本文为原创帖子,主要参考官网On-Device Training with TensorFlow Lite、Fasion Minist 个性化训练代码以及Muirush的代码,如需转载务必放上此链接,违者必究!!
本贴一定是热帖!!
on device training英文官网
https://www.tensorflow.org/lite/examples/on_device_training/overview
on device training中文官网
https://www.tensorflow.org/lite/examples/on_device_training/overview?hl=zh-cn
目前基于tflite端侧增量训练案例较少,目前只有官网中的服饰识别案例,官网参照:
https://www.tensorflow.org/lite/examples/on_device_training/overview?hl=zh-cn
谷歌官网on device training例子--Fasion Mnist 安卓端训练及推理
examples/lite/examples/model_personalization at master · tensorflow/examples · GitHub

Muirush线性回归预测代码
GitHub - Muirush/Model-training-with-Tensorflow-tfLite-and-android
但主要问题点是:该代码为图像分类训练推理的例子,耦合了较多复杂的代码,不利用把握tflite推理核心的代码有哪些,而且定义签名的脚本没有看到,因此对初学者而言有较大难度,没有讲清楚如何从头开始到端侧训练推理的全流程。

因此本文将从云端训练开始,利用DNN实现y=2*x – 1的回归预测,模型转化为tflite模型,利用最新的签名函数实现端侧的增量训练及推理。
软件版本:tensorflow 2.8(端侧推理是2.7以后有的功能)
Android Studio:4.2.1
第一步:云端训练,编写签名函数
注意,此处与以往云端训练不同的是编写签名函数,可以在模型转化为tflite时进行推理和训练使用,代码如下:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow import initializers as init
from tensorflow import losses
from tensorflow.keras import optimizers
from tensorflow import data as tfdata
from tensorflow import losses
from tensorflow.keras import optimizers
import numpy as np
class Model(tf.Module):
def __init__(self):
# 定义2层全连接网络,输入维度input_dim是1,第一隐层是10个神经元,第二层也是10个神经元,输出层是1个
self.model = tf.keras.Sequential()
self.model.add(tf.keras.layers.Dense(units=10, input_dim=1))
self.model.add(tf.keras.layers.Dense(units=10, ))
self.model.add(tf.keras.layers.Dense(units=1))
self.model.compile(loss=tf.keras.losses.MSE,
optimizer=tf.keras.optimizers.SGD(learning_rate=1e-5))
# 此处是非常重要的定义签名函数,尤其注意输入输出维度,且输入转化为tensor
@tf.function(input_signature=[
tf.TensorSpec([1, 1], tf.float32),
tf.TensorSpec([1], tf.float32),
])
# 此处特别注意,x y尽管是形参,输入变量,但是后期在安卓中训练时必须保持一致,否则会报错
# 训练代码
def train(self, x, y):
with tf.GradientTape() as tape:
prediction = self.model(x)
loss = self.model.loss(y, prediction)
gradients = tape.gradient(loss, self.model.trainable_variables)
self.model.optimizer.apply_gradients(
zip(gradients, self.model.trainable_variables))
result = {"loss": loss}
return result
# 推理代码
@tf.function(input_signature=[
tf.TensorSpec([1], tf.float32),
])
def infer(self, x):
pred =self.model(x)
return {
"output": pred
}
# 保存在安卓端训练后的新权重
@tf.function(input_signature=[tf.TensorSpec(shape=[], dtype=tf.string)])
def save(self, checkpoint_path):
tensor_names = [weight.name for weight in self.model.weights]
tensors_to_save = [weight.read_value() for weight in self.model.weights]
tf.raw_ops.Save(
filename=checkpoint_path, tensor_names=tensor_names,
data=tensors_to_save, name='save')
return {
"checkpoint_path": checkpoint_path
}
# 加载在安卓端训练后的新权重,用于新数据做推理
@tf.function(input_signature=[tf.TensorSpec(shape=[], dtype=tf.string)])
def restore(self, checkpoint_path):
restored_tensors = {}
for var in self.model.weights:
restored = tf.raw_ops.Restore(
file_pattern=checkpoint_path, tensor_name=var.name, dt=var.dtype,
name='restore')
var.assign(restored)
restored_tensors[var.name] = restored
