def __call__(self, data):
img = data['image']
norm_img = self.resize_norm_img(img, self.image_shape)
data['image'] = norm_img
return data
def resize_norm_img(self, img, image_shape):
# 缩放图像并对图像进行归一化
# 缩放图像
imgC, imgH, imgW = image_shape
h = img.shape[0]
w = img.shape[1]
ratio = w / float(h)
# 如果 w 大于等于100,令 resized_w = 100
if math.ceil(imgH * ratio) > imgW:
resized_w = imgW
# 如果 w 小于100,令 resized_w 为 w 向上取整
else:
resized_w = int(math.ceil(imgH * ratio))
resized_image = cv2.resize(img, (resized_w, imgH))
# 对图片进行归一化
resized_image = resized_image.astype('float32')
resized_image = resized_image.transpose((2, 0, 1)) / 255
resized_image -= 0.5
resized_image /= 0.5
# 新建大小为[3, 32, 100]的空白图像,将缩放后的图像贴到对应位置,其他位置补0
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
返回图像、标签、长度
class KeepKeys(object):
# 将字典格式的数据转换为列表格式返回
def __init__(self, keep_keys=['image', 'label', 'length']):
self.keep_keys = keep_keys
def __call__(self, data):
data_list = []
for key in self.keep_keys:
data_list.append(data[key])
return data_list
汇总上述方法
# 图像预处理方法汇总
def transform(data, mode='train'):
# 图像解码
decode_image = DecodeImage()
# 编码标签
encode_label = CTCLabelEncode()
# 缩放图像并标准化
resize_image = RecResizeImg()
data = decode_image(data)
if mode == 'train' or mode == 'val':
data = encode_label(data)
keep_keys=['image', 'label', 'length']
else:
keep_keys = ['image']
# 返回图像、标签、长度
keepkeys = KeepKeys(keep_keys=keep_keys)
data = resize_image(data)
data = keepkeys(data)
return data
定义数据读取类SimpleDataSet,实现数据批量读取和预处理。具体代码如下:
class SimpleDataSet(Dataset):
def __init__(self, mode, label_file, data_dir, seed=None):
super(SimpleDataSet, self).__init__()
self.mode = mode.lower()
# 标注文件中,使用'\t'作为分隔符区分图片名称与标签
self.delimiter = '\t'
# 数据集路径
self.data_dir = data_dir
# 随机数种子
self.seed = seed
# 获取所有数据,以列表形式返回
self.data_lines = self.get_image_info_list(label_file)
# 新建列表存放数据索引
self.data_idx_order_list = list(range(len(self.data_lines)))
# 如果是训练过程,将数据集进行随机打乱
if self.mode == "train":
self.shuffle_data_random()
def get_image_info_list(self, label_file):
# 获取标签文件中的所有数据
with open(label_file, "rb") as f:
lines = f.readlines()
return lines
def shuffle_data_random(self):
#随机打乱数据
random.seed(self.seed)
random.shuffle(self.data_lines)
return
def __getitem__(self, idx):
# 获取索引为idx的数据
file_idx = self.data_idx_order_list[idx]
data_line = self.data_lines[file_idx]
try:
# 获取图片名称以及标签
data_line = data_line.decode('utf-8')
substr = data_line.strip("\n").split(self.delimiter)
file_name = substr[0]
label = substr[1]
# 获取图片路径
img_path = os.path.join(self.data_dir, file_name)
data = {
'img_path': img_path, 'label': label}
if not os.path.exists(img_path):
raise Exception("{} does not exist!".format(img_path))
# 读取图片并进行预处理
with open(data['img_path'], 'rb') as f:
img = f.read()
data['image'] = img
outs = transform(data, mode=self.mode.lower())
# 如果当前数据读取失败,重新读取一个新数据
except Exception as e:
outs = None
if outs is None:
rnd_idx = np.random.randint(self.__len__()) if self.mode == "train" else (idx + 1) % self.__len__()
return self.__getitem__(rnd_idx)
return outs
