目录
4.随机梯度下降(Stochastic Gradient Descent)
1.前言
最近在学习李宏毅老师的机器学习课程,不得不说讲得真的超详细,而且易懂。这里我放上B站的链接(戳我前往)以及百度AIstudio的链接(戳我前往),两个地方的课程内容都是一样的,只不过百度AIstudio上有相应课程的作业,但是用B站看的好处是有热心网友发弹幕解释英文的意思(李宏毅老师的PPT是全英文的,大佬请忽略),建议在B站看,然后在百度AIstudio上做作业。
2.概述
我们知道要判断一个模型的好坏,需要用到Loss函数,Loss值最小的模型肯定更有效、更精确,那么梯度下降的目的就是通过迭代找到Loss函数的最小值,当然也可以用在其他函数,只要函数是可微分的,都是可用梯度下降的。具体关于梯度下降的原理和数学解释就不多说了,一个博主已经写的非常好了(戳我前往),本文具体是简单讲一下李宏毅老师所讲解的关于梯度下降的三个优化方法。
3.学习率(Learning rate)
3.1 取值大小问题
梯度下降的数学公式: ![]()
γ就是学习率,也称为步长。许多文章包括李宏毅老师都是结合下山这个例子来讲解梯度下降的,我们需要通过不断迭代得到最小的θ值,即走到山谷的最低点。但是,学习率必须取得适当,不能大太也不能太小!
如果太小:太小会导致一直走不到山谷的最低点,也就是一直得不到最小的θ值,当然如果有足够做的时间,迟早也会走到最低点的,但这样的模型效率太低。
如果太大:太大会导致一步就跨很大,虽然速度快,但是可能会卡住,永远到不了最低点。甚至太大的话还可能导致θ值不降反升。
如下图所示
———取值刚好
———取值太小
———取值大
———取值太太太太大

3.2 解决方法
有三种解决方法:
① 可视化:可视化一个取不同学习率时Loss值随着迭代次数的变化图像,如下图(颜色对应上图):

当画出这个图后,你就可以通过选取不同的学习率来得到最适合的图像,从而得到适当的学习率。
②调学习率:我们可以把学习率设置成随着迭代次数的增多,学习率减小。因为当下山时,我们需要很快下山,所以前期步长都很大,但是当你快要到达山谷时,你就需要减小步长,以免跨得太大,错过了山谷。
t表示迭代次数
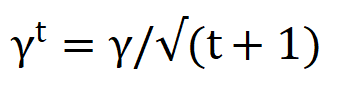
③自适应梯度算法(Adagrad):最好的办法是每一次迭代都设置不同的学习率,就需要使用自适应梯度算法。
原本的梯度下降公式:![]()
自适应梯度算法公式:![]() (σ表示过去所有微分值的均方根)
(σ表示过去所有微分值的均方根)
推导过程:下面将 ![]() 用g替代
用g替代

4.随机梯度下降(Stochastic Gradient Descent)
原本的梯度下降算法,每迭代一次需要带入所有数据,比如有一个数据集,其中有十组数据,那么就需要把所有的数据都带进去计算过后才能迭代一次,才会向前走一步;那么随机梯度下降的原理就是只取其中一组数据代入进去迭代,这样每取一组数据就能向前走一步。在数据量很大的时候,随机梯度算法可能不需要代入全部数据就能得到最小的Loss值了。

5.特征缩放(Feature Scaling)
5.1 为什么做特征缩放
特征缩放可用下图表示,即保证不同的特征的取值在相同或者相近的范围内,这样在使用梯度算法时就能提高收敛速度。

假如有这样一个函数:![]()
若W1的取值在range(1,10),而W2的取值在range(100,1000),那么W1的变化对y来说影响就会很小,W2的变化对y来说影响就会很大,这样就会导致梯度下降会走很多弯路,耗费更多时间,没有效率,而且需要很多组学习率才能到达圆心。而如果做特征缩放后,让W1和W2都在同一个范围,比如range(1,10),那么梯度下降就会变得很顺畅,节约时间。

5.2 怎样做特征缩放
做特征缩放有很多放多,比如最小-最大规范化、小数定标规范化,这里我们提一下李宏毅老师讲到的零均值规范化(Z-Score标准化)。
公式: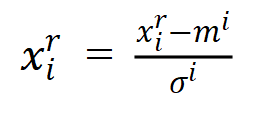 (
(![]() 为一行数据的均值,
为一行数据的均值,![]() 为一行数据的标准差,x是很多组数据,每个x里面都有一组特征)
为一行数据的标准差,x是很多组数据,每个x里面都有一组特征)
这样经过处理的数据均值为0,标准差为1。
