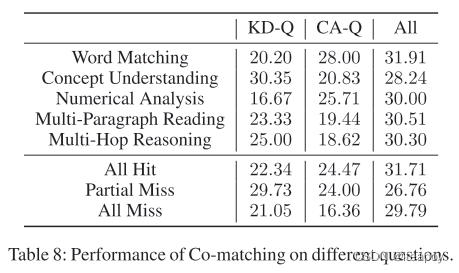
- 数据来源:中国国家司法考试
- 模型准确率 28%,专业人士可以达到81%,非专业人士可以达到64%
- 数据集下载链接:http://jecqa.thunlp.org/
- 代码链接:https://github.com/thunlp/jec-qa
- 检索工具:https://www.elastic.co/cn/
介绍
LQA 为法律案件提供解释、建议、解决方法,一方面为非专业人士提供法律援助、法律咨询,另一方面帮助专业人士提高工作效率,更准确地分析真实案件。
LQA的问题可以分为两大类:
-
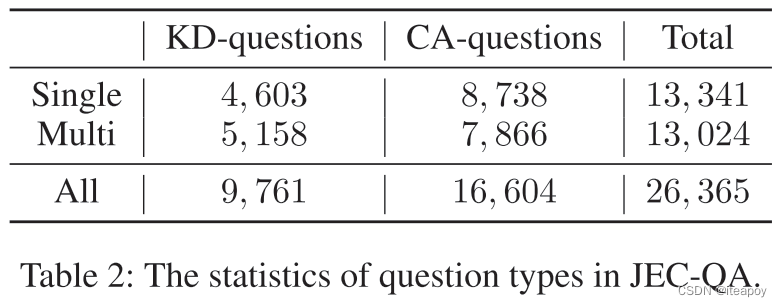
KD-question:knowledge-driven,知识驱动,注重理解法律概念