def __len__(self):
# 返回数据集的大小
return len(self.data_idx_order_list)
def build_dataloader(mode, label_file, data_dir, batch_size, drop_last, shuffle, num_workers, seed=None):
# 创建数据读取类
dataset = SimpleDataSet(mode, label_file, data_dir, seed)
# 定义 batch_sampler
batch_sampler = BatchSampler(dataset=dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last)
# 使用paddle.io.DataLoader创建数据读取器,并设置batchsize,进程数量num_workers等参数
data_loader = DataLoader(dataset=dataset, batch_sampler=batch_sampler, num_workers=num_workers, return_list=True, use_shared_memory=False)
return data_loader
# 定义训练集数据读取器
train_dataloader = build_dataloader('Train', 'train_list.txt', 'Verification_code', batch_size=256, drop_last=True, shuffle=True, num_workers=8)
# 定义验证集数据读取器
val_dataloader = build_dataloader('Val', 'test_list.txt', 'Verification_code', batch_size=256, drop_last=False, shuffle=False, num_workers=4)
3. 后处理
由于在预处理的过程中,对标签进行了CTC格式的编码,所以最终算法的输出是按照CTC算法的要求进行编码后的格式。因此,在获取预测结果后,还需要进行标签的解码,来得到最终的结果。
class CTCLabelDecode(object):
def __init__(self, character_dict_path=None):
self.character_str = ""
# 读取字符字典,并保存到列表中
with open(character_dict_path, "rb") as fin:
lines = fin.readlines()
for line in lines:
line = line.decode('utf-8').strip("\n").strip("\r\n")
self.character_str += line
dict_character = list(self.character_str)
# 添加类别:分隔符
dict_character = self.add_special_char(dict_character)
# 将每个类别对应的索引保存到字典中
self.dict_index = {
}
for i, char in enumerate(dict_character):
self.dict_index[char] = i
self.character = dict_character
def __call__(self, preds, label=None):
if isinstance(preds, paddle.Tensor):
preds = preds.numpy()
# 获取预测标签以及对应概率
preds_idx = preds.argmax(axis=2)
preds_prob = preds.max(axis=2)
# 解码预测标签
text = self.decode(preds_idx, preds_prob, is_remove_duplicate=True)
if label is None:
return text
# 解码真实标签
label = self.decode(label)
return text, label
def add_special_char(self, dict_character):
# 添加类别:分隔符
dict_character = ['blank'] + dict_character
return dict_character
def decode(self, text_index, text_prob=None, is_remove_duplicate=False):
result_list = []
batch_size = len(text_index)
for batch_idx in range(batch_size):
char_list = []
conf_list = []
for idx in range(len(text_index[batch_idx])):
# 如果当前字符的索引值为0,也就是'blank'字符,直接跳过
if text_index[batch_idx][idx] == 0:
continue
# 解码预测标签
if is_remove_duplicate:
# 如果当前字符与前一个字符为重复字符,直接跳过
if idx > 0 and text_index[batch_idx][idx - 1] == text_index[batch_idx][idx]:
continue
# 保存当前索引对应的字符
char_list.append(self.character[int(text_index[batch_idx][idx])])
# 如果是预测标签,保存置信度
if text_prob is not None:
conf_list.append(text_prob[batch_idx][idx])
# 如果是预测标签,置信度为1
else:
conf_list.append(1)
# 拼接字符串,置信度为所有字符置信度的平均值
text = ''.join(char_list)
result_list.append((text, np.mean(conf_list)))
return result_list
# 实例化后处理过程
post_process_class = CTCLabelDecode('new_dict.txt')
# 类别个数
char_num = len(getattr(post_process_class, 'character'))
4. 模型定义
传统的文本识别方法需要先对单个文字进行切割,然后再对单个文字进行识别,本实验使用的是图像文本识别的经典算法CRNN。CRNN是2015年被提出的,到目前为止还是被广泛应用。该算法的主要思想是认为文本识别其实需要对序列进行预测,所以采用了预测序列常用的RNN网络。算法通过CNN提取图片特征,然后采用RNN对序列进行预测,最终使用CTC方法得到最终结果。该算法具有以下几个优点:
