端侧AI推理主要使用NPU完成,为了在性能,功耗和面积和通用性之间取得平衡,主流NPU采用了加速器架构,将算子固化在硬件中,并辅以可编程单元执行一些自定义算子/长尾算子兼顾灵活性。在计算方面,为了提高存储使用效率和加速计算,在满足计算精度的前提下,NPU普遍采用定点计算单元实现核心算子,以较低的带宽需求和较快的计算速度达到推理精度的要求,这样就需要在数据的预处理阶段和后处理阶段分别对数据做量化和反量化操作,以满足NPU计算单元对定点数据计算的需要,NPU的工作模型如下图所示:

而GPU则不同,GPU的计算单元天然支持浮点计算,不需要执行量化和反量化的操作,模型推理更直接,以我的显卡为例,从下图可以看出,它的浮点算力远远高于定点算力:

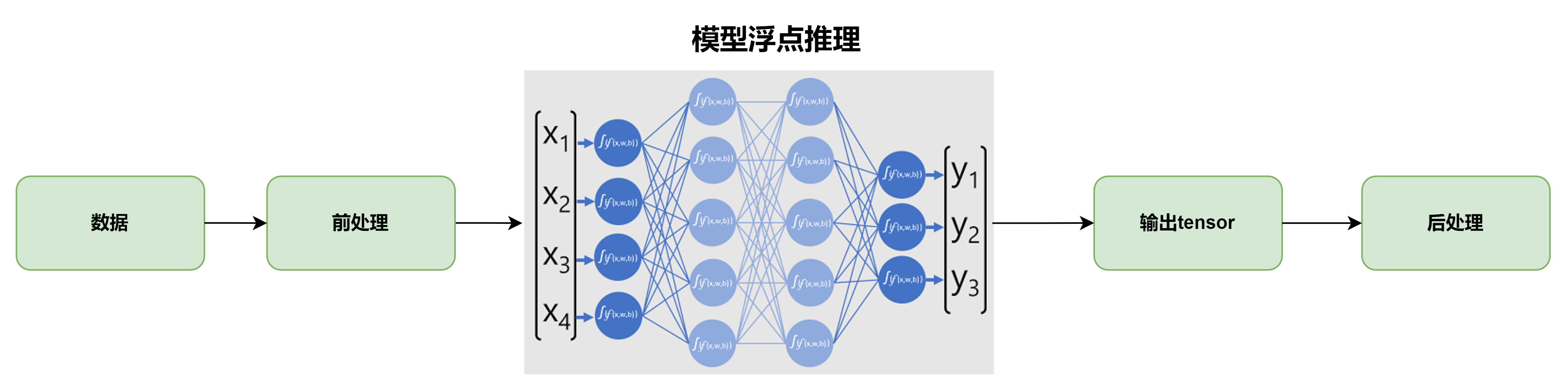
使用GPU对模型推理,不需要量化和反量化操作:
推理过程对量化的不同要求,可能会产生一个有意思的结果,就是推理的模型精度表现可能会有所不同,这里所说的精度表