背景:
在传统的异常检测与定位的方法下,存在一系列问题:比如异常区域可能很小也可能很大,异常的尺寸不定难以预测。
这种往往采用将在不同深度提取的特征统一起来的做法。
传统仅仅采用图的重构误差的做法也不再适用
问题一:当网络过强时,可能异常区域的重构与原图差异不大
问题二:它们无法重建以前从未见过的图像模式。

可以分为五个部分:
第一,采用预训练好了的模型进行特征提取
为了兼顾语义异常和像素异常,将在不同深度提取的特征统一起来。
第二部分,划分集合
训练集都是正常的,称为Gallery set
测试集称为Query set
第三部分,重构子图
这和传统的重构图是截然不同的。
在Query set中有某一节点A,A的特征向量是,在Gallery中找和A特征最接近的k个点,knn临近法
第四部分,计算是异常的可能性
然后将这k个点的特征混合在一起,得到一个新的特征向量

检测异常的原理就是, 和
的差异越大,是异常的可能性就越大
这一部分,我尝试从聚类的角度来理解。

假设,训练集都是正常图,我们将从中提取的特征画在一个n维图上,如上所示。
举例子,狗图片像素点特征汇聚在一起,用绿色标注;猫图片像素点特征汇聚在一起,用红色标注,老虎图片像素点特征汇聚在一起,用蓝色标注。
在进行异常检测时重构图模型时:
第一步,在Query set(测试集)中有某一节点A,A的特征向量是,在Gallery(训练集)中找和A特征最接近的k个点。
当k个点涵盖多个颜色时,意味着这点大概率异常,因此不讨论。
当k个点只有一个颜色时,例如红色,表示该节点应该是属于猫图片的,将问题广度缩小到猫这一具体类型上。
第二步,然后将这k个点的特征混合在一起,得到一个新的特征向量 ,节点A特征与
的差异越大,A异常的可能性就越大。
类比聚类算法,节点A特征与的差异越大,这表明节点A离这个聚类中心就越远(在刚才提到的例子中就是,节点A离猫图片类的距离越远),于是A是异常点的概率越大。
第五部分,加权多尺度异常图匹配
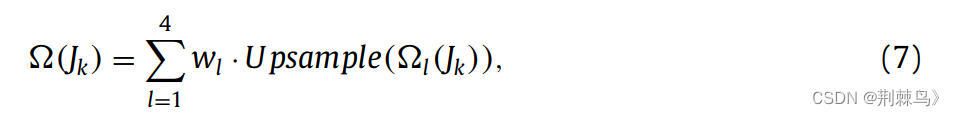
关于某一个像素点是不是异常,有一个阈值τ1,关于整幅图像是不是异常,有一个阈值τ2,这两个阈值都是动态变化的,根据FPR的值不断调整。

至于权重是根据不同层次下分割的结果决定 的
其实细想下来,为了解决“不能处理没见过的图像类型”,采用的是和VAE类似的方法。