- 可以进行端到端的训练;
- 可以进行不定长文本的识别;
- 模型简单,效果好
CRNN的主要结构包括基于CNN的图像特征提取模块以及基于多层双向LSTM的文字序列特征提取模块。:
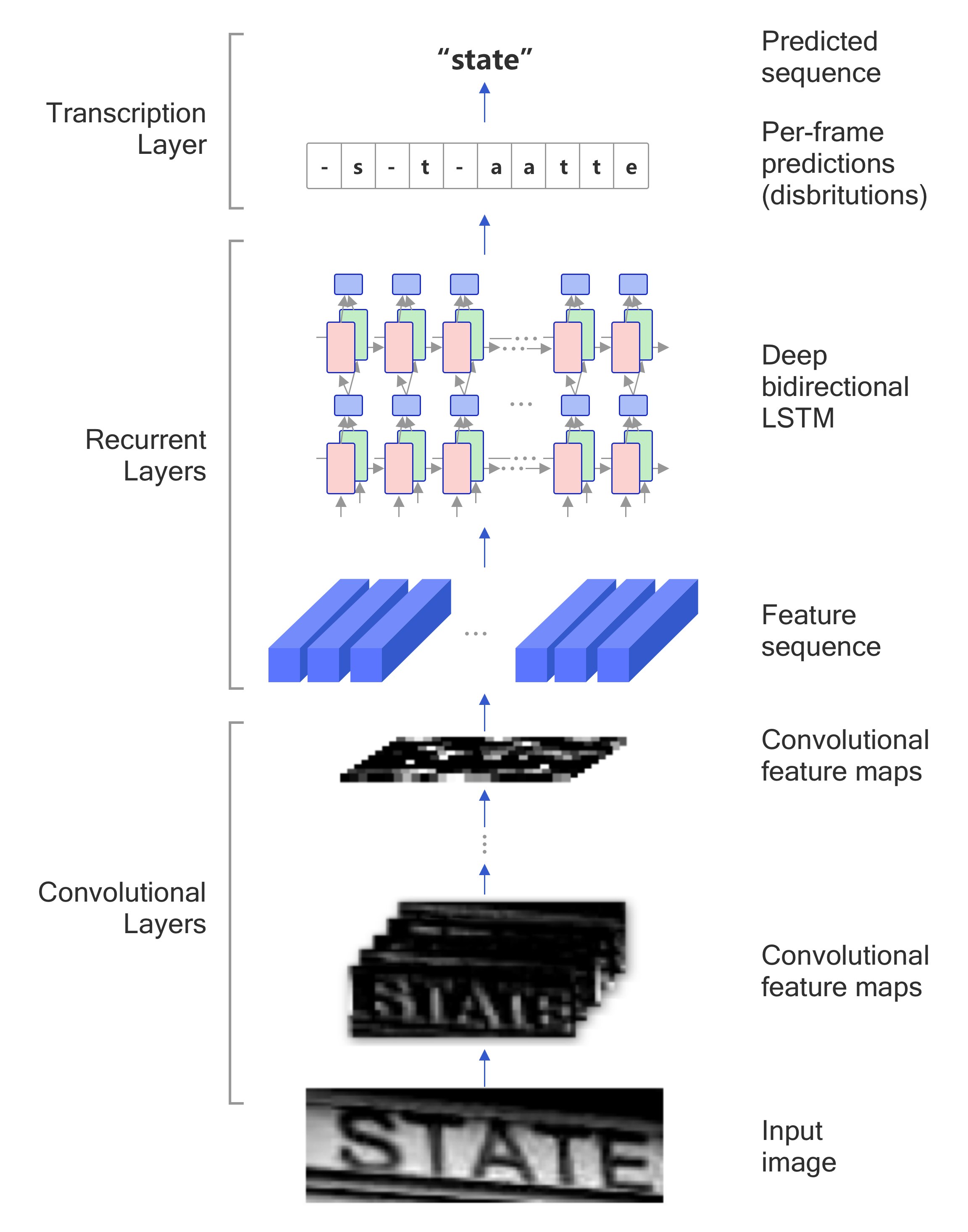
- 第一模块:使用CNN网络,对输入图像提取特征,得到特征图。这里参考paddleocr,使用调整后的MobileNetv3提取特征,其中输入图像的高度统一设置为32,宽度可以为任意长度,经过CNN网络后,特征图的高度缩放为1;
- 第二模块:Im2Seq,将CNN获取的特征图变换为RNN需要的特征向量序列的形状;
- 第三模块:使用双向LSTM(BiLSTM)对特征序列进行预测,学习序列中的每个特征向量并输出预测标签分布。这里其实相当于把特征向量的宽度视为LSTM中的时间维度;
- 第四模块:使用全连接层获取模型的预测结果;
- 第五模块:CTC转录层,解码模型输出的预测结果,得到最终输出。
说明:
这里的模块五转录层对应的就是上文中的标签解码过程。
class CRNN(nn.Layer):
def __init__(self):
super(CRNN, self).__init__()
# 定义骨干网络MobileNetV3
self.backbone = MobileNetV3()
in_channels = self.backbone.out_channels
# 定义序列预测部分,即:全连接+BiLSTM
self.neck = SequenceEncoder(in_channels, 96)
in_channels = self.neck.out_channels
# 定义 CTCHead, 输出类别数为字典中的元素个数
self.head = CTCHead(in_channels, char_num)
def forward(self, x):
x = self.backbone(x)
x = self.neck(x)
x = self.head(x)
return x
上边将模型分为了backbone、neck、head三个部分,接下来分别定义这3个部分。
4.1 定义backbone网络结构
这里考虑到文本序列存在高度较小而宽度较长的特性,对原始的MobileNetV3结构做了一定的改进,包括:
- 网络中第2、4、13个残差模块的步长改为(2,1);
- 第7个残差模块的步长改为1;
- 最后的自适应平均池化改为步长为2的最大池化。
这样,图片经过网络处理,高度下采样了 2 5 2^{5} 25倍,最终的特征图高度为1;宽度下采样了 2 2 2^{2} 22倍,最终的特征图宽度为25。
# 计算 MobileNetV3 中每层的输出维度
def make_divisible(v, divisor=8, min_value=None):
if min_value is None:
min_value = divisor
# 计算通道数
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# 保证通道数不会太小
if new_v < 0.9 * v:
new_v += divisor
return new_v
# 将卷积和批归一化封装为ConvBNLayer,方便后续复用
class ConvBNLayer(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1, if_act=False, act=None):
super(ConvBNLayer, self).__init__()
self.if_act = if_act
self.act = act
# 创建卷积层
self.conv = nn.Conv2D(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, weight_attr=ParamAttr(), bias_attr=False)
# 创建批归一化层
self.bn = nn.BatchNorm2D(num_features=out_channels)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
if self.if_act:
if self.act == "relu":
x = F.relu(x)
elif self.act == "hardswish":
x = F.hardswish(x)
else:
print("The activation function({}) is selected incorrectly.".format(self.act))
exit()
return x
# MobileNetV3 模型中,引入了SE通道注意力机制来提升网络效果,参考 https://arxiv.org/abs/1709.01507
# 通过学习的方式来自动获取到每个特征通道的重要程度,依照重要程度去提升有用的特征并抑制用处不大的特征
# 定义注意力模块
class SEModule(nn.Layer):
def __init__(self, in_channels, reduction=4):
super(SEModule, self).__init__()
# 创建自适应平均池化层
self.avg_pool = nn.AdaptiveAvgPool2D(1)
# 创建卷积层
self.conv1 = nn.Conv2D(in_channels=in_channels, out_channels=in_channels // reduction,
kernel_size=1, stride=1, padding=0, weight_attr=ParamAttr(), bias_attr=ParamAttr())
self.conv2 = nn.Conv2D(in_channels=in_channels // reduction, out_channels=in_channels,
kernel_size=1, stride=1, padding=0, weight_attr=ParamAttr(), bias_attr=ParamAttr())
def forward(self, inputs):
outputs = self.avg_pool(inputs)
outputs = self.conv1(outputs)
outputs = F.relu(outputs)
outputs = self.conv2(outputs)
outputs = F.hardsigmoid(outputs)
return inputs * outputs
# 定义残差结构
class ResidualUnit(nn.Layer):
def __init__(self, in_channels, mid_channels, out_channels, kernel_size, stride, use_se, act=None):
