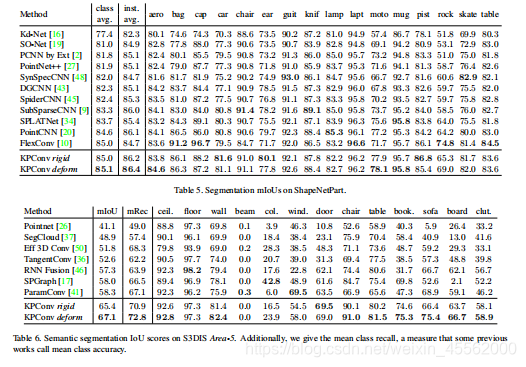
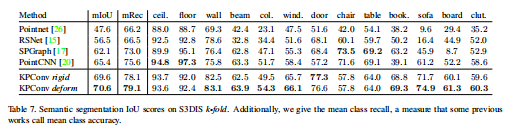
摘要
我们提出了核点卷积(KPConv),这是对于点云卷积的一种新的设计,这种设计不需要使用点云的任何其他中间表达形式,KPConv的卷积核的权重位于核点决定的欧式空间,并应用于靠近它们的输入点。其使用任意数量的kernel points的能力使KPConv比固定网格卷积更具灵活性,即这种卷积方式比固定化的网格卷积要更灵活(对于点云的分类和分割任务来说)。核点的位置在空间中是连续的并且可以被网络学习。因此,KPConv卷积可以扩展到卷积核可变的卷积,后者可以让核点适应局部几何区域。利用规则下采样,KPConv卷积对于点云密度的变化同样是有效和鲁棒的。无论是对于复杂任务应用卷积核可变的KPConv卷积,还是对于简单任务应用普通KPConv卷积,我们的网络在数个公开数据集上都胜过点云分类和分割的最先进水平。我们同样提供网络模型简化测试研究和可视化操作以便理解KPConv卷积学习到了什么并且可以验证可变卷积核的KPConv卷积的描述能力。
前言
这篇论文中,我们总是把点云考虑成两个因素:三维欧式空间中包含p个点的点集和高维空间中的f维特征。和规则的二维网格数据(如图像中的像素)不同:这样的点具有无规则和稀疏性特征。然而,三维点云和二维网格数据在卷积定义层面有一个共同点:都是定于在局部空间的。在二维网格数据中,特征位于矩阵中索引中,而点云特征存在于点的三维坐标中。因此,点被视为结构元素,特征被视为真实数据。
本论文引进了一个新的卷积操作:核点卷积(KPConv)。KPConv同样包含一组局部三维卷积核,但克服了之前卷积操作的局限。KPConv的想法来源于给予图像的卷积,但是不同于图像卷积核,我们用一组核点定义一个区域,把每一个卷积核的权重应用在这个区域中,如图1所示。

图释:应用与二维点上的KPConv卷积。 把KPConv应用于带有常量标量特征(灰度值)的输入点。KPConv卷积核被定义为一组核点(黑色小点),每一个点都有各自的权重。
我们还提出了一个卷积核可变的核点卷积版本,这包含应用于核点的局部平移(如图3所示),我们的网络在每一个卷积位置产生不同的位移,这意味着它可以针对输入点云的不同区域调整其核的形状。我们的卷积核可变卷积的设计与图像卷积的卷积核设计不同。由于数据的特性不同,它需要正则化以帮助卷积操作适应点云几何分布和避免空空间。我们使用有效感受野和网络模型简化测试去比较卷积核不变卷积和卷积核可变卷积。
相对于论文[41, 2, 45, 20],我们的局部区域的选择用的是半径邻域采样而不是K近邻算法。如论文[13]所述,KNN对于非均匀采样并不鲁棒。我们的卷积对于不同密度的点云具有鲁棒性,这得益于半径邻域采样和规则采样的结合。对比归一化策略,我们的方法同样减轻了算力。
在我们的实验部分,我们展示了KPConv可以被用于构建非常神的语义分割和分类架构,并且同时保持快速的训练和推理时间。整体上,卷积核不变和可变KPConv在多个数据集上表现的都很好。我们发现前者在简单任务上表现的更好,如物体分类,或者小的分割数据集。后者能胜任更复杂的任务,如在包含多种类别的对象上的大的语义分割数据集上的对象分类。我们同样展示了后者对数量少的核点更有鲁棒性,这显示了其更大的描述能力。最后,对KPConv定性研究表明卷积核形状的可变卷积改善了适应场景对象的多变的几何形状的能力。
相关工作
源自:https://zhuanlan.zhihu.com/p/94159004
这一部分,我们简要的回顾了之前应用于点云的深度学习方法,把重点放在在点云卷积的定义上与我们的工作类似的研究上。