-
CA-question:case-analysis,案件驱动,注重分析更多的实际案例
-
包含26,365个选择题,每个问题4个选项,有单选也有多选
-
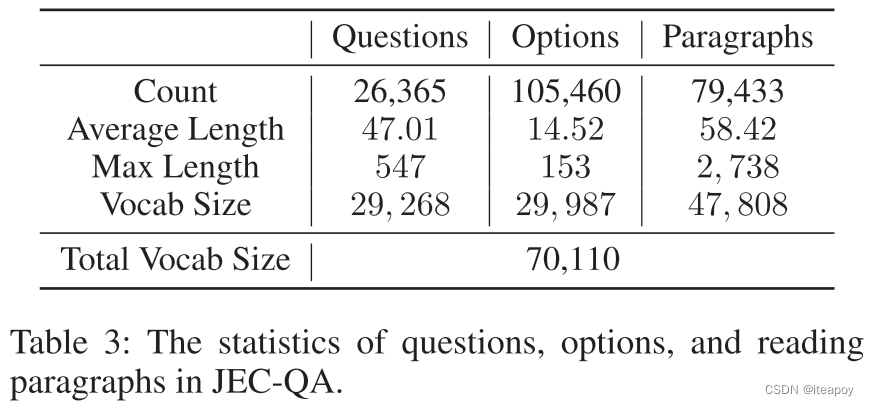
提供了一个数据库,包含所有需要的法律知识/法条
-
JEC-QA给每个问题提供了额外的标签,如问题类型(KD/CA问题)以及问题需要的reasoning,由专业人士标注的数据,有利于LQA的深度分析
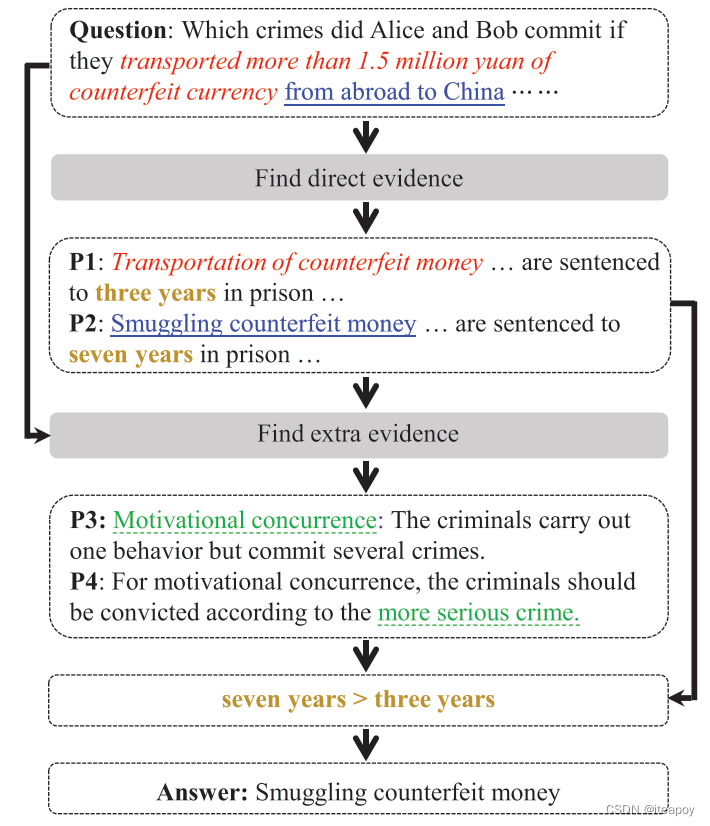
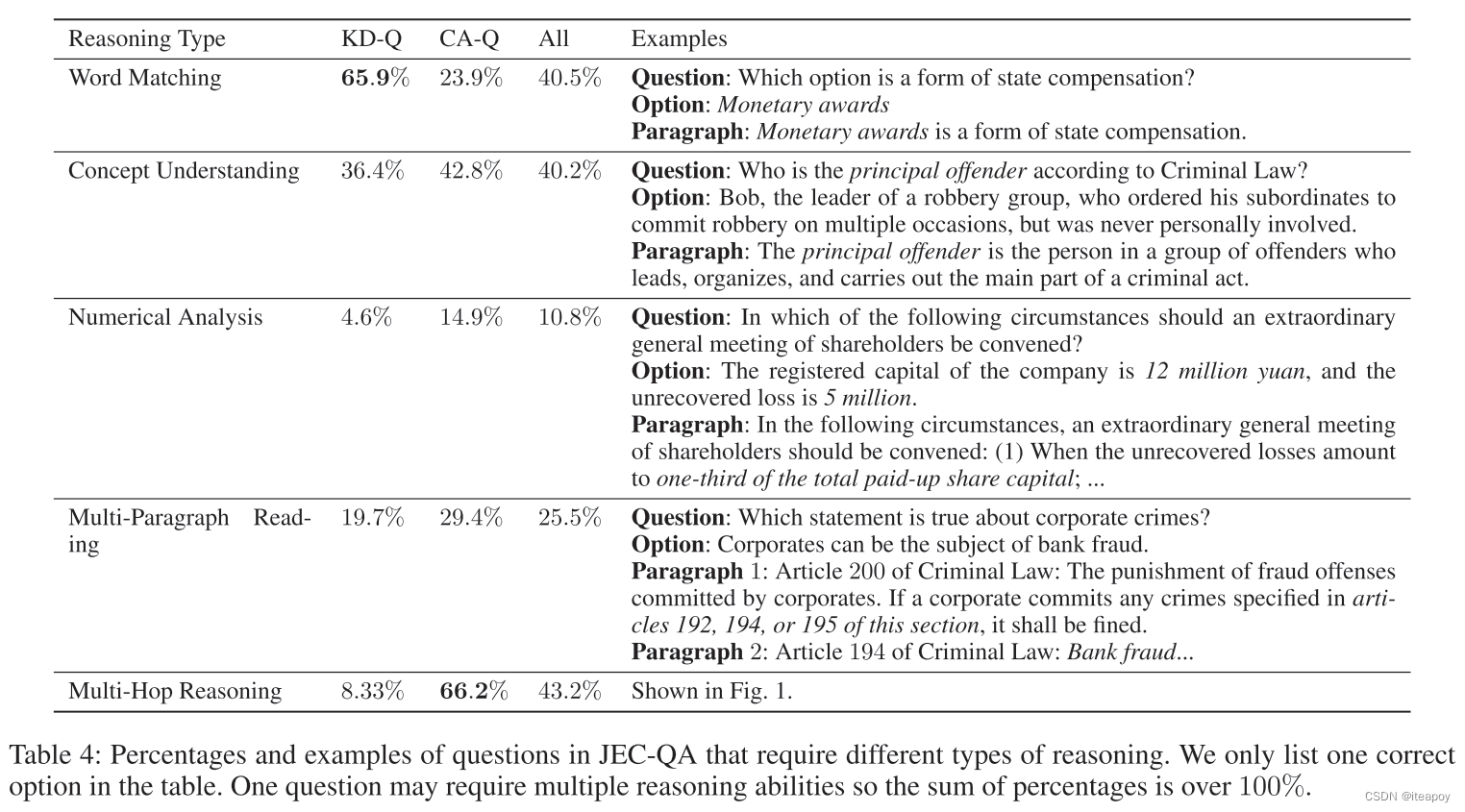
JEC-QA需要单词匹配、概念理解、数学分析、多篇长阅读和多跳推理。
e.g.
