在目前的视频超分研究中,可变形卷积应用效果得到了非常大的认可,在与传统光流或者深度学习光流网络计算光流的直接pk中,因为其直接在特征域计算对齐的特性,在EDVR等网络实践中效果更佳。
1. 原文解读
Deformable Convolutional Networks-PDF
Deformable Convolutional Networks-slides
1.1 背景
在计算机视觉领域,同一物体在不同场景,角度中未知的几何变换是检测/识别的一大挑战,通常来说我们有两种做法:
(1)通过充足的数据增强,扩充足够多的样本去增强模型适应尺度变换的能力。
(2)设置一些针对几何变换不变的特征或者算法,比如SIFT和sliding windows。

两种方法都有缺陷,第一种方法因为样本的局限性显然模型的泛化能力比较低,无法泛化到一般场景中,第二种方法则因为手工设计的不变特征和算法对于过于复杂的变换是很难的而无法设计。所以作者提出了Deformable Conv(可变形卷积)和 Deformable Pooling(可变形池化)来解决这个问题。
文章提出的比较早,针对可变形池化还专门做了优化与讲解,现在池化操作已经越来越多的被结合convolution的stride取代。
1.2 思路

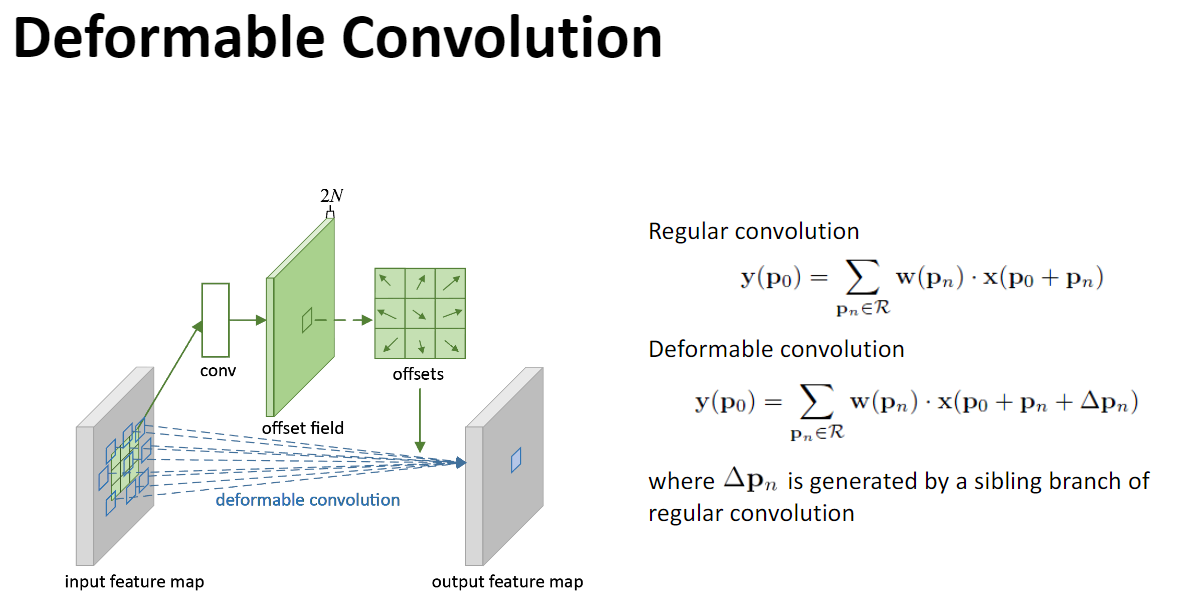
offset层数是由kernel size决定的,他一定是输出2*kernel size*kernel size数目的channel,这一点可以类比光流图的输出结果进行比对,因为kernel内部每一个点都需要有X和Y两个方向的位移。比如kernel size数值为3,则offset层的输出结果一定是含有18层,kernel size的数值为5则输出结果一定为50层。
这一点也可以通过原论文来进行解释,可以看到R就是kernel的行列式定义,kernal size=3的时候,则|R|=9。而上图中涉及到的N值则是与R相同,offset field数值为2N,则与推理的数据保持一致。

实际上在实现上,可变形卷积一共有两种思路:可以参考blogDeformable ConvNets–Part5: TensorFlow实现Deformable ConvNets下面的讨论。
Function 1:
按照论文所说,offset层输出结果是2N的卷积核偏移量;卷积得出的是(Batch,H,W,2N),2N分成代表卷积核横向x的(3,3)各个偏移值,代表卷积核纵向y的(3,3)各个偏移值,对特征图卷积的时候,根据2N个偏移值计算卷积核对应的9个新位置,对这九个新位置作(3,3)形变卷积。
b*h*w*c 的input map相对应的offset层形状为 b*h*w*c*2N,可以理解是对卷积核进行了旋转平移缩放的操作,然后与卷积层进行rule based convolution。
Function 2:
直接将卷积核的偏移量等量替代为feature map上的位移量,可以理解特征图进行了旋转平移缩放的操作,详细操作可以参考1.2的可变形卷积流程。
2. 可变形卷积流程:
1、原始图片batch(大小为b*h*w*c),记为U,经过一个普通卷积,卷积填充为same,即输出输入的h,w数值不变,对应的输出结果为offset层(b*h*w*2c),记为V,输出的结果是指原图片batch中每个像素的偏移量(x偏移与y偏移,因此为2c)。也就是说offset层是通过卷积网络计算得到的。
2、将U中图片的像素索引值与V相加减变换,得到偏移后的position(即在原始图片U中的坐标值),注意变换操作需要将最终的position值限定为图片大小以内。注意到position只是一个float类型的坐标值,我们需要这些float类型的坐标值获取像素。
3、比如取一个float类型的坐标值(a,b),将其转换为四个整数,floor(a), ceil(a), floor(b), ceil(b),将这四个整数进行整合,得到四对坐标(floor(a),floor(b)), ((floor(a),ceil(b)), ((ceil(a),floor(b)), ((ceil(a),ceil(b))。这四对坐标每个坐标都对应U中的一个像素值,而我们需要得到(a,b)的像素值,这里采用双线性差值的方式计算,一方面得到的像素准确,另一方面可以进行反向传播。
4、在得到position的所有像素后,即得到了一个新图片M,将这个新图片M作为输入数据输入到下一个卷积层中。
除此之外还有两篇讲解比较详细的文章
再思考可变形卷积
DCN V1代码阅读笔记