在机器学习领域,梯度下降有三种常见形式:批量梯度下降(BGD,batch gradient descent)、随机梯度下降(SGD,stochastic gradient descent)、小批量梯度下降(MBGD,mini-batch gradient descent)。它们的不同之处在于每次学习(更新模型参数)所使用的样本个数,也因此导致了学习准确性和学习时间的差异。
本文以线性回归为例,对三种梯度下降法进行比较。线性回归问题的损失函数如下:
其中, ,为需要拟合的函数;系数 的添加只是为了方便计算。
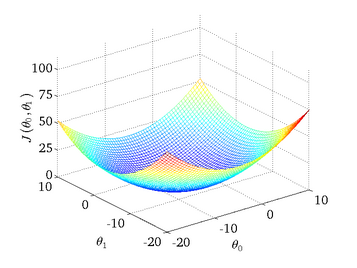
下图为一个二维参数组
对应的损失函数可视化图:
1、批量梯度下降
批量梯度下降,是梯度下降法最原始的形式,它的具体思路是在更新每一参数时都使用全量样本。
数学形式:
1、损失函数关于参数的偏导
2、按负梯度方向更新参数值
伪码形式:
for i in range(nb_epochs):#迭代次数
params_grad = evaluate_gradient(loss_function, data, params)
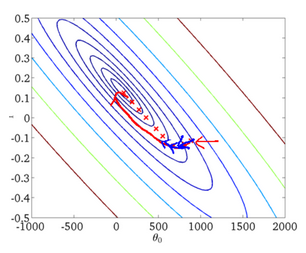
params = params - learning_rate * params_grad 批量梯度下降每次学习都使用整个训练集,因此其优点在于每次更新都会朝着正确的方向进行,最后能够保证收敛于极小值点(凸函数收敛于全局极小值点,非凸函数可能会收敛于局部极小值点),但是其缺点在于每次学习时间过长,如果训练集很大将会消耗大量内存,并且不能进行模型参数的在线更新(也就是不能在运行中加入新的样本进行运算)。
从迭代次数来看,BGD迭代的次数较少。其迭代的收敛曲线示意图表示如下:
2、随机梯度下降
为了解决批量梯度下降迭代速度太慢的问题,随机梯度下降每次从训练集中随机选择一个样本来进行学习。
数学形式:
1、损失函数关于参数的偏导
2、按负梯度方向更新参数值
伪码形式:

for i in range(nb_epochs):#迭代次数
np.random.shuffle(data)#每个epoch随机打乱数据
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
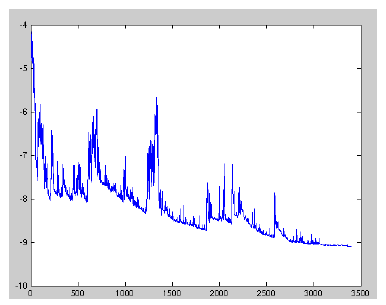
params = params - learning_rate * params_grad 随机梯度下降最大的缺点在于每次更新可能并不会按照正确的方向进行,因此会带来优化波动(扰动),如下图。一方面,对于类似盆地区域(即很多局部极小值点),这个波动可能会使得优化的方向从当前的局部极小值点跳到另一个更好的局部极小值点,这样便可能让非凸函数最终收敛于一个较好的局部极小值点,甚至全局极小值点;另一方面,波动会使得迭代次数(学习次数)增多,不过最终其会和批量梯度下降一样,具有相同的收敛性,即凸函数收敛于全局极小值点,非凸函数收敛于局部极小值点。
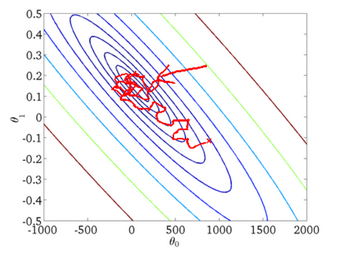
随机梯度下降,其实可以算作是一种online-learning,就是来了一条训练数据,算下此时根据模型算出的值和实际值的差距,如果差距大,那么参数更新的幅度大,反之则小。
从迭代次数来看,SGD迭代的次数较多,在解空间的搜索过程看起来很盲目。其迭代的收敛曲线示意图表示如下:
3、小批量梯度下降
小批量梯度下降综合了批量梯度下降与随机梯度下降,在迭代速度与迭代次数中间取得一个平衡,其每次更新从训练集中随机选择x个样本进行学习。
数学形式:
1、损失函数关于参数的偏导
2、按负梯度方向更新参数值
伪码形式:
for i in range(nb_epochs):#迭代次数
np.random.shuffle(data)#每个epoch随机打乱数据
for batch in get_batches(data, batch_size = x):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad相对于随机梯度下降,小批量梯度下降降低了收敛波动性,即降低了参数更新的方差,使得更新更加稳定;相对于批量梯度下降,其提高了每次迭代的速度,并且不用担心内存瓶颈从而可以利用矩阵运算进行高效计算。一般而言每次更新随机选择[50,256]个样本进行迭代,但是也要根据具体问题而选择,实践中可以进行多次试验,选择一个迭代速度与迭代次数都较适合的样本数。
4、总结
如果样本量比较小,采用批量梯度下降;如果样本量太大,或者在线算法,采用随机梯度下降;一般情况下,采用小批量梯度下降。
在神经网络训练过程中,很少使用随机梯度下降,因为小批量梯度下降可以利用矩阵和向量计算进行加速。通常我们讲随机梯度下降(SGD)时,也可以指代小批量梯度下降。
参考文献
[1] http://blog.csdn.net/u012526120/article/details/49183279
[2] http://blog.csdn.net/qer_computerscience/article/details/55061521
[3] http://blog.csdn.net/uestc_c2_403/article/details/74910107
[4] https://www.cnblogs.com/pinard/p/5970503.html
[5] http://blog.csdn.net/lilyth_lilyth/article/details/8973972
[6] http://www.cnblogs.com/maybe2030/p/5089753.html
[7] http://www.sohu.com/a/131923387_473283
[8] https://www.jianshu.com/p/c497b41f8caa
[9] https://www.jiqizhixin.com/articles/2016-11-21-4
以上为本文的全部参考文献,对原作者表示感谢。