相关工作
Open QA
需要外部领域的知识,第一步检索(https://www.elastic.co/cn/),第二步将模型用在QA模型上给出答案
数据集
【样本量】
【数据库】
- 司法考试的参考书包含15个主题,215章
【推理类型】
- 单词匹配
最简单的一种推理,和传统QA类似 - 概念理解
法律领域,模型需要去理解法律概念 - 数学分析
需要进行一些简单的运算,来回答问题 - 多篇章阅读
需要阅读多个段落,整合足够多的证据 - 多跳推理
需要多步完成逻辑推理,得到回答
实验
检索策略
总共有15个主题,用三个现有的模型去进新主题分类
- BERT
- TextCNN
- DPCNN
选择用BERT找到TOP2的topic。基于检索到的材料,46%的问题可以回答正确,KD问题显著高于CA问题
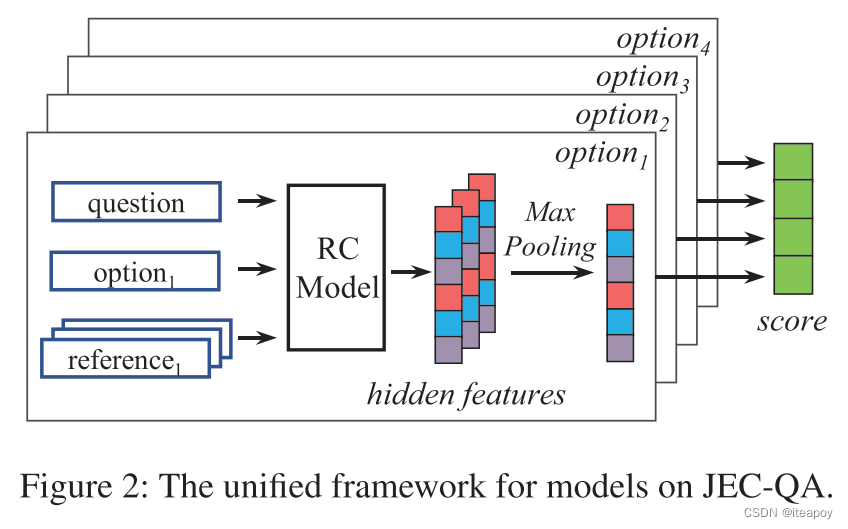
输入三元组 ( q , o , r ) (q,o,r) (q,o,r), 表示问题,选项和检索到的阅读理解的篇章
- q 是词序列
- o 是一个 n = 4 n=4 n=4 的词序列,表示为 ( ( o 1 , 1 , o 1 , 2 , … , o 1 , ∣ o 1 ∣ ) , … , ( o n , 1 , … , o n , ∣ o n ∣ ) ) \left(\left(o_{1,1}, o_{1,2}, \ldots, o_{1,\left|o_1\right|}\right), \ldots,\left(o_{n, 1}, \ldots, o_{n,\left|o_n\right|}\right)\right) ((o1,1,o1,2,…,o1,∣o1∣),…,(on,1,…,on,∣on∣))
- 假设每个选项,有 m = 18 m=18 m=18个阅读篇章, r i , j r_{i,j} ri,j 表示第 i i i 个选项的第 j j j 个阅读篇章,即 r i , j = ( r i , j , 1 , r i , j , 2 , … , r i , j , ∣ r i , j ∣ ) r_{i,j}=\left(r_{i, j, 1}, r_{i, j, 2}, \ldots, r_{i, j,\left|r_{i, j}\right|}\right) ri,j=(ri,j,1,ri,j,2,…,ri,j,∣ri,j∣),其中 i ∈ [ 1 , n ] i\in[1,n] i∈[1,n], j ∈ [ 1 , m ] j\in[1,m] j∈[1,m]
- 对于输出,有两个不同的任务,即回答单项选择,回答多项选择题
- 对于单项选择题,需要进行单标签分类,给每个问题输出一个评分向量 s c o r e s i n g l e ∈ R n score^{single}\in \mathbb{R}^n scoresingle∈Rn,表示每个选项是正确的概率
- 对于多项选择题,需要输出评分向量 s c o r e a l l score^{all} scoreall,每个问题的长度为 2 n − 1 2^n-1 2n−1
对一些不适用的模型进行了改动:
- 假设原模型只能输入问题和篇章,没有选项,就将问题和每个选项拼接,获得每个选项的分数 s i s_i si,然后 score s i n g l e = [ s 1 , s 2 , … , s n ] \text{score}^{single} =\left[s_1, s_2, \ldots, s_n\right] scoresingle=[s1,s2,…,sn]