return restored_tensors
NUM_EPOCHS = 10000
BATCH_SIZE = 1
epochs = np.arange(1, NUM_EPOCHS + 1, 1)
losses = np.zeros([NUM_EPOCHS])
m = Model()
# 输入数据构造
x1 = np.array([[-1.0],[0.0],[1.0],[2.0],[3.0],[4.0], [5.0],[6.0],[7.0],[8.0],[9.0]], dtype = float)
y1 = np.array([-3.0,-1.0,1.0,3.0,5.0,7.0,9.0,11.0,13.0,15.0,17.0], dtype = float)
# array转化为tensor
features = tf.convert_to_tensor(x1, dtype=float)
labels = tf.convert_to_tensor(y1, dtype=float)
# 构造batch
train_ds = tf.data.Dataset.from_tensor_slices((features, labels))
train_ds = train_ds.batch(BATCH_SIZE)
# 训练
for i in range(NUM_EPOCHS):
for x, y in train_ds:
result = m.train(x, y)
losses[i] = result['loss']
if (i + 1) % 100 == 0:
print('epochs=', i + 1, 'loss=', losses[i])训练结果如下展示:
epochs= 100 loss= 0.21976947784423828
epochs= 200 loss= 0.1585017591714859
epochs= 300 loss= 0.1464373618364334
epochs= 400 loss= 0.13536646962165833
epochs= 500 loss= 0.12510548532009125
epochs= 600 loss= 0.11560399830341339
epochs= 700 loss= 0.10680033266544342
epochs= 800 loss= 0.0986374095082283
……
epochs= 9500 loss= 4.569278098642826e-05
epochs= 9600 loss= 4.153713598498143e-05
epochs= 9700 loss= 3.7766891182400286e-05
epochs= 9800 loss= 3.464591281954199e-05
epochs= 9900 loss= 3.1359726563096046e-05
epochs= 10000 loss= 2.897171361837536e-05第二步、模型保存及转化为tflite模型
# 模型保存,注意,此处是保存签名函数的关键代码,否则在后续生成的代码中
SAVED_MODEL_DIR = "saved_model"
tf.saved_model.save(
m,
SAVED_MODEL_DIR,
signatures={
'train':
m.train.get_concrete_function(),
'infer':
m.infer.get_concrete_function(),
'save':
m.save.get_concrete_function(),
'restore':
m.restore.get_concrete_function(),
})
# Convert the model
# 保存模型
converter = tf.lite.TFLiteConverter.from_saved_model(SAVED_MODEL_DIR)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TensorFlow Lite ops.
tf.lite.OpsSet.SELECT_TF_OPS # enable TensorFlow ops.
]
converter.experimental_enable_resource_variables = True
# 将云端模型转化为tflite模型,只有转化为tflite,安卓端才可以进行推理
tflite_model = converter.convert()
open('linear_model_0921.tflite', 'wb').write(tflite_model)输出为:
INFO:tensorflow:Assets written to: saved_model/assets
21168第三步、查看签名函数是否构建成功及输入输出
这步是后期安卓关键,
# 查看签名函数
# Print the signatures from the converted model
interpreter = tf.lite.Interpreter('linear_model_0921.tflite')
signatures = interpreter.get_signature_list()
print(signatures)输出为:
{'infer': {'inputs': ['x'], 'outputs': ['output']}, 'restore': {'inputs':
['checkpoint_path'], 'outputs': ['dense_6/bias:0', 'dense_6/kernel:0', 'dense_7/bias:0',
'dense_7/kernel:0', 'dense_8/bias:0', 'dense_8/kernel:0']}, 'save': {'inputs':
['checkpoint_path'], 'outputs': ['checkpoint_path']}, 'train': {'inputs': ['x', 'y'],
'outputs': ['loss']}}
第四步、利用python对tflite进行推理(云端的操作)
此步的作用是,验证转化后的tflite模型精度有没有下降
interpreter = tf.lite.Interpreter('linear_model_0921.tflite')
interpreter.allocate_tensors()
infer = interpreter.get_signature_runner("infer")
x6 = np.array([13.0], dtype = float)
x7 = tf.convert_to_tensor(x6, dtype=float)
infer(x=x7)['output'][0]输出为:
array([24.985922], dtype=float32)务必注意上面的是在云端调用tflite模型的推理结果!!
