采用了一个work group的所有线程来计算最内部维度的reduce计算,work group通常采用4x warp_size。
计算一个warp/sub group内部的累加采用了sub_group_reduce_add,类似于CUDA的warp shuffle,理论上有助于提升性能。
opencl kernel和测试代码如下,ARM mali GPU性能显著优于tflite GPU delegate实现。没有直接采用atomic对不同warp之间的结果进行累加,因为opencl的atomic不支持float,而采用了另一种方式。
这里采用了一个thread block的方法来reduce每一行,同样,在行长度不大时,可以采用一个warp来reduce每一行,代码更加简单,无需warp之间的reduce.
#include <iostream>
#include <memory>
#include <string>
#include <vector>
#include <chrono>
#include "mem_helper.h"
#define CL_HPP_TARGET_OPENCL_VERSION 300
#include <CL/opencl.hpp>
using TEST_DTYPE = float;
using namespace std;
std::string kernel_source{R"(
// we use all threads in a block to calculate the reduce mean/sum of the last tensor axis
kernel void reduce_kernel(__global const float* d_in, __global float* d_out, int channel_size, int block_size) {
int gid = get_global_id(0);
int lid = get_local_id(0);
int batch = get_group_id(0);
int warp_id = get_sub_group_id();
int lane_id = get_sub_group_local_id(); // id of threads in a warp
int sg_num = get_num_sub_groups();
// for warp_num = 8, block_size should < 8 * 8 = 64
// for warp_num = 16, block_size should < 16 * 16 = 256
int addr_offset = batch * channel_size;
float mean = 0.0f;
for (int i = lid; i < channel_size; i += block_size) {
float x0 = d_in[addr_offset + i];
mean += x0;
}
// all values in a warp are reduced together
mean = sub_group_reduce_add(mean);
// we use local mem to exchange the data between warps
// we write first value of each warp into local mem, and then read by threads in one warp for reduce
// should not > threads in a warp (typically 8 or 16),
// and should not < work_group size / threads in a warp
#define MAX_WARP_NUM 16
local float shared_sums[MAX_WARP_NUM];
if (lane_id == 0) {
// atomic_store(&shared_sums[warp_id], mean);
shared_sums[warp_id] = mean;
}
barrier(CLK_LOCAL_MEM_FENCE);
// mean = (lid < sg_num) ? shared_sums[lid] : 0; // only first warp get mean
mean = (lane_id < sg_num) ? shared_sums[lane_id] : 0; // each warp get mean
mean = sub_group_reduce_add(mean);
mean /= channel_size;
if (lid == 0) {
d_out[batch] = mean;
}
}
)"};
int main() {
std::vector<cl::Platform> platforms;
cl::Platform::get(&platforms);
std::cout << "get platform num:" << platforms.size() << std::endl;
cl::Platform plat;
for (auto& p : platforms) {
std::string platver = p.getInfo<CL_PLATFORM_VERSION>();
if (platver.find("OpenCL 2.") != std::string::npos || platver.find("OpenCL 3.") != std::string::npos) {
// Note: an OpenCL 3.x platform may not support all required features!
