转自:
http://blog.csdn.net/walilk/article/details/50978864
引言
机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归、逻辑回归、Softmax回归、神经网络和SVM等等,主要学习资料来自网上的免费课程和一些经典书籍,免费课程例如Standford Andrew Ng老师在Coursera的教程以及UFLDL Tutorial,经典书籍例如《统计学习方法》等,同时也参考了大量网上的相关资料(在后面列出)。
前言
机器学习中的大部分问题都是优化问题,而绝大部分优化问题都可以使用梯度下降法处理,那么搞懂什么是梯度,什么是梯度下降法就非常重要!这是基础中的基础,也是必须掌握的概念!
提到梯度,就必须从导数(derivative)、偏导数(partial derivative)和方向导数(directional derivative)讲起,弄清楚这些概念,才能够正确理解为什么在优化问题中使用梯度下降法来优化目标函数,并熟练掌握梯度下降法(Gradient Descent)。
本文主要记录我在学习机器学习过程中对梯度概念复习的笔记,主要参考《高等数学》《简明微积分》以及维基百科上的资料为主,文章小节安排如下:
1)导数
2)导数和偏导数
3)导数与方向导数
4)导数与梯度
5)梯度下降法
6)参考资料
7)结语
导数
一张图读懂导数与微分:
这是高数中的一张经典图,如果忘记了导数微分的概念,基本看着这张图就能全部想起来。
导数定义如下:
反映的是函数y=f(x)在某一点处沿x轴正方向的变化率。再强调一遍,是函数f(x)在x轴上某一点处沿着x轴正方向的变化率/变化趋势。直观地看,也就是在x轴上某一点处,如果f’(x)>0,说明f(x)的函数值在x点沿x轴正方向是趋于增加的;如果f’(x)<0,说明f(x)的函数值在x点沿x轴正方向是趋于减少的。

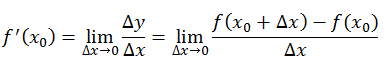
这里补充上图中的Δy、dy等符号的意义及关系如下:
Δx:x的变化量;
dx:x的变化量Δx趋于0时,则记作微元dx;
Δy:Δy=f(x0+Δx)-f(x0),是函数的增量;
dy:dy=f’(x0)dx,是切线的增量;
当Δx→0时,dy与Δy都是无穷小,dy是Δy的主部,即Δy=dy+o(Δx).
导数和偏导数
偏导数的定义如下:
可以看到,导数与偏导数本质是一致的,都是当自变量的变化量趋于0时,函数值的变化量与自变量变化量比值的极限。直观地说,偏导数也就是函数在某一点上沿坐标轴正方向的的变化率。
区别在于:
导数,指的是一元函数中,函数y=f(x)在某一点处沿x轴正方向的变化率;
偏导数,指的是多元函数中,函数y=f(x1,x2,…,xn)在某一点处沿某一坐标轴(x1,x2,…,xn)正方向的变化率。
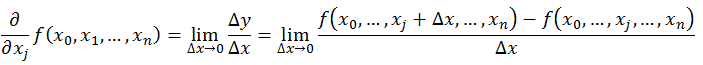
导数与方向导数:
方向导数的定义如下:
在前面导数和偏导数的定义中,均是沿坐标轴正方向讨论函数的变化率。那么当我们讨论函数沿任意方向的变化率时,也就引出了方向导数的定义,即:某一点在某一趋近方向上的导数值。
通俗的解释是:
我们不仅要知道函数在坐标轴正方向上的变化率(即偏导数),而且还要设法求得函数在其他特定方向上的变化率。而方向导数就是函数在其他特定方向上的变化率。
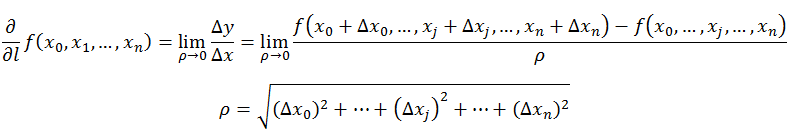
导数与梯度
梯度的定义如下:
梯度的提出只为回答一个问题:
函数在变量空间的某一点处,沿着哪一个方向有最大的变化率?
梯度定义如下:
函数在某一点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。
这里注意三点:
1)梯度是一个向量,即有方向有大小;
2)梯度的方向是最大方向导数的方向;
3)梯度的值是最大方向导数的值。
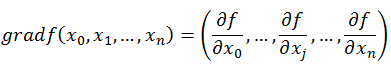
导数与向量
提问:导数与偏导数与方向导数是向量么?
向量的定义是有方向(direction)有大小(magnitude)的量。
从前面的定义可以这样看出,偏导数和方向导数表达的是函数在某一点沿某一方向的变化率,也是具有方向和大小的。因此从这个角度来理解,我们也可以把偏导数和方向导数看作是一个向量,向量的方向就是变化率的方向,向量的模,就是变化率的大小。
那么沿着这样一种思路,就可以如下理解梯度:
梯度即函数在某一点最大的方向导数,函数沿梯度方向函数有最大的变化率。
梯度下降法
既然在变量空间的某一点处,函数沿梯度方向具有最大的变化率,那么在优化目标函数的时候,自然是沿着负梯度方向去减小函数值,以此达到我们的优化目标。
如何沿着负梯度方向减小函数值呢?既然梯度是偏导数的集合,如下:
同时梯度和偏导数都是向量,那么参考向量运算法则,我们在每个变量轴上减小对应变量值即可,梯度下降法可以描述如下:
以上就是梯度下降法的由来,大部分的机器学习任务,都可以利用Gradient Descent来进行优化。
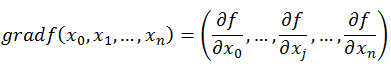
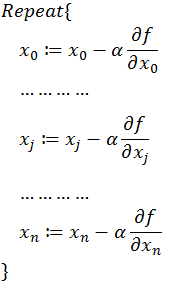
参考资料
参考书:
《高等数学》
《简明微积分》
参考链接:
梯度
https://zh.wikipedia.org/zh-cn/%E5%81%8F%E5%AF%BC%E6%95%B0
方向导数和梯度
http://blog.csdn.net/wolenski/article/details/8030654
附:
维基百科的可用Hosts文件
http://www.williamlong.info/archives/4456.html
结语
以上就是我在回顾导数、偏导数、梯度等概念时的一些笔记,希望可以为大家提供一些帮助,也欢迎交流讨论,谢谢!
本文的文字、公式和图形都是笔者根据所学所看的资料经过思考后认真整理和撰写编制的,如有朋友转载,希望可以注明出处:
[机器学习] ML重要概念:梯度(Gradient)与梯度下降法(Gradient Descent)
http://blog.csdn.net/walilk/article/details/50978864
·