Projection networks.很多方法把三维点投影到二维规则格网中。基于图像的深度学习网络通常是多视角的,对三维对象进行多视角拍照,进而利用二维图像卷积的方法进行处理[35, 4, 18]。对于场景语义分割,这些方法受到物体表面自遮挡和密度变化的影响。不采用全局的投影视角,论文[36]提出了把局部邻域点投影到局部切平面,然后用2维卷积处理它们。然而,这种方法比较依赖于切平面的估计。
至于点云语义处理中基于体素的方法,点投影到欧式空间的三维网格中[24, 30, 3]。使用稀疏结构如八叉树和哈希映射允许网络使用在大的格网中并具有增强的表现[29, 9],但是这些网络仍然缺乏灵活性,其卷积核被限制在27或者125个体素。使用多面体结构代替欧式空间格网结构把卷积核大小降低到15( lattices)[34],但是这个数字仍然被限制,而KPConv允许任意数量的核点数。再者,避免中间结构使得更复杂的架构设计如实例掩码检测器或生成模型更具前景。
Graph convolution networks 卷积算子定义在图上,有许多方式解决这个问题。图卷积可以作为其频谱表示的倍乘来计算[8, 48],或者其聚焦于用图表示其表面特征[23, 5, 33, 25]。尽管点云卷积和大多数近期研究的图卷积存在相似性[39, 43],后者主要学习点与点之间的关系而不是点的相对位置。换句话说,图卷积结合了局部区域特征,同时能抵抗欧式空间中的表面变形保。相应的,KPConv把局部特征结合到三维几何特征上,因此能捕捉表面的变形。
Pointwise MLP networks..Pointnet被认为是点云深度学习历史上的里程碑。此网络在每个单独的点上利用共享的多层感知机提取点的高维特征,然后使用全局池化提取所有点云的全局特征。由于没有考虑到点云的局部空间关系,网络的表现尤其局限性。在Pointnet之后,出现一些分层的网络结构使用多层感知机聚合局部邻域信息[27, 19, 21]。
如论文[41, 20, 13]所述,点云的卷积核可以使用一个MLP实施,因为它可以近似任何连续函数。然而,这个表示使得卷积操作变得复杂,并且网络收敛困难。在我们的工作中,如图像卷积一样,其权重可以直接被习得,我们定义了一个明确的卷积核,没有MLP的中间表示。我们的设计同样提供卷积核自适应的卷积版本,偏离可以直接被应用于核点。
Point convolution networks.一些最近的工作同样定义了显式的卷积核,但KPConv在独特的设计上脱颖而出。
PointCNN把卷积核的权重定位在体素中,因此缺乏灵活性。再者,他们的归一化策略加重了计算负担,而KPConv的降采样策略减轻了计算成本,更能适应点密度的变化。
SpiderCNN [45]定义了把卷积核定义成多项式函数,为每一个邻域应用不同的权重。应用于邻域的权重取决于邻域点和中心点之间的距离,这使得卷积核空间上保持不变。相反,KPConv的权重位于空间中并且其卷积结果和点云输入顺序无关。
Flex-convolution [10]使用线性函数对卷积核进行建模,这限制了其表达能力。同样,他们使用KNN算法,这使得计算方法对点云密度的变化不具有鲁棒性。
PCNN [2]的设计与我们的设计最为接近。他同样使用点去携带权重,并且使用了相关函数。但是,他的设计是尺度不变的因为他没使用任意形式的邻域,这使得卷积计算比较耗时。并且,他使用高斯相关而我们使用的是一个简单的线性相关,这在学习变形的时候[7]有利于梯度反向传播。
在实验部分,我们展示了KPConv网络的表现超过了对比的其他网络。此外,据我们所知,以前的工作都没有涉及到空间可变形的点卷积。
