1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN),在此简单的介绍一下 自己的理解。卷积神经网络与普通神经网络的区别在于:
卷积神经网络比神经网络多包含了一个由卷积层和子采样层构成的特征抽取器。在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。
在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数。 以上就是 卷积神经网络的简单介绍。
1.1 用简单的话来解释一下 卷积神经网络:
划重点
当我们的图片(黑白图片厚度为1 ,彩色图片厚度为3)输入到神经网络后,我门会通过卷积神经网络将图片的长和宽进行压缩,然后把厚度增加。最后就变成了一个长宽很小,厚度很高的像素块。然后结果放入普通的神经网络中处理,最后链接一个分类器,从而分辨出图片是什么。
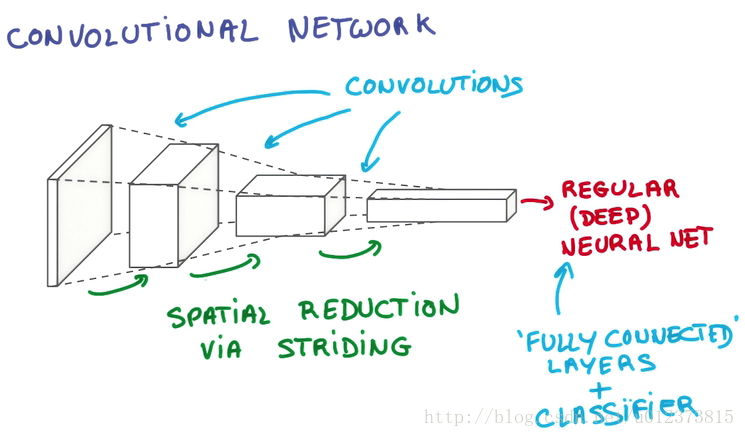
1.2 假设人脑cnn识别美女

当我们识别一张美女的照片的时候其实也是从局部到全局,比如说看一个人先看到一个人的鼻子然后,再看到一个人的眼睛,接着是嘴巴等等,这个时候就是我门脑子在提取图片的有用信息,此时我门的眼睛就像是一个采样器,在采集图片每个部位的信息。然后把每个部位的信息增加,比如说我门知道了鼻子是挺的,眼睛是双眼皮之类。接着脑子把提取的信息在脑子里进行一个合并,此时图片的大小在我门脑子里已经变小了(因为只存储了有用的信息,像人物背景的信息,已经被我们过滤掉了),这个图片变小的动作就是池化,最后脑子把收集到的信息在脑子里无限的提取和合并,就得出整张图片的信息,我门再拿着整张图片的信息在我门的记忆库中去寻找对比,最后得出结论这个人是谁。
1.3 CNN的重要组成
1.3.1 卷积核 (patch/keruel)
图片的采样器也可以叫做共享权值,用来在图片上采集信息。卷积核有自己的长宽,也可以定义自己的步长stride ,每跨多少步进行一次抽离信息,跨的步长越多就越容易丢失图片信息。然后对抽取的信息进行像素的加权求和得到Feature Map 增加了采集结果的厚度。
总而言之 卷积是用来不断的提取特征,每提取一个特征就会增加一个feature map,所以采集后的图片厚度不断变厚
- stride patch每次跨多少像素去抽离信息
- Feature Map:每层Conv网络,因为它们将前一层的feature映射到后一层(Output map)
如图:
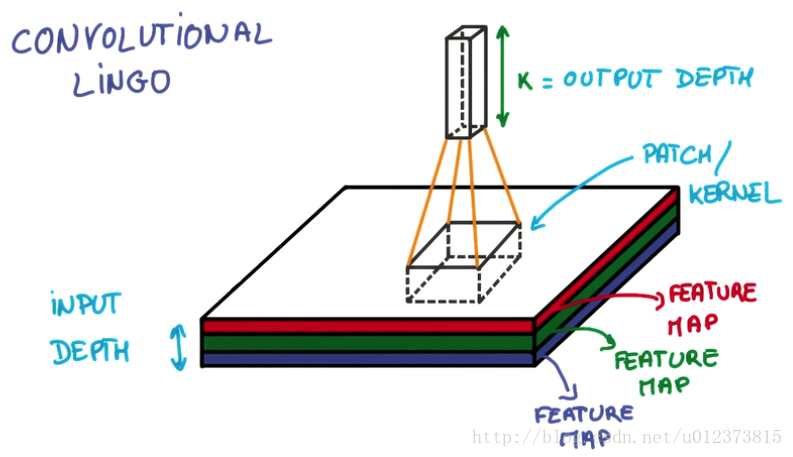
patch 为卷积核,有长宽高,K为对抽取的信息进行像素的加权求和返回的信息,厚度变厚了。
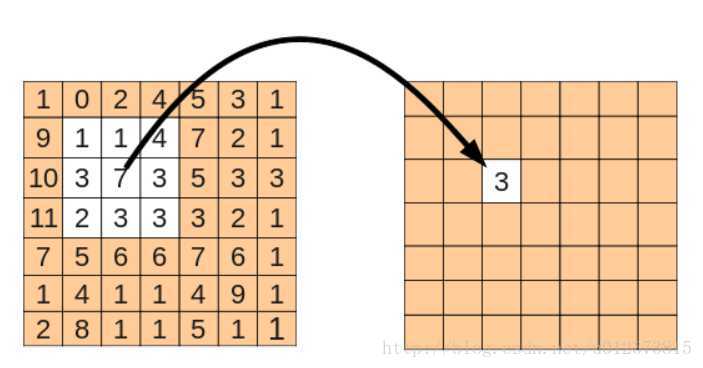
对采集信息的计算如下图,将 采集核的信息信息进行加权求和,返回对应位置的信息。当然如果要采集边缘信息时会有两种策略,
- valid padding: 移动到边缘上的时候,如果不超出边缘,3x3的中心就到不了边界,因此得到的内容就会缺乏边界的一圈像素点。这种抽取叫做 valid padding 抽离后的数据比原数据的长和宽进行了裁剪
- same padding:而可以越过边界的情况下,就可以让3x3的中心到达边界的像素点
超出部分的矩阵补零就行。same padding 抽离后的数据和原数据的长和宽相同
如果使用采集器跨度太大(大于1),就会丢掉很多有用信息,但是我又要图片不断的缩小,这个时候呢,我就加一个 pooling 层,用于减减小相邻像素点的差异,从而丢掉一些像素点也不会丢失太多的图片信息。
1.3.2 池化(pooling)
pooling层也就是下采样也就是减小临近像素的差异值,并缩小或者不缩小图片(一般选择缩小)。pooling 分多种例如:
- Max Pooling 在一个卷积层的输出层上取一个切片,取其中最大值代表这个切片
- Average Pooling 在卷积层输出中,取切片,取平均值代表这个切片
这里就解释一下最大池化的实现:
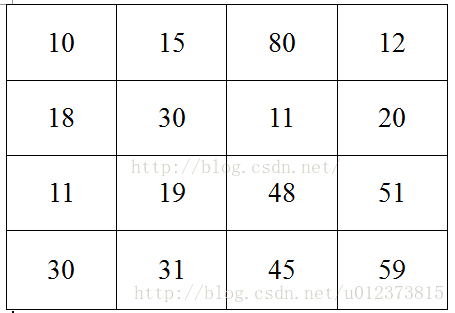
上面的图片作为例子,假设上面的图片大小是4*4的,如上图所示,然后图片中每个像素点的值是上面各个格子中的数值。然后我要对这张4*4的图片进行池化,池化的大小为(2,2),跨步为2,那么采用最大池化也就是对上面4*4的图片进行分块,每个块的大小为2*2,然后统计每个块的最大值,作为下采样后图片的像素值,具体计算如下图所示:

最后得到的下采样后的图片为:
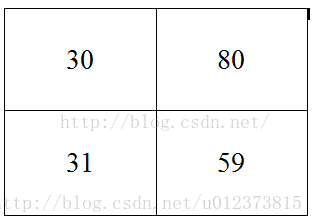
这就是所谓的最大池化。当然以后你还会遇到各种池化方法,Mean pooling(均值采样)、Max pooling(最大值采样)、Overlapping (重叠采样)、L2 pooling(均方采样)、Local Contrast Normalization(归一化采样)、Stochasticpooling(随即采样)、Def-pooling(形变约束采样)等等。
2 卷积神经网络之MNIST