- 如果原模型只能从阅读理解片段中抽出答案,就把输出层修改成线性层,输出打分 s i s_i si
- 如果原模型不能用于多篇章阅读理解任务,就单独在每个选项的每个篇章上应用该模型,模型输出隐藏层 h i , j ∈ R d h_{i, j} \in \mathbb{R}^d hi,j∈Rd 表示第 i i i 个选项的第 j j j 层,然后在同一个选项的所有表示上用 max-pooling,来得到第 i i i 个选项的隐藏层表示 h i ′ = [ h i , 1 ′ , h i , 2 ′ , … , h i , d ′ ] h_i^{\prime}=\left[h_{i, 1}^{\prime}, h_{i, 2}^{\prime}, \ldots, h_{i, d}^{\prime}\right] hi′=[hi,1′,hi,2′,…,hi,d′],其中 max ( h i , k , j ∣ ∀ 1 ≤ k ≤ m ) \max \left(h_{i, k, j} \mid \forall 1 \leq k \leq m\right) max(hi,k,j∣∀1≤k≤m),然后将 h i ′ h_i^{\prime} hi′ 通过线性层得到第 i i i 个选项的分数 s i s_i si
- 将 score s i n g l e \text{score}^{single} scoresingle 输入到线性层中,去获得回答所有问题的 s c o r e a l l score^{all} scoreall
随机选择 20% 作为测试集
baseline
- co-matching:a single-paragraph reading comprehension model for single-answer questions
- BERT:a single-paragraph reading comprehension model,用在中文文档上训练的bert
- SeaReader:医学领域问答,用三种注意力方式,question-centric attention, document-centric attention, cross-document attention,再用一个门层去去噪
- Multi-Matching:用 Evidence-Answer matching 和 Question-Passage-Answer matching模块来生成匹配信息,拼合起来得到候选项的分数
- Convolutional Spatial Attention (CSA) :先用注意力机制得到文章、候选答案、问题的标识,再用CNN-MaxPooling去总结邻接注意力信息
- Confidence-based Model (CBM) :multi-paragraph reading comprehension,pipeline 用于 single-paragraph 阅读理解,应用 confidence-based method 将模型用于 multi-paragraph 上
- Distantly Supervised Question Answering (DSQA) :用于 open QA,将QA分解,首先过滤掉噪声文档,然后抽取正确信息,选出最好的选项
实验结果