super(ResidualUnit, self).__init__()
self.if_shortcut = stride == 1 and in_channels == out_channels
self.if_se = use_se
# 创建ConvBNLayer
self.expand_conv = ConvBNLayer(in_channels=in_channels, out_channels=mid_channels,
kernel_size=1, stride=1, padding=0, if_act=True, act=act)
self.bottleneck_conv = ConvBNLayer(in_channels=mid_channels, out_channels=mid_channels, kernel_size=kernel_size,
stride=stride, padding=int((kernel_size - 1) // 2), groups=mid_channels, if_act=True, act=act)
# 如果指定了使用注意力机制,创建SEModule
if self.if_se:
self.mid_se = SEModule(mid_channels)
# 创建ConvBNLayer
self.linear_conv = ConvBNLayer(in_channels=mid_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)
def forward(self, inputs):
x = self.expand_conv(inputs)
x = self.bottleneck_conv(x)
if self.if_se:
x = self.mid_se(x)
x = self.linear_conv(x)
if self.if_shortcut:
x = paddle.add(inputs, x)
return x
class MobileNetV3(nn.Layer):
def __init__(self, in_channels=3, scale=0.5, large_stride=None):
super(MobileNetV3, self).__init__()
# 设置步长列表
if large_stride is None:
large_stride = [1, 2, 2, 2]
# 存放每个模块的具体参数,包括:卷积核大小、残差模块的中间通道数基数、输出通道数基数、是否使用注意力机制、激活函数、步长
cfg = [
[3, 16, 16, False, 'relu', large_stride[0]],
[3, 64, 24, False, 'relu', (large_stride[1], 1)],
[3, 72, 24, False, 'relu', 1],
[5, 72, 40, True, 'relu', (large_stride[2], 1)],
[5, 120, 40, True, 'relu', 1],
[5, 120, 40, True, 'relu', 1],
[3, 240, 80, False, 'hardswish', 1],
[3, 200, 80, False, 'hardswish', 1],
[3, 184, 80, False, 'hardswish', 1],
[3, 184, 80, False, 'hardswish', 1],
[3, 480, 112, True, 'hardswish', 1],
[3, 672, 112, True, 'hardswish', 1],
[5, 672, 160, True, 'hardswish', (large_stride[3], 1)],
[5, 960, 160, True, 'hardswish', 1],
[5, 960, 160, True, 'hardswish', 1],
]
cls_ch_squeeze = 960
inplanes = 16
# 创建ConvBNLayer
self.conv1 = ConvBNLayer(in_channels=in_channels, out_channels=make_divisible(inplanes * scale),
kernel_size=3, stride=2, padding=1, if_act=True, act='hardswish')
i = 0
block_list = []
inplanes = make_divisible(inplanes * scale)
# 创建残差模块
for (k, exp, c, se, nl, s) in cfg:
block_list.append(ResidualUnit(in_channels=inplanes, mid_channels=make_divisible(scale * exp),
out_channels=make_divisible(scale * c), kernel_size=k, stride=s, use_se=se, act=nl))
inplanes = make_divisible(scale * c)
i += 1
self.blocks = nn.Sequential(*block_list)
# 创建ConvBNLayer
self.conv2 = ConvBNLayer(in_channels=inplanes, out_channels=make_divisible(scale * cls_ch_squeeze),
kernel_size=1, stride=1, padding=0, if_act=True, act='hardswish')
# 创建最大池化层
self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
self.out_channels = make_divisible(scale * cls_ch_squeeze)
def forward(self, x):
x = self.conv1(x)
x = self.blocks(x)
x = self.conv2(x)
x = self.pool(x)
return x
4.2 定义neck网络结构
然后是 neck 部分,在 CRNN 中,neck 部分包括两个模块,分别是:
- Im2Seq,将CNN获取的特征图变换为RNN需要的特征向量序列的形状;
- 多层双向LSTM(BiLSTM),这里实际使用了2层的BiLSTM。
class Im2Seq(nn.Layer):
def __init__(self, in_channels):
super().__init__()
self.out_channels = in_channels
def forward(self, x):
B, C, H, W = x.shape
