例如神经网络中的损失函数(loss function):
C
(
w
,
b
)
=
1
2
n
∑
x
∥
y
(
x
)
−
a
∥
2
C(w,b)=\frac{1}{2n}\sum_{x}\|y(x)-a\|^2
C ( w , b ) = 2 n 1 x ∑ ∥ y ( x ) − a ∥ 2
其中
w
w
w
b
b
b
x
x
x
n
n
n
y
(
x
)
y(x)
y ( x )
a
a
a
a
a
a
x
,
w
,
b
x,w,b
x , w , b
w
∗
w^*
w ∗
b
∗
b^*
b ∗
min
w
,
b
1
2
n
∑
x
∥
y
(
x
)
−
a
∥
2
\min \limits_{w,b} \frac{1}{2n}\sum_{x}\|y(x)-a\|^2
w , b min 2 n 1 x ∑ ∥ y ( x ) − a ∥ 2
我们可以采用梯度下降 (gradient descent)求解该问题。
对于多变量问题,常用的微积分解法效果有限;
对于神经网络而言,常常包含大量的变量,采用微积分最小化的方法失效
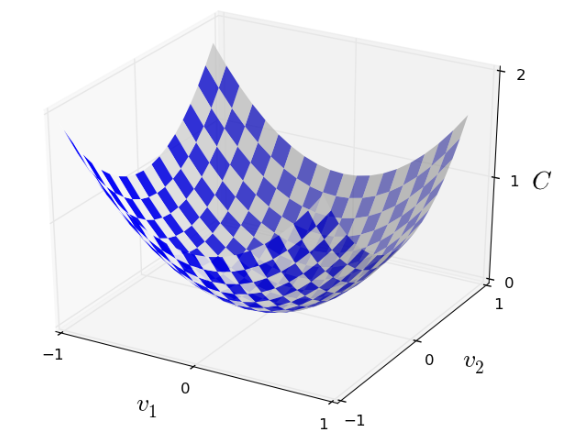
我们假设
C
(
v
)
C(v)
C ( v )
v
1
,
v
2
v_1,v_2
v 1 , v 2
为了找到
C
(
v
)
C(v)
C ( v )
C
(
v
)
C(v)
C ( v )
C
(
v
)
C(v)
C ( v )
为了实现这一过程,我们先假设 沿
v
1
v_1
v 1
Δ
v
1
\Delta{v_1}
Δ v 1
v
2
v_2
v 2
Δ
v
2
\Delta{v_2}
Δ v 2
C
(
v
)
C(v)
C ( v )
Δ
C
≈
∂
C
∂
v
1
Δ
v
1
+
∂
C
∂
v
2
Δ
v
2
\Delta{C}\approx\frac{\partial C}{\partial v_1}\Delta{v_1}+\frac{\partial C}{\partial v_2}\Delta v_2
Δ C ≈ ∂ v 1 ∂ C Δ v 1 + ∂ v 2 ∂ C Δ v 2
假设我们选择
Δ
v
1
\Delta v_1
Δ v 1
Δ
v
2
\Delta v_2
Δ v 2
Δ
C
<
0
\Delta C<0
Δ C < 0
C
C
C 现在的重点是我们如何选择这样的
Δ
v
=
(
∂
C
∂
v
1
,
∂
C
∂
v
2
)
T
\Delta v=(\frac{\partial C}{\partial v_1},\frac{\partial C}{\partial v_2})^T
Δ v = ( ∂ v 1 ∂ C , ∂ v 2 ∂ C ) T
Δ
C
<
0
\Delta C<0
Δ C < 0
这里我们首先来改写一下
Δ
C
\Delta C
Δ C
Δ
C
≈
∇
C
⋅
Δ
v
\Delta C\approx \nabla C \cdot \Delta v
Δ C ≈ ∇ C ⋅ Δ v
其中
∇
C
≡
(
∂
C
∂
v
1
,
∂
C
∂
v
2
)
T
\nabla C \equiv (\frac{\partial C}{\partial v_1},\frac{\partial C}{\partial v_2})^T
∇ C ≡ ( ∂ v 1 ∂ C , ∂ v 2 ∂ C ) T
∇
C
\nabla C
∇ C
C
C
C
v
v
v
为了选取合适的
Δ
v
\Delta v
Δ v
Δ
C
<
0
\Delta C<0
Δ C < 0
Δ
v
=
−
η
∇
C
\Delta v=-\eta \nabla C
Δ v = − η ∇ C
where
η
\eta
η
Δ
C
≈
−
η
∥
∇
C
∥
2
<
=
0
\Delta C \approx -\eta \| \nabla C \|^2<=0
Δ C ≈ − η ∥ ∇ C ∥ 2 < = 0
v
v
v
C
C
C
v
→
v
′
=
v
−
η
∇
C
