1. 摘要
- 孪生网络已经成为无监督视觉表征学习的主流框架,最大化同一图像的两个增广图的相似性使其避免 崩溃解(collapsing solutions) 问题。本文提出了一个simple Siamese网络可以在不使用1) 负样本对;2)大批量; 3) 动量编码器取得好的结果。崩溃解存在于损失函数和网络中,但是可以通过stop-gradient操作避免崩溃解。SimSiam在ImageNet及下游任务上均取得了有竞争力的结果。
2. 引言
-
Siamese 网络是应用于两个或多个输入的 权重共享 神经网络,可以用来 比较(包括但不限于“对比”)实体。最近的方法将输入定义为一幅图像的两个增强,并根据不同的条件最大化相似性。本文提出的Siamese 既没有使用负样本对也没有使用动量编码器防止崩溃解,而是通过最大化同一张图片的两个视角相似度,既适用于典型的批量大小,也不依赖于大批量训练。
-
Contrastive learning:排斥来自不同图像的输入,同时吸引相同图像的两个增强图片。负对排除了来自解空间的恒定输出。
-
Clustering:在聚类表示和学习预测聚类分配之间交替。SwAV 通过从一个视图计算分配并从另一个视图进行预测来将聚类融合到一个孪生网络。SwAV在每个batch的平衡分区约束下执行在线聚类。为了提供充足的样本进行聚类,往往会使用大批量训练。
-
BYOL :从一个视图直接预测另一个视图的输出,它是一个分支为 动量编码器的孪生网络。
3. 方法
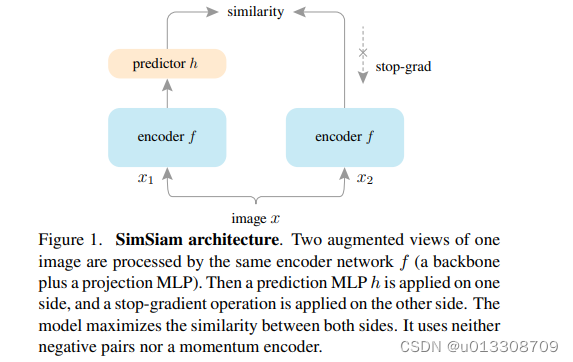

- 上述公式等价于规范化向量的MSE损失。与此同时,还定义了一个对称损失.
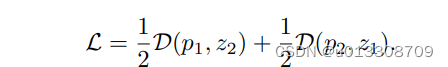
-
上述两个损失作用于每一张图像,总损失是所有图像损失的平均,故最小的可能损失为-1.
-
使用stop-gradient操作修改loss函数为:
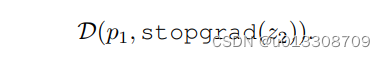
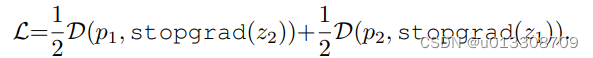
-
在损失的第一项, x 2 \begin{array}{c}_{x_2 } \end{array} x2不会从 z 2 \begin{array}{c}_{z_2 } \end{array}