assert H == 1
# 删除第2个维度
x = x.squeeze(axis=2)
# 将形状调整为(batch, width, channels)
x = x.transpose([0, 2, 1])
return x
class EncoderWithRNN(nn.Layer):
def __init__(self, in_channels, hidden_size):
super(EncoderWithRNN, self).__init__()
self.out_channels = hidden_size * 2
# 定义2层BiLSTM
self.lstm = nn.LSTM(in_channels, hidden_size, direction='bidirectional', num_layers=2)
def forward(self, x):
x, _ = self.lstm(x)
return x
# 将Im2Seq以及BiLSTM模块串联
class SequenceEncoder(nn.Layer):
def __init__(self, in_channels, hidden_size):
super(SequenceEncoder, self).__init__()
self.encoder_reshape = Im2Seq(in_channels)
self.encoder = EncoderWithRNN(self.encoder_reshape.out_channels, hidden_size)
self.out_channels = self.encoder.out_channels
def forward(self, x):
x = self.encoder_reshape(x)
x = self.encoder(x)
return x
4.3 定义head网络结构
最后是 head 部分,这里的 head 部分使用了全连接层获取模型的预测结果。
class CTCHead(nn.Layer):
def __init__(self, in_channels, out_channels):
super(CTCHead, self).__init__()
stdv = 1.0 / math.sqrt(in_channels * 1.0)
# 定义全连接层
self.fc = nn.Linear(in_channels, out_channels,
weight_attr=ParamAttr(initializer=nn.initializer.Uniform(-stdv, stdv)),
bias_attr=ParamAttr(initializer=nn.initializer.Uniform(-stdv, stdv)))
self.out_channels = out_channels
def forward(self, x):
predicts = self.fc(x)
# 如果是模型推理过程,使用softmax计算输出概率
if not self.training:
predicts = F.softmax(predicts, axis=2)
return predicts
5. 定义损失函数
为了解决预测标签与真实标签无法对齐的问题,这里使用了CTC loss进行模型的训练。
class CTCLoss(nn.Layer):
def __init__(self):
super(CTCLoss, self).__init__()
self.loss_func = nn.CTCLoss(blank=0, reduction='none')
def __call__(self, predicts, batch):
predicts = predicts.transpose((1, 0, 2))
N, B, _ = predicts.shape
preds_lengths = paddle.to_tensor([N] * B, dtype='int64')
labels = batch[1].astype("int32")
label_lengths = batch[2].astype('int64')
loss = self.loss_func(predicts, labels, preds_lengths, label_lengths)
loss = loss.mean() # sum
return {
'loss': loss}
# 实例化损失函数
loss_class = CTCLoss()
6. 模型训练
这里基于PaddlePaddle开源的模型作为预训练模型来提高精度。
实例化模型
# 声明定义好的CRNN模型
model = CRNN()
定义优化器
使用Adam优化器,学习率设置为0.0005,beta1设置为0.9, beta2设置为0.999, epsilon设置为1e-08。
# 使用Adam优化器,学习率设置为0.0005,beta1设置为0.9, beta2设置为0.999, epsilon设置为1e-08。
lr_scheduler = 0.0005
optimizer = optim.Adam(learning_rate=lr_scheduler, beta1=0.9, beta2=0.999, epsilon=1e-08, parameters=model.parameters())
加载模型参数并微调
# 使用已有的预训练模型来初始化网络
def init_model(model, checkpoints):
# 加载预训练的模型参数
assert os.path.exists(checkpoints + ".pdparams"), "Given dir {}.pdparams not exist.".format(checkpoints)
# 加载模型参数以及优化器参数
para_dict = paddle.load(checkpoints + '.pdparams')
model.set_state_dict(para_dict)
# 指定预训练权重文件
checkpoints = './pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train/best_accuracy'
# 加载预训练的模型参数
init_model(model, checkpoints)
定义评估方式
这里采用了两种指标对模型效果进行评估:
- acc:准确率。只有两个字符串完全相同时,判断为正确。
- norm_edit_dis: 1 − d i s t a n c e L e v e n s h t e i n ‾ 1 - \overline{distance_{Levenshtein}} 1−distanceLevenshtein
说明:
Levenshtein距离,即两个字符串之间,由一个转成另一个所需的最少的编辑操作次数。编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符,编辑距离越小,两个字符串的相似度越大。
