目录
1.需求
订单表

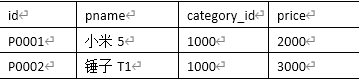
商品表
实现机制:
通过将关联的条件作为map输出的key,将两表满足join条件的数据并携带数据所来源的文件信息,发往同一个reduce task,在reduce中进行数据的串联
2.创建join对象
package com.czxy.order;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
@Data
@NoArgsConstructor
public class JoinBean implements Writable {
private String id; // 订单id
private String date; // 订单时间
private String pid; // 商品id
private String amount; // 数量
private String name; //订单名称
private String categoryId; //类别id
private String price; // 价格
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(id+"");
out.writeUTF(date+"");
out.writeUTF(pid+"");
out.writeUTF(amount+"");
out.writeUTF(name+"");
out.writeUTF(categoryId+"");
out.writeUTF(price+"");
}
@Override
public void readFields(DataInput in) throws IOException {
this.id = in.readUTF();
this.date = in.readUTF();
this.pid = in.readUTF();
this.amount = in.readUTF();
this.name = in.readUTF();
this.categoryId = in.readUTF();
this.price = in.readUTF();
}
}
3.实现Map Join
注意:需要把商品表的数据上传的HDFS
3.1创建map代码
package com.czxy.order;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import javax.xml.transform.Source;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
public class MapJoinMapper extends Mapper<LongWritable, Text, Text, Text> {
private Map<String, JoinBean> joinMap = new HashMap<>();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 获取所有的缓存文件地址
URI[] urls = DistributedCache.getCacheFiles(context.getConfiguration());
// 获取文件系统对象
FileSystem fs = FileSystem.get(urls[0], context.getConfiguration());
// 读取文件
FSDataInputStream open = fs.open(new Path(urls[0]));
// 转换为高效流
BufferedReader bf = new BufferedReader(new InputStreamReader(open));
// 按行读取
String line = "";
while ((line = bf.readLine()) != null) {
// 创建对象
JoinBean joinBean = new JoinBean();
// 按行切割
String[] split = line.split(",");
// 给对象赋值
joinBean.setPid(split[0]);
joinBean.setName(split[1]);
joinBean.setCategoryId(split[2]);
joinBean.setPrice(split[3]);
//给结合添加信息
joinMap.put(joinBean.getPid(), joinBean);
}
// 关闭资源
bf.close();
open.close();
fs.close();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 类型转换
String s = value.toString();
// 字符串切割
String[] split = s.split(",");
// 根据pid 获取对象
JoinBean joinBean = joinMap.get(split[2]);
if (joinBean == null) {
joinBean = joinMap.get("\uFEFF" + split[2]);
}
// 添加信息
joinBean.setId(split[0]);
joinBean.setDate(split[1]);
joinBean.setPid(split[2]);
joinBean.setAmount(split[3]);
// 输出
context.write(new Text(split[2]), new Text(joinBean.toString()));
}
}
3.2实现启动类
package com.czxy.order;
import com.czxy.flow.FlowBean;
import com.czxy.flow.FlowDriver;
import com.czxy.flow.FlowMapper;
import com.czxy.flow.FlowReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class MapJoinDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration configuration = new Configuration();
// 获取 HDFS 文件
DistributedCache.addCacheFile(new URI("hdfs://192.168.100.201:8020/input/product.txt"), configuration);
// 获取job
Job job = Job.getInstance(configuration);
// 设置支持jar执行
job.setJarByClass(MapJoinDriver.class);
// 设置执行的napper
job.setMapperClass(MapJoinMapper.class);
// 设置map输出的key类型
job.setMapOutputKeyClass(Text.class);
// 设置map输出value类型
job.setMapOutputValueClass(Text.class);
// 设置文件输入
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("./data/join/orders.txt"));
// 设置文件输出
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("./outPut/join/map"));
// 设置启动类
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new MapJoinDriver(), args);
}
}
4.实现reduce join
4.1创建map类
package com.czxy.order;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class ReduceJoinMap extends Mapper<LongWritable, Text, Text, JoinBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
JoinBean joinBean=new JoinBean();
// 类型转换
String s = value.toString();
// 字符串切割
String[] split = s.split(",");
// 获取当前读取的文件
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName();
System.out.println(fileName);
//判断文件名是不是order
if (fileName.contains("orders")) {
joinBean.setId(split[0]);
joinBean.setDate(split[1]);
joinBean.setPid(split[2]);
joinBean.setAmount(split[3]);
}else {
joinBean.setPid(split[0]);
joinBean.setName(split[1]);
joinBean.setCategoryId(split[2]);
joinBean.setPrice(split[3]);
}
//输出
context.write(new Text(joinBean.getPid()),joinBean);
}
}
4.2创建reduce代码
package com.czxy.order;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ReduceJoinReduce extends Reducer<Text, JoinBean, Text, JoinBean> {
@Override
protected void reduce(Text key, Iterable<JoinBean> values, Context context) throws IOException, InterruptedException {
// 创建对象 用来保存合并后的数据
JoinBean joinBean = new JoinBean();
// 定义两个变量用来标记对象是否添加了数据
boolean tab1 = false;
boolean tab2 = false;
for (JoinBean value : values) {
//判断是不是订单
if (value.getName() == null || value.getName().equals("null")) {
joinBean.setId(value.getId());
joinBean.setDate(value.getDate());
joinBean.setPid(value.getPid());
joinBean.setAmount(value.getAmount());
//改变标识
tab1 = true;
} else {
joinBean.setPid(value.getPid());
joinBean.setName(value.getName());
joinBean.setCategoryId(value.getCategoryId());
joinBean.setPrice(value.getPrice());
// 改变标识
tab2 = true;
}
if (tab1 && tab2) {
// 输出
context.write(key, joinBean);
}
}
}
}
4.3reduce的启动类
package com.czxy.order;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class ReduceJoinDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
// 获取job
Job job = Job.getInstance(new Configuration());
// 设置支持jar执行
job.setJarByClass(ReduceJoinDriver.class);
// 设置执行的napper
job.setMapperClass(ReduceJoinMap.class);
// 设置map输出的key类型
job.setMapOutputKeyClass(Text.class);
// 设置map输出value类型
job.setMapOutputValueClass(JoinBean.class);
// 设置执行的reduce
job.setReducerClass(ReduceJoinReduce.class);
// 设置reduce输出key的类型
job.setOutputKeyClass(Text.class);
// 设置reduce输出value的类型
job.setOutputValueClass(JoinBean.class);
// 设置文件输入
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("./data/join/"));
// 设置文件输出
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("./outPut/join/reduce"));
// 设置启动类
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new ReduceJoinDriver(), args);
}
}
5.需要的资源及执行结果
ordes.txt
1001,20150710,P0001,2
1002,20150710,P0001,3
1002,20150710,P0002,3product.txt
P0001,小米5,1000,2000
P0002,锤子T1,1000,3000