3. Kernel Point Convolution
3.1. A Kernel Function Defined by Points

图片来自https://blog.csdn.net/Dujing2019/article/details/104178936
正如之前的工作,收到图像卷积的启发,KPConv可以用点云卷积的一般定义去表达(如公式1所示)。为清晰起见,我们称 $xi $ 和 fi 是属于三维实数空间中的点集P∈RN*3,每一个点的特征F是实数空间中的D维特征,F∈RN*D,在三维点处x∈R3的卷积被定义为公式(1)。
我们使用论文[13]的球半径邻域法对点云进行降采样,以保证对点密度的变化更具有鲁棒性。因此: ,r∈R是选择的半径。再者,[38]展示了对于手工制作的三维点云特征使用半径邻域的方法比使用KNN算法效果更好。我们相信函数g拥有一致的球形邻域能够帮助网络学习到更有意义的特征
公式(1)的重点在于核函数g的定义,这就是KPConv奇异之处。g以位置x为中心的邻域点作为输入。我们下边称它为:yi=xi-x ,因为我们的邻域是定义在半径r内的,g的区域是球形区域。
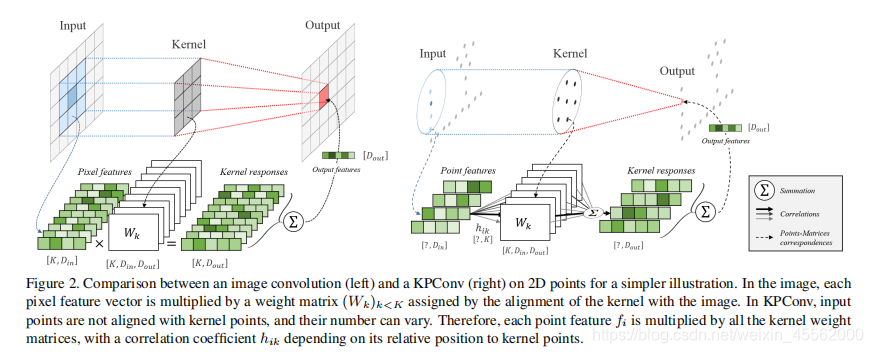
图2展示了图像卷积和KPConv卷积的对比。我们希望核函数g对于不同区域能学习到不同权重。有许多方法定义三维空间中的区域,点云是最符合直觉的,因为特征由点决定。
 代表核点,
代表核点,
 代表权阵,它们把特征向量的维度从Din映射到Dout
代表权阵,它们把特征向量的维度从Din映射到Dout
我们为任意点yi的定义核函数g:
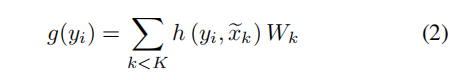
定义
:
σ是核点的影响范围,根据输入点的密度进行选择。相对高斯相关系数而言,本文所用相关系数是一种更为简洁的表示。当网络学习卷积核的变形形式的时候,我们提倡使用这个更为简洁的表示降低梯度方向传播的难度。可以使用整流线性单元(Relu),这是深层神经网络最常用的激活函数,归功于其梯度反向传播的效率。
3.2. Rigid or Deformable Kernel
核点的位置对于卷积算子来说非常重要。我们的不变卷积需要被安排以提高效率。由于KP-Con的优势之一是它的灵活性,我们需要为任一K值(核点数量的上限)寻找一个规则的(均匀的)处理。我们选择通过解决一个优化问题来放置核点,其中每个点在彼此之间施加排斥力。这些点被约束在一个球体中,并且其中之一被约束在中心。我们详细说明了这个处理过程并且在补充材料中展示了一些规则化处理 。最后,周围点被缩放到平均半径的1.5σ,以保证每一个核点区域之间的一个小的重叠和一个较好的空间覆盖。
对核点权值做适当的初始化,卷积核不变版本的KP-Conv表现的非常有效,特别是当给一个足够大K值以覆盖g的球形区域的时候。然而,通过学习核点的位置仍然有可能增加网络的性能。核函数g不同于核点
k ,这意味着他们都是可学习的参数。我们考虑为每一个卷积层设置一组全局参数{xk},但是相对于一个固定的规则化处理来说,这不会带来更强的描述能力。然而,网络为每一个卷积点x∈R3(如论文7所描述)生成一组k的偏移 △(x) ,并且卷积核可变卷积的定义如下:
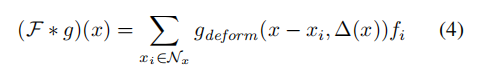
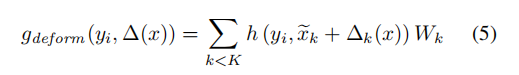
我们定义偏移量△k(x) 为KP-Conv卷积的输出,此输出把输入特征向量Din映射到3k值,如图3所示。在训练过程中,网络学习到核点产生的平移,同时变形核点产生输出特征,但是第一次迭代的学习率设置为全局学习率的1/10.