# 定义评估类
class RecMetric(object):
def __init__(self, main_indicator='acc'):
# 设置主要评估指标为 'acc'
self.main_indicator = main_indicator
self.reset()
def __call__(self, pred_label):
preds, labels = pred_label
# 获取预测值和真实标签
correct_num = 0
all_num = 0
norm_edit_dis = 0.0
# 计算准确率和norm_edit_dis
for (pred, pred_conf), (target, _) in zip(preds, labels):
pred = pred.replace(" ", "")
target = target.replace(" ", "")
norm_edit_dis += Levenshtein.distance(pred, target) / max(len(pred), len(target), 1)
if pred == target:
correct_num += 1
all_num += 1
self.correct_num += correct_num
self.all_num += all_num
self.norm_edit_dis += norm_edit_dis
return {
'acc': correct_num / all_num,
'norm_edit_dis': 1 - norm_edit_dis / all_num
}
def get_metric(self):
# 计算累加的准确率和norm_edit_dis并返回
acc = 1.0 * self.correct_num / self.all_num
norm_edit_dis = 1 - self.norm_edit_dis / self.all_num
self.reset()
return {
'acc': acc, 'norm_edit_dis': norm_edit_dis}
def reset(self):
# 参数重置
self.correct_num = 0
self.all_num = 0
self.norm_edit_dis = 0
# 实例化评估类
eval_class = RecMetric()
配置全局变量
# 训练过程中评估指标
cal_metric_during_train = True
# log队列的长度
log_smooth_window = 20
epoch_num = 40
# 打印log的间隔
print_batch_step = 10
# 当前迭代次数
global_step = 0
# 模型保存路径
save_model_dir = './output/rec/ic15/'
if not os.path.exists(save_model_dir):
os.makedirs(save_model_dir)
# 最优模型保存路径
best_prefix = os.path.join(save_model_dir, 'best_accuracy')
# 最终模型保存路径
latest_prefix = os.path.join(save_model_dir, 'latest')
模型训练
# 设置随机种子
paddle.seed(2)
# 设置运行设备
# 开启0号GPU
use_gpu = True
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
# 定义一个存放最优模型指标的字典
best_model_dict = {
'acc': 0, 'norm_edit_dis':0, 'best_epoch':0}
# 将模型调整为训练状态
model.train()
# 模型训练
for epoch in range(epoch_num):
for idx, batch in enumerate(train_dataloader):
if idx >= len(train_dataloader):
break
lr = optimizer.get_lr()
# 获取当前batch的图片
images = batch[0]
# 前向计算
preds = model(images)
# 计算损失
loss = loss_class(preds, batch)
avg_loss = loss['loss']
# 反向传播
avg_loss.backward()
optimizer.step()
optimizer.clear_grad()
step_loss = avg_loss.numpy().mean()
# 训练过程中打印评估指标
if cal_metric_during_train:
batch = [item.numpy() for item in batch]
post_result = post_process_class(preds, batch[1])
eval_class(post_result)
metric = eval_class.get_metric()
acc = metric['acc']
norm_edit_dis = metric['norm_edit_dis']
if global_step > 0 and global_step % print_batch_step == 0:
logs = 'loss: {:x<6f}, acc: {:x<6f}, norm_edit_dis: {:x<6f}'.format(step_loss, acc, norm_edit_dis)
print('epoch: [{}/{}], iter: {}, {}'.format(epoch, epoch_num, global_step, logs))
global_step += 1
# 每隔5个epoch训练完成后,进行模型评估
if (epoch+1) % 5 == 0:
# 将模型设置为评估状态
model.eval()
# 评估过程中不计算梯度值
with paddle.no_grad():
for idx, batch in enumerate(val_dataloader):
if idx >= len(val_dataloader):
break
images = batch[0]
# 前向计算
preds = model(images)
batch = [item.numpy() for item in batch]
# 模型后处理
post_result = post_process_class(preds, batch[1])
# 评估模型指标
eval_class(post_result)
# 获取最终指标
cur_metric = eval_class.get_metric()