//下面这一步是云端模型的推理,以m.打头,这个要注意体会差别,即tensorflow saved model
result = m.infer(x=x7)['output']
np.array(result)[0]输出为:
array([24.98592], dtype=float32)可以看出两者结果相同,表明模型从云端大模型saved model格式,转化为tflite后精度未下降。
第五步、利用tflite,在云端进行训练,此处是表明tflite模型后利用python的接口仍然可以接着上一步云端训练结果接着训练,这步成功表明,在安卓端利用java的接口也是可以训练的
train = interpreter.get_signature_runner("train")
# NUM_EPOCHS = 50
# BATCH_SIZE = 100
more_epochs = np.arange(41, 501, 1)
more_losses = np.zeros([400])
BATCH_SIZE1 = 1
for i in range(400):
for x, y in train_ds:
result = train(x=x, y=y)
more_losses[i] = result['loss']
if (i + 1) % 2 == 0:
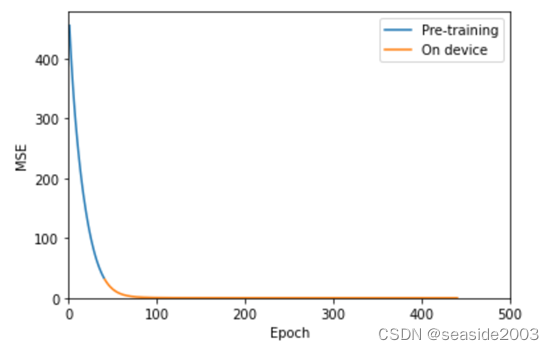
print('epochs=', i + 1, 'more_losses=', more_losses[i])感觉此处比较晦涩,用一张图说明,此处是在云端利用tensorflow大模型,训练了40个epoch(蓝色部分),在云端利用tflite模型运行400个epoch的结果(橘黄色),从曲线可以看出,tflite是在云端基础上进行训练,恰恰说明了迁移学习的特色。
**************************************************************************************************************
此处以下为安卓端代码
第六步、安卓边缘端训练和推理
本例安卓界面是利用 Muirush的代码,代码如下,这个代码只能用于安卓端推理,是不能用于安卓端训练的,因此里面用Model Training 1.py的代码生成的tflite模型,只能用interpreter.run(input,output)方法,进行推理,训练不行的,必须按照上面的代码,生成新的tflite代码,这样interpreter就可以用最新的方法:runSignature
边缘端推理:interpreter.runSignature(inputs, outputs, "infer");
边缘端训练:interpreter.runSignature(inputs, outputs, "train")

GitHub - Muirush/Model-training-with-Tensorflow-tfLite-and-android
利用Android Studio打开本工程:
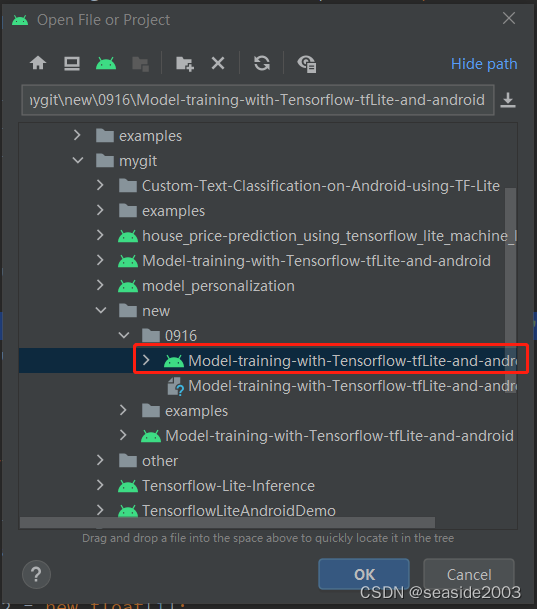
主要修改两个部分:
将文中最开始生成的tflite文件,放入assets文件夹下;
修改MainActivity.java,代码如下:
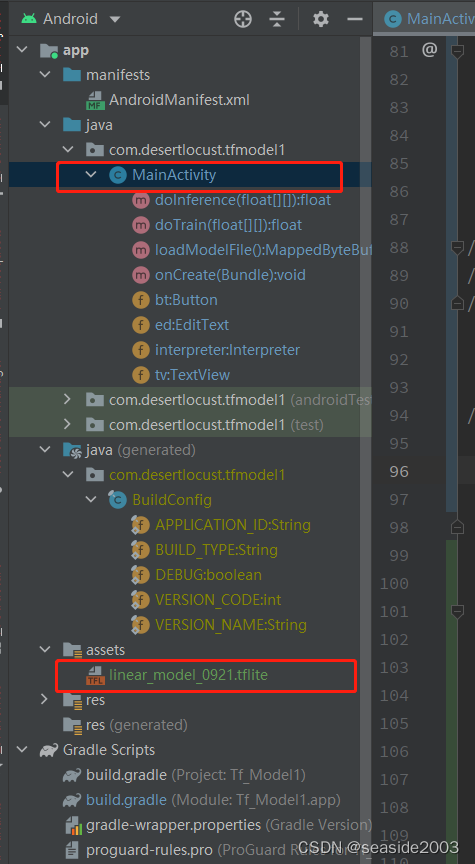
注释掉原来的推理:
// public float doInference(String val){
// float [] input = new float[1];
// input [0] = Float.parseFloat(val);
//
// float [][] output = new float[1][1];
// interpreter.run(input,output);
// return output[0][0];
// }添加新的推理和训练方法
// infer 采用最新的runsignature方法,签名
float doInference(float val[][]) {
// Run the inference.
FloatBuffer testImages = FloatBuffer.wrap(val[0]);
float[] output = new float[1];
FloatBuffer output2 = FloatBuffer.wrap(output);
Map<String, Object> inputs = new HashMap<>();
inputs.put("x", testImages.rewind());
Map<String, Object> outputs = new HashMap<>();
outputs.put("output", output2);
interpreter.runSignature(inputs, outputs, "infer");
return output[0];
}
float doTrain(float val[][]) {