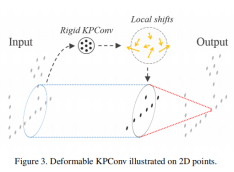
不幸的是,图像形变卷积并不适合点云。实际上,核点最终被拉离输入点。这些核点最后消失于网络,因为当他们的影响范围内没有邻域点的时候他们平移量△(x)的梯度是是空值。关于消失的核点的更多细节在补充材料中会有说明。为了处理这种结果,我们提出了一个fitting loss,它会惩罚核点和所有输入邻域中距离它最近的邻域点之间的距离。还有,当所有成对的核点的影响范围有相互覆盖的时候,我们同样在所有的成对的核点之间增加一个repulsive loss ,因此他们不会同时失效。整体上,在所有卷积位置x∈R3我们的正则化损失是:
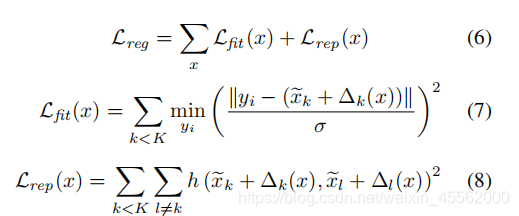
利用这个损失函数,网络会产生适合输入点云的局部集合形状的平移。*我们在补充材料中展示了这个效果。 *
3.3. Kernel Point Network Layers
这部分阐释一下我们怎样把KP-Conv理论有效的应用在实践上。进一步的细节我们已经发布了我们的代码。
Subsampling to deal with varying densities.如引言中所述,我们使用下采样策略在每一层控制输入点的密度。为了保证采样点位置的空间一致性,我们使用网格下采样。因此,选择每层支撑特征位置的支撑点作为所有非空网格单元中包含的原始输入点的重心。
Pooling layer . 为了使用mlp创建层状网络结构,我们需要逐步降低点的数量。由于我们已经有网格采样,和其他相关参数,这可以逐渐增加KPConv的感受野。在每一个新的位置上可以通过最大池化或者KPConv卷积提取小区域的局部特征向量。我们在网络结构中使用后者并且称之为"strided KP-Conv",类比图像中Strided Convolution(跨步卷积,即卷积时并不是简单的逐步卷积:而是跨步,比如跨两步,即如果上一步卷积了(0, 0)到(2, 2)这3x3的区域)
KPConv layer.. 卷积层将点P∈RN×3,其对应特征F∈RN×Din 和邻域索引矩阵n∈[1,N] N′×nmax作为输入。N` 是被计算邻域的位置数,可以与N(在“strided ” KPConv的情况下)不同。 邻域矩阵被迫具有最大邻域nmax的大小。 由于大多数邻域包含少于nmax 个邻域,因此矩阵包含未使用的元素。 我们称它们为shadow neighbors,在卷积计算中将其忽略。
Network parameters. 每个层 j 都有一个像元大小dlj ,据此我们可以推断其他参数数量。核点影响范围设置为σj=∑ × dlj,对于核点不变卷积KP-Conv来说,卷积半径被自动设置为2.5σj ,考虑到平均核点半径是1.5σj . 对于核点可变卷积来说,卷积半径可以被选择为rj=ρ× dlj , ∑和ρ是对于整个网络的比例系数。除非特别说明,通过交叉验证作者得到了:k=15,∑ =1.0,ρ=5.0,应用于所有实验。第一次下采样大小dlo将取决于数据集,并且,如前所述,dl j+1 =2∗dlj
3.4. Kernel Point Network Architectures
结合成功的图像处理网络架构和经验研究,我们为点云分类和语义分割任务设计了两个网络架构。补充材料