print('[validation] cur metric, {}'.format(', '.join(['{}: {}'.format(k, v) for k, v in cur_metric.items()])))
# 如果当前模型准确率高于最优模型,保存当前模型
if cur_metric['acc'] >= best_model_dict['acc']:
best_model_dict.update(cur_metric)
best_model_dict['best_epoch'] = epoch
# 保存模型
paddle.save(model.state_dict(), best_prefix + '.pdparams')
print('[validation] best metric, {}'.format(', '.join(['{}: {}'.format(k, v) for k, v in best_model_dict.items()])))
# 将模型恢复为训练状态
model.train()
# 打印训练过程中的最高准确率
print('best metric, {}'.format(', '.join(['{}: {}'.format(k, v) for k, v in best_model_dict.items()])))
模型验证和预测过程可以自己实现。
7. 基于 Pytorch 实现 RCNN
这里也把上边的模型使用 pytorch 实现一遍。
class CRNN(nn.Module):
def __init__(self):
super(CRNN, self).__init__()
self.backbone = MobileNetV3()
in_channels = self.backbone.out_channels
self.neck = SequenceEncoder(in_channels, 96)
in_channels = self.neck.out_channels
self.head = CTCHead(in_channels, 36)
def forward(self, x):
x = self.backbone(x)
x = self.neck(x)
x = self.head(x)
return x
def make_divisible(v, divisor=8, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
class ConvBNLayer(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1, if_act=False, act=None):
super(ConvBNLayer, self).__init__()
self.if_act = if_act
self.act = act
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(num_features=out_channels)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
if self.if_act:
if self.act == "relu":
x = F.relu(x)
elif self.act == "hardswish":
x = F.hardswish(x)
else:
print("The activation function({}) is selected incorrectly.".format(self.act))
exit()
return x
class SEModule(nn.Module):
def __init__(self, in_channels, reduction=4):
super(SEModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=in_channels // reduction,
kernel_size=1, stride=1, padding=0)
self.conv2 = nn.Conv2d(in_channels=in_channels // reduction, out_channels=in_channels,
kernel_size=1, stride=1, padding=0)
def forward(self, inputs):
outputs = self.avg_pool(inputs)
outputs = self.conv1(outputs)
outputs = F.relu(outputs)
outputs = self.conv2(outputs)
outputs = F.hardsigmoid(outputs)
return inputs * outputs
class ResidualUnit(nn.Module):
def __init__(self, in_channels, mid_channels, out_channels, kernel_size, stride, use_se, act=None):
super(ResidualUnit, self).__init__()
self.if_shortcut = stride == 1 and in_channels == out_channels
self.if_se = use_se
self.expand_conv = ConvBNLayer(in_channels=in_channels, out_channels=mid_channels,
kernel_size=1, stride=1, padding=0, if_act=True, act=act)
self.bottleneck_conv = ConvBNLayer(in_channels=mid_channels, out_channels=mid_channels, kernel_size=kernel_size,
stride=stride, padding=int((kernel_size - 1) // 2), groups=mid_channels, if_act=True, act=act)
if self.if_se:
self.mid_se = SEModule(mid_channels)
self.linear_conv = ConvBNLayer(in_channels=mid_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)
def forward(self, inputs):
x = self.expand_conv(inputs)
x = self.bottleneck_conv(x)
if self.if_se:
x = self.mid_se(x)
x = self.linear_conv(x)
if self.if_shortcut:
x = torch.add(inputs, x)