plat = p;
}
}
if (plat() == 0) {
std::cout << "No OpenCL 2.0 or newer platform found.\n";
return -1;
}
std::cout << "platform name:" << plat.getInfo<CL_PLATFORM_NAME>() << std::endl;
cl::Platform newP = cl::Platform::setDefault(plat);
if (newP != plat) {
std::cout << "Error setting default platform.\n";
return -1;
}
// get default device (CPUs, GPUs) of the default platform
std::vector<cl::Device> all_devices;
newP.getDevices(CL_DEVICE_TYPE_GPU, &all_devices); // CL_DEVICE_TYPE_ALL
std::cout << "get all_devices num:" << all_devices.size() << std::endl;
if (all_devices.size() == 0) {
std::cout << " No devices found. Check OpenCL installation!\n";
exit(1);
}
// cl::Device default_device = cl::Device::getDefault();
cl::Device default_device = all_devices[0];
std::cout << "device name: " << default_device.getInfo<CL_DEVICE_NAME>() << std::endl;
// a context is like a "runtime link" to the device and platform;
// i.e. communication is possible
cl::Context context({default_device});
cl::CommandQueue queue(context, default_device);
int batch = 512;
int channel_size = 768;
vector<int> shape1 = {batch, channel_size};
vector<int> shape2 = {batch,};
MemoryHelper<TEST_DTYPE> mem_in(shape1);
MemoryHelper<TEST_DTYPE> mem_out(shape2);
mem_in.StepInit();
// CL_MEM_WRITE_ONLY CL_MEM_READ_ONLY CL_MEM_READ_WRITE
cl::Buffer d_in = cl::Buffer(context, CL_MEM_READ_WRITE, mem_in.bytes);
cl::Buffer d_out = cl::Buffer(context, CL_MEM_READ_WRITE, mem_out.bytes);
memset(mem_out.Mem(), 0, mem_out.bytes);
// push write commands to queue
queue.enqueueWriteBuffer(d_in, CL_TRUE, 0, mem_in.bytes, mem_in.Mem());
std::vector<std::string> programStrings;
programStrings.push_back(kernel_source);
cl::Program program(context, programStrings);
if (program.build({default_device}, "-cl-std=CL3.0") != CL_SUCCESS) {
std::cout << "Error building: " << program.getBuildInfo<CL_PROGRAM_BUILD_LOG>(default_device) << std::endl;
exit(1);
}
auto cl_kernel = cl::KernelFunctor<cl::Buffer, cl::Buffer, int, int>(program, "reduce_kernel");
int block_size = 64;
if(block_size > channel_size){
block_size = channel_size;
block_size = (block_size / 8) * 8;
}
int local_thread_num = block_size;
int total_thread_num = batch * local_thread_num;
// global, or global, local, or offset, global, local
cl::EnqueueArgs kernel_args(queue, cl::NDRange(total_thread_num), cl::NDRange(local_thread_num));
cl_kernel(kernel_args, d_in, d_out, channel_size, block_size);
queue.enqueueReadBuffer(d_out, CL_TRUE, 0, mem_out.bytes, mem_out.Mem());
std::cout << "results:" << std::endl;
TEST_DTYPE* h_c = mem_out.Mem();
for (int i = 0; i < mem_out.elem_num; i++) {
std::cout << float(h_c[i]) << " ";
}
std::cout << std::endl;
return 0;
}
mem_helper:
#include <iostream>
#include <vector>
#include <string>
#include <memory>
using namespace std;
template <class T>
class MemoryHelper {
public:
const vector<int> shape;
const size_t elem_num = 0;
const string name;
const size_t bytes = 0;
std::unique_ptr<T[]> h_mem = nullptr;
public:
MemoryHelper(const vector<int>& shape, const string& name = ""): shape(shape),
name(name),
elem_num(GetElemNum(shape)),
bytes(elem_num * sizeof(T)) {
h_mem = std::make_unique<T[]>(elem_num);
}
void RandInit(int seed=0){
srand(seed);
for (size_t i = 0; i < elem_num; i++) {
h_mem[i] = T(rand() % 100);
}
}
void StepInit(float ratio=0.01f, float bias=0.0f){
for(size_t i=0;i<elem_num;i++){
h_mem[i] = i*ratio+bias;
}
}
T* Mem() {
return h_mem.get();
}
size_t GetBytes() {
return bytes;
}
public:
static int GetElemNum(const vector<int>& shape) {
size_t elem_num = 1;
for (auto elem : shape) {
elem_num *= elem;
}
return elem_num;
}
};附加信息
mali gpu sub_group大小,对应于CUDA warp的大小,也可以通过相关函数获取:
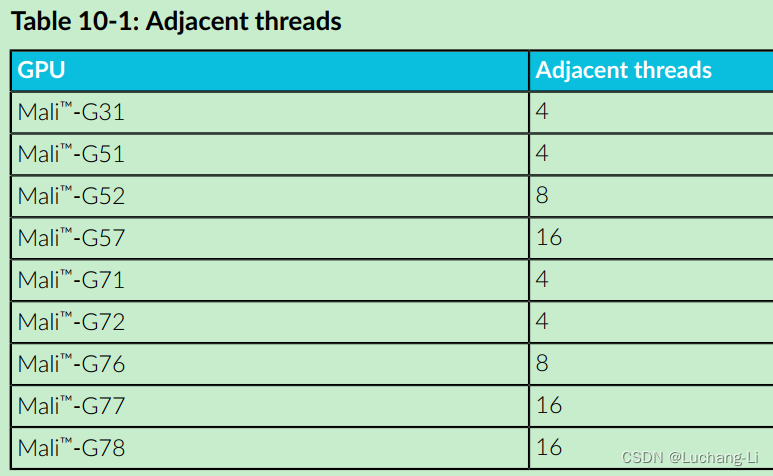
G.2.2 OpenCL 2.1 built-in functions
Several new built-in functions are added in OpenCL 2.1.
The new functions are:
• get_enqueued_num_sub_groups
• get_kernel_max_sub_group_size_for_ndrange
• get_kernel_sub_group_count_for_ndrange
• get_max_sub_group_size
• get_num_sub_groups
• get_sub_group_size
• get_sub_group_local_id
• get_sub_group_id
• sub_group_all
• sub_group_any
• sub_group_barrier
• sub_group_broadcast
• sub_group_commit_read_pipe
• sub_group_commit_write_pipe
• sub_group_reduce_<op>
• sub_group_reserve_read_pipe
• sub_group_reserve_write_pipe
• sub_group_scan_exclusive_<op>
• sub_group_scan_inclusive_<op>
The <op> in sub_group_reduce_<op>, sub_group_scan_inclusive_<op> and sub_group_scan_exclusive_<op> defines the operator and can be add, min or max.
For the sub_group_reduce, sub_group_scan_exclusive, and sub_group_scan_inclusive functions, gentype is int, uint, long, ulong, or float.
If cl_khr_fp16 is supported, gentype also includes half.
If cl_khr_fp64 or doubles are supported, gentype also includes double.
warp shuffle其他相关方法
// These functions are available to devices supporting cl_khr_subgroup_extended_types:
// Note: Existing functions supporting additional data types.
gentype sub_group_broadcast( gentype value, uint index )
gentype sub_group_reduce_add( gentype value )
gentype sub_group_reduce_min( gentype value )
gentype sub_group_reduce_max( gentype value )
gentype sub_group_scan_inclusive_add( gentype value )
gentype sub_group_scan_inclusive_min( gentype value )
gentype sub_group_scan_inclusive_max( gentype value )
gentype sub_group_scan_exclusive_add( gentype value )
gentype sub_group_scan_exclusive_min( gentype value )
gentype sub_group_scan_exclusive_max( gentype value )
// These functions are available to devices supporting cl_khr_subgroup_shuffle:
gentype sub_group_shuffle( gentype value, uint index )
gentype sub_group_shuffle_xor( gentype value, uint mask )
// These functions are available to devices supporting cl_khr_subgroup_shuffle_relative:
gentype sub_group_shuffle_up( gentype value, uint delta )
gentype sub_group_shuffle_down( gentype value, uint delta )
非常遗憾,目前除了Intel的扩展,opencl基本上不支持CUDA的__shfl_down_sync,__shfl_sync功能从而实现warp线程之间寄存器数据直接相互交换。
ref
The OpenCL™ Extension Specification
Arm® Mali™ Bifrost and Valhall OpenCL Developer Guide
atomic操作可以参考《OpenCl异构并行计算 原理 机制与优化实践》