KP-CNN 是一个5层的分类卷积网络架构。每一层包含两个卷积模块,除了第一层外,第一个都是是strided。卷积块被设计为瓶颈ResNet 块 [12],用KPConv代替图像卷积,BN和弱化的ReLu激活函数。在最后一层之后,局部区域点云特征向量被一个全局平均池化聚合,并使用全连接和softmax()函数进行类别处理。对于可变卷积核的结果,我们只在最后5个KPConv卷积块使用可变卷积核(*网络结构的细节部分见补充材料 *第3层的第2个块,以及第4层和第5层的两个块)。
KP-FCNN 是一个为语义分割设计的全连接的卷积神经网络。编码部分和KP-CNN相同,解码部分使用了最邻近上采样以获得最终的逐点特征。使用跳跃连接传递编码和解码的中间层之间的特征。这些特征被并联到上采样部分并被一个一元卷积处理,这等价于图像处理中的1*1的卷积或者PointNet中共享的MLP。 可以用KPConv取代最近的上采样操作,其方式与strided KPConv相同,但不会导致性能的显著改善。
4. 实验



结论
在这篇论文中,我们提出了直接作用于点云的KPConv卷积。KPConv把邻域半径作为输入,用一小组核点在空间上定位的权重处理它们。我们定义了一个卷积核可变版本的KPConv,它可以学习核点的局部偏移,改变卷积核的形状以使得它们适应点云对象的几何形状。取决于数据集的多样性,或者网络的设置,rigid KPConv和deformable KPConv(卷积核不变和可变版本的KPConv)均是有价值的,并且我们的网络在几乎所有的被测试数据集上带来了最高水平的表现。我们发布了我们的源代码,希望可以帮助那些想在点云卷积架构的进行进一步的研究的人。除了本文所提出的分类和分割网络,KPConv可以用于CNNs处理的任何其他应用程序。我们相信卷积核可变版本的KPConv适用于更大型的数据集,能适应更具挑战性的任务,如目标检测,激光雷达流计算,或者point cloud completion。
补充
Abstract
This supplementary document is organized as follows:
• Sec. A details our network architectures, the training parameters, and compares the model sizes and speeds.
• Sec. B presents the kernel point initialization method.
• Sec. C describes how our regularization strategy tackles the “lost” kernel point phenomenon.
• Sec. D enumerates more segmentation results with class scores.
• KPConv Method video1 illustrates KPConv principle with animated diagrams, and shows some learned kernel deformations.
• KPConv Results video2 shows indoor and outdoor scenes segmented by KP-FCNN.