// Run the training.
float[][] var = new float[1][1];
var[0][0] = 3.5f;
float[] var2 = new float[1];
var2[0] = 6.0f;
FloatBuffer testImages = FloatBuffer.wrap(var[0]);
float[] loss1 = new float[1];
FloatBuffer label2 = FloatBuffer.wrap(var2);
FloatBuffer loss2 = FloatBuffer.wrap(loss1);
Map<String, Object> inputs = new HashMap<>();
inputs.put("x", testImages.rewind());
inputs.put("y", label2.rewind());
Map<String, Object> outputs = new HashMap<>();
outputs.put("loss", loss2);
interpreter.runSignature(inputs, outputs, "train");
return loss1[0];
}修改onclick方法:
public void onClick(View v) {
// float f = doInference(ed.getText().toString());
String var = ed.getText().toString();
float [][] var2 = new float[1][1];
var2[0][0] = Float.parseFloat(var);
// 推理
// float f = doInference(var2);
// tv.setText(("Value of Y: "+ f));
// 训练
float loss6 = doTrain(var2);
tv.setText(("Loss is: "+ loss6));
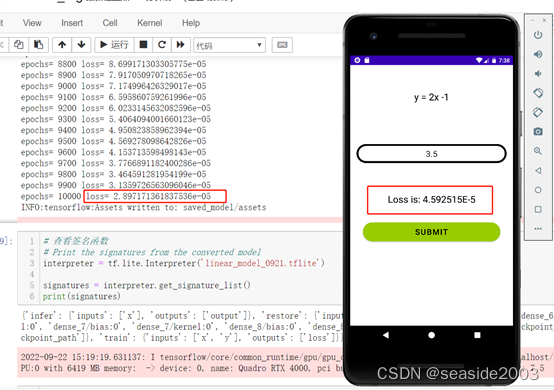
}执行训练时,点击Run app:

即可出现手机的模拟运行界面,注意有几个点做说明,云端的模型训练了10000个epoch,在安卓边缘端训练时,损失为4.5*1E-5,表明是在云端训练基础上接着训练,损失是接着下降的,训练此处我只写了一个值,只是为了方便,此处多些几个,写成epoch是一样的,没有本质区别:
执行推理时,安卓模拟器界面显示如下,表明云端推理结果、云端tflite推理结果、安卓端tflite推理结果,三者保持一致,至此已成功:

附录:修改后的MainActivity.java的完整代码如下:
package com.desertlocust.tfmodel1;
import androidx.appcompat.app.AppCompatActivity;
import android.content.res.AssetFileDescriptor;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.widget.EditText;
import android.widget.TextView;
import org.tensorflow.lite.Interpreter;
import java.io.FileInputStream;
import java.io.IOException;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.util.HashMap;
import java.util.Map;
import java.nio.FloatBuffer;
public class MainActivity extends AppCompatActivity {
private EditText ed;
private TextView tv;
private Button bt;
private Interpreter interpreter;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ed = findViewById(R.id.input);
tv = findViewById(R.id.output);
bt = findViewById(R.id.submit);
try {
interpreter = new Interpreter(loadModelFile(),null);
}catch (IOException e){
e.printStackTrace();
}
bt.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
// float f = doInference(ed.getText().toString());
String var = ed.getText().toString();
float [][] var2 = new float[1][1];