关于处理数据和构建神经网络 请参照博客 TensorFlow 入门之第一个神经网络和训练 MNIST
模型如下:
# -*- coding: utf-8 -*-
# 手写数字识别
# 准确度 0.9679
import 手写数字识别.input_data
import tensorflow as tf
mnist = 手写数字识别.input_data.read_data_sets("手写数字识别/MNIST_data/", one_hot=True)
def compute_accuracy(v_xs,v_ys):
# 定义 prediction 为全局变量
global prediction
# 将 xs data 在 prediction 中生成预测值,预测值也是一个 1*10 的矩阵 中每个值的概率,并不是一个0-9 的值,是0-9 每个值的概率 ,比如说3这个位置的概率最高,那么预测3就是这个图片的值
y_pre = sess.run(prediction, feed_dict={xs: v_xs,keep_prob: 1})
# 对比我的预测值y_pre 和真实数据 v_ys 的差别
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1))
# 计算我这一组数据中有多少个预测是对的,多少个是错的
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# result 是一个百分比,百分比越高,预测越准确
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys,keep_prob: 1})
return result
#我们定义Weight变量,输入shape,返回变量的参数。其中我们使用tf.truncted_normal产生随机变量来进行初始化
def weight_variable(shape):
#google 也是用truncted_normal 来产生随机变量
initial = tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial)
#定义biase变量,输入shape ,返回变量的一些参数。其中我们使用tf.constant常量函数来进行初始化
def bias_variable(shape):
#定义成 0.1之后才会从0.1变到其他的值, bias通常用正直比较好,所以我们用0.1
initial = tf.constant(0.1,shape=shape)
return tf.Variable(initial)
#定义卷积,tf.nn.conv2d函数是tensoflow里面的二维的卷积函数,x是图片的所有参数,W是此卷积层的权重
def conv2d(x,W):
#定义步长strides=[1,1,1,1]值,strides[0]和strides[3]的两个1是默认值,中间两个1代表padding时在x方向运动一步,y方向运动一步
#padding采用的方式是SAME。
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
#定义池化pooling x 为conv2d 的返回 ,在pooling 阶段图片的长和宽被减小
def max_poo_2x2(x):
#步长strides=[1,2,2,1]值,strides[0]和strides[3]的两个1是默认值,中间两个2代表padding时在x方向运动两步,y方向运动两步
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
xs = tf.placeholder(tf.float32,[None, 784]) #图像输入向量 每个图片有784 (28 *28) 个像素点
ys = tf.placeholder(tf.float32, [None,10]) #每个例子有10 个输出
keep_prob = tf.placeholder(tf.float32)
# 处理输入图片的信息 把xs的形状变成[-1,28,28,1],-1代表先不考虑输入的图片例子多少这个维度,28 28 代表的是长和宽 后面的1是channel的数量,因为我们输入的图片是黑白的,因此channel是1,例如如果是RGB图像,那么channel就是3
xs_image = tf.reshape(xs,[-1,28,28,1])
# print(xs_image.shape)
# 第一层##
# 定义本层的Weight,本层我们的卷积核patch的大小是5x5,因为黑白图片channel是1 是图片的厚度 所以输入是1 彩色的厚度是3,输出是32个featuremap
W_conv1 = weight_variable([5,5,1,32])
# 大小是32个长度,因此我们传入它的shape为[32]
b_conv1= bias_variable([32])