v \rightarrow v^{'}=v-\eta \nabla C
v → v ′ = v − η ∇ C
Then we’ll use this update rule again, to make another move. If we keep doing this, over and over, we’ll keep decreasing
C
C
C
Summing up, the way the gradient descent algorithm works is to repeatedly compute the gradient
Δ
C
\Delta C
Δ C
关于learning rate
η
\eta
η
η
\eta
η
η
\eta
η
训练神经网络的目标是找到weights
w
k
w_k
w k
b
l
b_l
b l
C
C
C
w
k
→
w
k
′
=
w
k
−
η
∂
C
∂
w
k
w_k \rightarrow w_k^{'}=w_k- \eta \frac{\partial C}{\partial w_k}
w k → w k ′ = w k − η ∂ w k ∂ C
b
l
→
b
l
′
−
η
∂
C
∂
b
l
b_l \rightarrow b_l^{'}- \eta \frac{\partial C}{\partial b_l}
b l → b l ′ − η ∂ b l ∂ C
标准梯度下降法导致学习太慢的问题:损失函数
C
(
w
,
b
)
=
1
2
n
∑
x
∥
y
(
x
)
−
a
∥
2
C(w,b)=\frac{1}{2n}\sum_x\|y(x)-a\|^2
C ( w , b ) = 2 n 1 ∑ x ∥ y ( x ) − a ∥ 2
C
=
1
n
∑
x
C
x
C=\frac{1}{n}\sum_xC_x
C = n 1 ∑ x C x
C
x
≡
∥
y
(
x
)
−
a
∥
2
2
C_x \equiv \frac{\|y(x)-a\|^2}{2}
C x ≡ 2 ∥ y ( x ) − a ∥ 2
∇
C
=
1
n
∑
x
∇
C
x
\nabla C=\frac{1}{n}\sum_x \nabla C_x
∇ C = n 1 ∑ x ∇ C x
随机梯度下降可以用来加速学习: 其策略是,通过计算随机选取的一小部分训练样本的
∇
C
x
\nabla C_x
∇ C x
∇
C
\nabla C
∇ C
m
m
m
X
1
,
X
2
,
.
.
.
,
X
m
X_1, X_2,...,X_m
X 1 , X 2 , . . . , X m
m
m
m
m
≈
n
m\approx n
m ≈ n
∇
C
\nabla C
∇ C
∇
C
≈
1
m
∑
j
m
∇
C
X
i
\nabla C \approx \frac{1}{m} \sum_j^m \nabla C_{X_i}
∇ C ≈ m 1 j ∑ m ∇ C X i
因此,随机梯度下降的更新规则是:
w
k
→
w
k
′
=
w
k
−
η
m
∑
j
∂
C
X
j
∂
w
k
w_k \rightarrow w_k^{'}=w_k - \frac{\eta}{m}\sum_j \frac{\partial C_{X_j}}{\partial w_k}
w k → w k ′ = w k − m η j ∑ ∂ w k ∂ C X j
b
l
→
b
l
′
=
b
l
−
η
m
∑
j
∂
C
X
j
∂
b
l
b_l \rightarrow b_l^{'} = b_l - \frac{\eta}{m} \sum_j \frac{\partial C_{X_j}}{\partial b_l}
b l → b l ′ = b l − m η j ∑ ∂ b l ∂ C X j
具体执行过程是:先将数据集随机打乱然后均分成
k
k
k
标准梯度下降与随机梯度下降的比较 :
参考文献:
Neural Networks and Deep Learning by Michael A. Nielsen 机器学习,周志华