数据准备
我们首先需要加载波士顿房价数据集。该数据集包含房屋特征信息和对应的房价标签。
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
print("数据集大小:{}".format(data.shape))
print("标签大小:{}".format(target.shape))
数据划分
接下来,我们将数据集划分为训练集和测试集,以便对模型进行训练和评估。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data, target)
print("训练集大小:{}".format(X_train.shape))
print("测试集大小:{}".format(X_test.shape))
数据标准化
为了提高梯度下降的收敛速度和性能,我们需要对数据进行标准化处理。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
梯度下降方法
我们使用 SGDRegressor 类来训练梯度下降模型,并输出训练集和测试集上的得分、参数和截距。
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor()
sgd_reg.fit(X_train, y_train)
print("梯度下降训练集得分:{:.2f}".format(sgd_reg.score(X_train, y_train)))
print("梯度下降测试集得分:{:.2f}".format(sgd_reg.score(X_test, y_test)))
print("梯度下降参数:{}".format(sgd_reg.coef_))
print("梯度下降截距:{}".format(sgd_reg.intercept_))
模型评估
我们使用得分来评估梯度下降模型在训练集和测试集上的拟合效果。得分越接近1,表示模型拟合效果越好。
# 模型评估
from sklearn.metrics import mean_squared_error
y_pred = sgd_reg.predict(X_test)
print("梯度下降均方误差:{:.2f}".format(mean_squared_error(y_test, y_pred)))
print("梯度下降均方根误差:{:.2f}".format(np.sqrt(mean_squared_error(y_test, y_pred))))
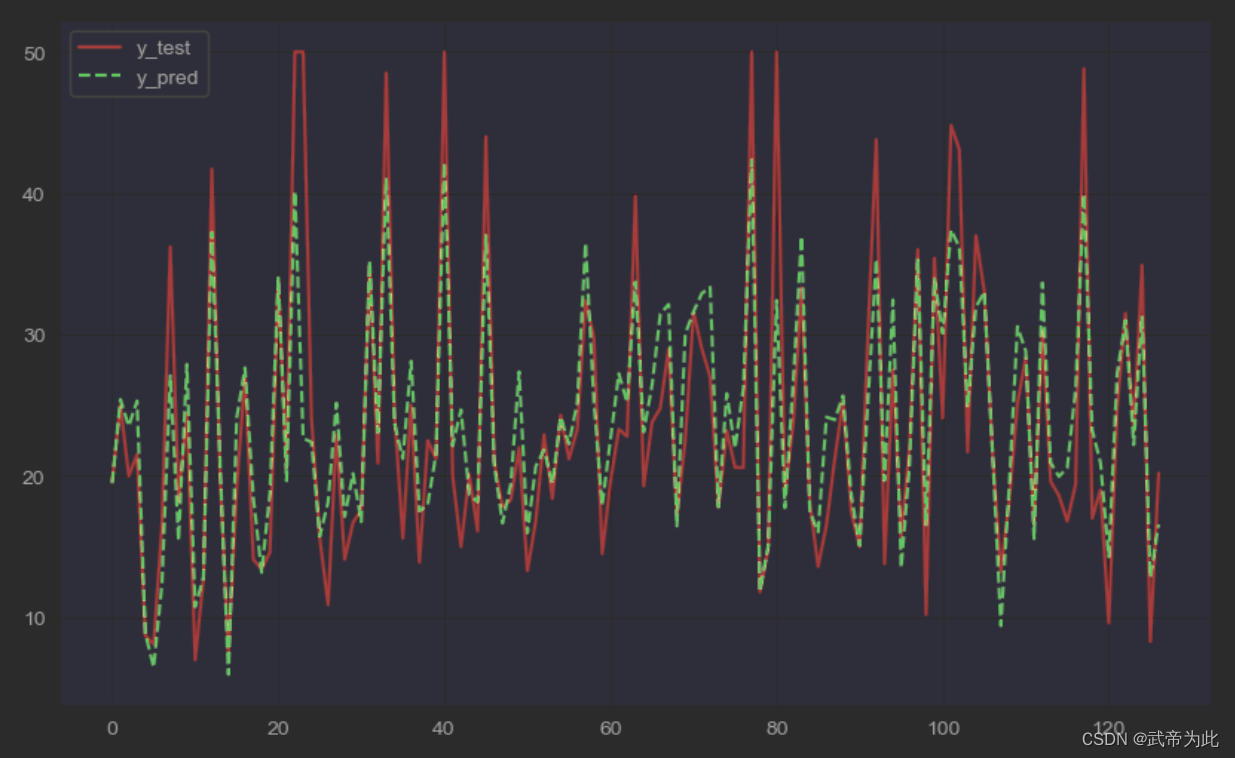
可视化
为了更直观地了解模型预测效果,我们绘制了测试集中真实房价和梯度下降预测房价的可视化图。
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(range(len(y_test)), y_test, "r", label="y_test")
plt.plot(range(len(y_test)), sgd_reg.predict(X_test), "g--", label="y_pred")
plt.legend()
plt.show()