# 卷积神经网络的第一个卷积层, 对h_conv1进行非线性处理,也就是激活函数来处理 tf.nn.relu(修正线性单元)来处理,要注意的是,因为采用了SAME的padding方式,
# 输出图片的大小没有变化依然是28x28,只是厚度变厚了,因此现在的输出大小就变成了28x28x32
h_conv1 =tf.nn.relu(conv2d(xs_image,W_conv1) + b_conv1)
# 经过pooling的处理,输出大小就变为了14x14x32
h_pool1 = max_poo_2x2(h_conv1)
# 第二层##
# 定义本层的Weight,本层我们的卷积核patch的大小是5x5,32 是图片的厚度,输出是64个featuremap
W_conv2 = weight_variable([5,5,32,64])
# 大小是64个长度,因此我们传入它的shape为[64]
b_conv2= bias_variable([64])
# 卷积神经网络的第二个卷积层, 对h_conv2进行非线性处理,也就是激活函数来处理 tf.nn.relu(修正线性单元)来处理,要注意的是,因为采用了SAME的padding方式,
# 输出图片的大小没有变化依然是14x14,只是厚度变厚了,因此现在的输出大小就变成了14x14x64
h_conv2 =tf.nn.relu(conv2d(h_pool1,W_conv2) + b_conv2)
# 经过pooling的处理,输出大小就变为了7x7x64
h_pool2 = max_poo_2x2(h_conv2)
#func1 layer##
# 参考上面注释
W_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
# 通过tf.reshape()将h_pool2的输出值从一个三维的变为一维的数据, -1表示先不考虑输入图片例子维度, 将上一个输出结果展平,
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64]) #[n_samples,7,7,64]->>[n_samples,7*7*64]
# 将展平后的h_pool1_flat与本层的W_fc1相乘(注意这个时候不是卷积了)
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1)
# 考虑过拟合问题,可以加一个dropout的处理
h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob)
#func2 layer##
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
# 预测值,prediction 用softmax 处理 计算概率
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2)
#loss函数(即最优化目标函数)选用交叉熵函数。交叉熵用来衡量预测值和真实值的相似程度,如果完全相同,它们的交叉熵等于零 ,所以loss 越小 学的好
#分类一般都是 softmax+ cross_entropy
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1]))
# cross_entropy = -tf.reduce_sum(ys*tf.log(prediction))
#train方法(最优化算法)AdamOptimizer()作为我们的优化器进行优化 ,AdamOptimizer 适合比较庞大的系统 ,1e-4 0.0004
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
sess = tf.Session()
# 初始化变量
init= tf.global_variables_initializer()
sess.run(init)
for i in range(1000):
#开始train,每次只取100张图片,免得数据太多训练太慢
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys,keep_prob: 0.5})
if i % 50 == 0:
print(compute_accuracy(
mnist.test.images, mnist.test.labels))本文源代码:
https://github.com/527515025/My-TensorFlow-tutorials/blob/master/tensorflow_11_CNN_%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C.py
欢迎 start
参考:https://www.bilibili.com/video/av16001891/index_26.html#page=26
http://blog.csdn.net/hjimce/article/details/47323463
https://www.zhihu.com/question/39022858
http://blog.csdn.net/u011453773/article/details/51597072