var2[0][0] = Float.parseFloat(var);
// 推理
// float f = doInference(var2);
// tv.setText(("Value of Y: "+ f));
// 训练
float loss6 = doTrain(var2);
tv.setText(("Loss is: "+ loss6));
}
});
}
// 加载tflite模型
private MappedByteBuffer loadModelFile() throws IOException{
AssetFileDescriptor assetFileDescriptor = this.getAssets().openFd("linear_model_0921.tflite");
FileInputStream fileInputStream = new FileInputStream(assetFileDescriptor.getFileDescriptor());
FileChannel fileChannel = fileInputStream.getChannel();
long startOffset = assetFileDescriptor.getStartOffset();
long length = assetFileDescriptor.getLength();
return fileChannel.map(FileChannel.MapMode.READ_ONLY,startOffset,length);
}
// infer 采用run方法
// public float doInference(String val){
// float [] input = new float[1];
// input [0] = Float.parseFloat(val);
//
// float [][] output = new float[1][1];
// interpreter.run(input,output);
// return output[0][0];
// }
// infer 采用最新的runsignature方法,签名
float doInference(float val[][]) {
// Run the inference.
FloatBuffer testImages = FloatBuffer.wrap(val[0]);
float[] output = new float[1];
FloatBuffer output2 = FloatBuffer.wrap(output);
Map<String, Object> inputs = new HashMap<>();
inputs.put("x", testImages.rewind());
Map<String, Object> outputs = new HashMap<>();
outputs.put("output", output2);
interpreter.runSignature(inputs, outputs, "infer");
return output[0];
}
float doTrain(float val[][]) {
// Run the training.
float[][] var = new float[1][1];
var[0][0] = 3.5f;
float[] var2 = new float[1];
var2[0] = 6.0f;
FloatBuffer testImages = FloatBuffer.wrap(var[0]);
float[] loss1 = new float[1];
FloatBuffer label2 = FloatBuffer.wrap(var2);
FloatBuffer loss2 = FloatBuffer.wrap(loss1);
Map<String, Object> inputs = new HashMap<>();
inputs.put("x", testImages.rewind());
inputs.put("y", label2.rewind());
Map<String, Object> outputs = new HashMap<>();
outputs.put("loss", loss2);
interpreter.runSignature(inputs, outputs, "train");
return loss1[0];
}
}最后说明,如果对利用Android Studio创建安卓手机模拟器并且运行脚本的,参见我上篇文章,或者看网上其他资料,都是比较详细的。
如果你按照操作,看到此处,表明你已经会用tflite进行安卓边缘端增量训练和推理,可以按照此步骤完成你自己的复杂的任务。
写在最后,谈谈我的想法,目前网上大量代码均是以tflite边缘端推理为主,而且是以老的run方法为例的,网上给出的案例耦合了图像的好多代码,不易理解,通过本例让你快速get到tflite的精髓,最后便于交流,特创建tlfite的群,欢迎加入,让我们一起交流进步,谢谢。
