On the Generation of Medical Dialogs for COVID-19

文章目录
会议:ACL2021
任务:医疗对话生成
原文:链接
源码:链接
Abstract
发布了两个对话数据集,CovidDialog(中文和英文版),它们包含医生和患者之间关于COVID-19的对话,开发了一个能提供新冠相关问诊的医疗对话系统。比之通用领域对话系统,其规模相对较小,为缓解过拟合风险,本文还开发了一个多任务学习方法,将数据稀缺的对话生成任务和掩码词预测(masked token prediction,MTP)任务进行正则化。
Datasets
统计信息
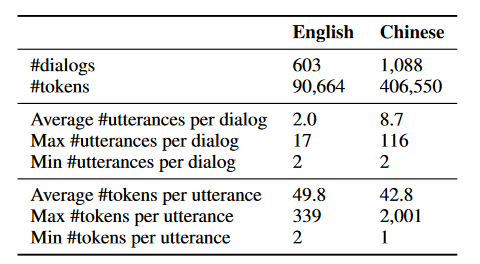
详细说明
包含医生和病人之间关于新冠肺炎和其他肺炎之间的对话,分为中文和英文。
-
英文数据集:603次对话,1232条话语,90664个词。来自582个病人和117个医生。每次咨询都以对病人的医疗状况的简短描述开始。
-
中文数据集:1088次对话,9494条话语,406550个词(不分词,每个汉字直接作为一个token)。来自935个病人和352个医生。
每个咨询包含三部分内容:
- 关于病人病况和历史的描述,包括:目前的疾病,目前疾病的详细描述,需要医生提供什么帮助,疾病持续了多久,药物,过敏和过去的疾病,这将作为病人在对话中的第一句话;
- 病人和医生之间的对话;
- 医生给出的诊断和治疗建议。
Method
为了缓解过拟合问题,我们开发了一种多任务学习(muti-task learning) 方法,该方法通过一个掩码词预测(masked-token prediction) 任务来规范数据不足的对话生成任务。即,在编码器之上同时定义两个任务。
- MTP(Masked Token Prediction)任务。随机mask一定比例的token,该任务在编码器最后一层隐藏向量后做完形填空任务;
- 对话生成任务。
同时执行MTP(Masked Token Prediction)任务和对话生成任务。MTP损失作为一个正则化项,与对话生成损失一起进行优化。
Experiments
本文的Baseline包括:
- Transformer
- GPT-2
- unregularized BART
- unregularized BERT-GPT:用预训练的BERT初始化Encoder,用GPT初始化Decoder
- TAPT(task adaptive pretraining on BART or BERT-GPT)
本文的方法:regularized BART。
实验结果及分析:本文的Transformer是未经过预训练的模型,由于数据集规模较小,Perplexity都很高。另外,GPT2加上MMI方法在自动评估指标上明显表现更好。但是,自动评估指标并不能很好地评价对话系统,特别是机器翻译指标,作者不断强调了Perplexity是相对靠谱的指标。TAPT方法是先预训练Encoder,再进行对话回复生成训练。本文的多任务学习方法则是联合训练二者,过拟合风险更小。