return x
class MobileNetV3(nn.Module):
def __init__(self, in_channels=3, scale=0.5, large_stride=None):
super(MobileNetV3, self).__init__()
if large_stride is None:
large_stride = [1, 2, 2, 2]
cfg = [
[3, 16, 16, False, 'relu', large_stride[0]],
[3, 64, 24, False, 'relu', (large_stride[1], 1)],
[3, 72, 24, False, 'relu', 1],
[5, 72, 40, True, 'relu', (large_stride[2], 1)],
[5, 120, 40, True, 'relu', 1],
[5, 120, 40, True, 'relu', 1],
[3, 240, 80, False, 'hardswish', 1],
[3, 200, 80, False, 'hardswish', 1],
[3, 184, 80, False, 'hardswish', 1],
[3, 184, 80, False, 'hardswish', 1],
[3, 480, 112, True, 'hardswish', 1],
[3, 672, 112, True, 'hardswish', 1],
[5, 672, 160, True, 'hardswish', (large_stride[3], 1)],
[5, 960, 160, True, 'hardswish', 1],
[5, 960, 160, True, 'hardswish', 1],
]
cls_ch_squeeze = 960
inplanes = 16
self.conv1 = ConvBNLayer(in_channels=in_channels, out_channels=make_divisible(inplanes * scale),
kernel_size=3, stride=2, padding=1, if_act=True, act='hardswish')
i = 0
block_list = []
inplanes = make_divisible(inplanes * scale)
for (k, exp, c, se, nl, s) in cfg:
block_list.append(ResidualUnit(in_channels=inplanes, mid_channels=make_divisible(scale * exp),
out_channels=make_divisible(scale * c), kernel_size=k, stride=s, use_se=se, act=nl))
inplanes = make_divisible(scale * c)
i += 1
self.blocks = nn.Sequential(*block_list)
self.conv2 = ConvBNLayer(in_channels=inplanes, out_channels=make_divisible(scale * cls_ch_squeeze),
kernel_size=1, stride=1, padding=0, if_act=True, act='hardswish')
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.out_channels = make_divisible(scale * cls_ch_squeeze)
def forward(self, x):
x = self.conv1(x)
x = self.blocks(x)
x = self.conv2(x)
x = self.pool(x)
return x
class Im2Seq(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.out_channels = in_channels
def forward(self, x):
B, C, H, W = x.shape
assert H == 1
x = x.squeeze(axis=2)
x = x.transpose(1, 2)
return x
class EncoderWithRNN(nn.Module):
def __init__(self, in_channels, hidden_size):
super(EncoderWithRNN, self).__init__()
self.out_channels = hidden_size * 2
self.device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
self.lstm = nn.LSTM(in_channels, hidden_size, bidirectional=True, num_layers=2, batch_first=True)
def forward(self, x):
x = x.to(self.device)
x, _ = self.lstm(x)
return x
class SequenceEncoder(nn.Module):
def __init__(self, in_channels, hidden_size):
super(SequenceEncoder, self).__init__()
self.encoder_reshape = Im2Seq(in_channels)
self.encoder = EncoderWithRNN(self.encoder_reshape.out_channels, hidden_size)
self.out_channels = self.encoder.out_channels
def forward(self, x):
x = self.encoder_reshape(x)
x = self.encoder(x)
return x
class CTCHead(nn.Module):
def __init__(self, in_channels, out_channels):
super(CTCHead, self).__init__()
stdv = 1.0 / math.sqrt(in_channels * 1.0)
self.fc = nn.Linear(in_channels, out_channels)
self.out_channels = out_channels
def forward(self, x):
predicts = self.fc(x)
if not self.training:
predicts = F.softmax(predicts, dim=2)
return predicts