A. Network Architectures and Parameters

如在论文中所陈述的那样,我们的网络架构由卷积块组成,其设计像论文[12]中的ResNet模块。这是我们使用正常或者跨步卷积的KPConv的由来,使用卷积核不变和可变的版本的KPConv。图8描述了这些卷积块,图9我们的两个网络体系结构由它们(上述卷积)组成。在图9中,我们展示了一个来自于ModelNet40数据集中的点云例子,每一层都经过了下采样。它说明了卷积半径(红色球体)是如何与下采样的网格的大小成比例增长的。在我们使用deformable KPConv的所有实验中,我们在最后5个卷积模块使用deformable kernels(第三层的第二个模块,以及4层和5层的2个模块)。图9中层上面的绿色数字是块(图8中的D部分)中使用的特征维度。
我们的层处理可变大小的点云,我们不能将它们按新的“批处理”维度堆叠。因此,我们将我们的点和特征张量按它们的第一个维度(点的数量)进行叠加。因为邻域和池化索引不会从一个输入到另一输入传递,每一个批内的元素都被独立的处理,没使用有任何花招。我们仅仅需要追踪批内元素的索引以便定义KP-CNN的全局池化。由于点云数量变化比较大,我们通过选择尽可能多的元素直到某一特定数量的点云被选出,从而使用变化的批大小。选择这个限制以使得平均批大小和目标批大小相一致。论文[13]描述了一个相似的批选择策略。
KP-CNN 训练. 我们使用动量梯度下降优化器去最小化一个交叉熵损失函数,batch size设置为16,动量值设为0.98,初始学习率设置为0.001。学习率呈指数减小,我们选择指数衰减保证每100个epoch它除以10。 在最后一个全连接层中使用0.5的概率丢失。网络在200个epoch即收敛。使用可变卷积核的时候,正则化损失加上乘法因子为0.1的输出损失。
KP-FCNN训练. 我们同样使用动量梯度下降优化器最小化逐点的交叉熵损失,批大小设置为10,动量因子设置为0.98,初始学习率设置为0.01. 使用相同的学习率设置,不应用dropout. 在所有实验中,网络最多需要400个 epoch才能收敛。对于场景分割,我们可以生成输入球形邻域的任意个数,因此我们定义一个 epoch为500次优化,这相当于网络可以看到5000个邻域球。应用同样的可变形正则化损失。
(1)batchsize:批大小。即每次训练在训练集中取batchsize个样本训练;
(2)iteration:1个iteration等于使用batchsize个样本训练一次;
(3)epoch:1个epoch等于使用训练集中的全部样本训练一次,一般用多个epoch
Model sizes and speeds.网络架构前向传播的操作数量取决于当前批的点云数量和这些点的邻域的最大值。
B. Kernel Points Initialization
KPConv在一个球形区域内运行,并且需要规则分布于这个区域内的核点。在一个球形区域内明显的规则化处理,我们通过把它转变成一个最优化问题解决这个问题。问题是简单的,我们希望在一个给定的球形区域内,k个核点 xk 相互之间的距离尽可能的远。因此我们为每一个点赋上一个排斥势能。

并且我们对球形区域中心增加一个吸引势能,以避免它们无限期地发散。(也别太远)

此时问题最小化这个全局能量函数:(最后找个兼顾上述两者的式子)

解决方案是通过 随机初始化点梯度下降和一些可选约束。在我们的案例中,我们把其中一个核点固定在球形区域的中心。对于k值(列于表4),点收敛于一个唯一的稳定的排列。这些稳定的排列实际上构成了规则多面体。每个多面体可以通过将共点的平面与多面体对称轴垂直的点进行分组来描述。为了更好的理解,图10展示了一些排列。

在KP-CNN和KP-FCNN的每一层,点的位置从选择的稳定的排列到合适的半径被缩放,并被随机旋转。注意到当训练核点位置的时候,Etot在KP-CNN中可以被用于正则化损失
C. Effect of the Kernel Point Regularization
当我们设计可变形KPConv时,我们首先使用了图像可变形卷积的直接自适应,但网络的性能很差。 我们研究了网络收敛后的核变形,注意到核点往往被从输入点拉走。 这种现象来源于点云的稀疏性质,点周围有空隙。 我们提醒,位移是由网络预测的,因此,它们取决于输入形状。
对于训练过程中的特定输入,如果一个核点偏离输入点,那么它的偏移∆k(X)的梯度是空的。 因此,它被网络“丢失”,并且对于相似的输入形状不会出现。 由于网络优化器的随机性,在收敛过程中,许多输入形状都会发生这种情况。

图11显示了房间地板示例上的“丢失”内核点。 首先,我们看到了红色的rigid kernel,它的尺度给出了核点影响范围的概念。 在中间,紫色 点描述了一个由网络预测的deformed kernel,没有任何正则化损失。 大多数紫色点远离地板平面,因此“丢失”。
我们的正则化策略,在主文中描述,防止了这种现象,如图11的底部所示。 我们可以注意到,我们的正规化战略不仅防止了“损失”“kernel points。 它还有助于最大限度地增加KPConv(那些输入点在范围内)中的活动核点的数量。 几乎每个黄色点都接近地板平面。
D. More Segmentation Results