梯度下降法(gradient descent)或最速下降法(steepest descent)是求解无约束优化问题的一种最常用的方法,实现简单,属于一阶优化算法,也是迭代算法。
1.梯度
在微积分中,对多元函数的参数求偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。比如函数
,分别对
求偏导数,求得的梯度向量就是
,记为
或
。在点
处的具体梯度向量就是
,或
。
梯度向量的一般表示可以写成:
从几何意义上讲,函数上某一点的梯度向量,就是函数变化增加最快的地方。具体来说,对于函数 ,在点 沿着梯度向量的方向,即 ,是 增加最快的地方。或者说沿着梯度向量的方向,更容易找到函数的极大值。反过来说,沿着梯度向量相反的方向,即 , 减少最快,更容易找到函数的极小值。
2.梯度下降
假设
是
上具有一阶连续偏导数的函数,要求解的无约束最优化问题是:
表示目标函数的极小点。下面我们考虑采用梯度下降法来求解这个问题。
根据上一节关于梯度的阐述,我们已经了解,负梯度方向是使函数值下降最快的方向,基于此,可以得到梯度下降法的原理:选取适当的初值 ,不断迭代,在迭代的每一步,以负梯度方向更新 的值,进行目标函数的极小化,直到收敛。完整的算法描述如下:
输入:目标函数 ,计算精度 ;
输出: 的极小值点 ;
(1).取初始值 ,置 ;
(2).计算 ;
(3).计算梯度 ,若 ,停止迭代,令 ;否则,转(4);
(4).置 ,计算 ,当 或 时,停止迭代,令 ;否则,转(3);
其中, 是迭代步长,或称学习率(learning rate),在每次迭代中, 是可变的。值得注意的是, 的取值很有讲究,取值太大,容易跨过极小值点,取值太小,收敛太慢。因此,需不断测试,直至找到一个最合适的 。
下面我们用一张图来形象化地表述梯度下降法:
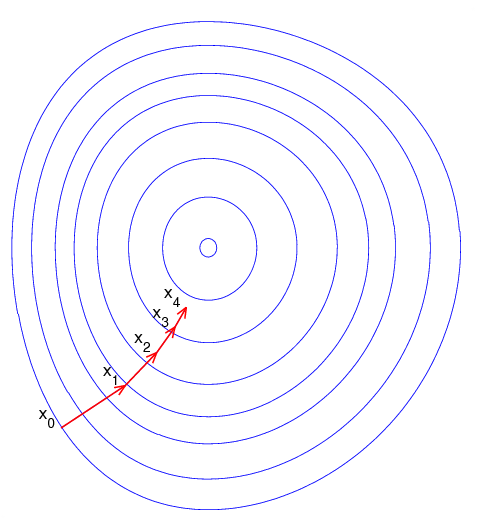
这里假设 定义在平面上,并且函数图像是一个碗形。蓝色的曲线是等高线(水平集),即函数 为常数的集合构成的曲线。红色的箭头指向该点梯度的反方向(一点处的梯度方向与通过该点的等高线垂直)。沿着梯度下降方向,将最终到达碗底,即函数 的极小值点。
3.特点和问题
特点
- 对输入向量进行归一化处理,可以让梯度下降更好更快地收敛;
问题:
- 只有当目标函数是凸函数时,梯度下降法的解是全局最优解,一般情况下,其解不保证是全局最优解;
- 靠近极小值时速度减慢;
- 如何确定学习率,可以参考这篇文章;
参考文献
[1] 《统计学习方法》
[2] https://baike.baidu.com/item/%E6%A2%AF%E5%BA%A6/13014729
[3] https://zhuanlan.zhihu.com/p/31074506
[4] http://blog.csdn.net/xiazdong/article/details/7950084
[5] https://www.cnblogs.com/pinard/p/5970503.html
[6] https://www.cnblogs.com/zhenggege/p/7210755.html
[7] https://www.zhihu.com/question/54097634
[8] https://www.cnblogs.com/keguo/p/6244253.html
[9] https://zh.wikipedia.org/wiki/%E6%A2%AF%E5%BA%A6%E4%B8%8B%E9%99%8D%E6%B3%95
以上为本文的全部参考文献,对原作者表示感谢。