转载自:https://blog.csdn.net/taoyanqi8932/article/details/71101699
https://blog.csdn.net/Left_Think/article/details/77684087?locationNum=5&fps=1
过拟合即在训练误差很小,而泛化误差很大,因为模型可能过于的复杂,使其”记住”了训练样本,然而其泛化误差却很高,在传统的机器学习方法中有很大防止过拟合的方法,同样这些方法很多也适合用于深度学习中,同时深度学习中又有一些独特的防止过拟合的方法,下面对其进行简单的梳理.
1. 加入正则化项,参数范数惩罚
范数正则化是一种非常普遍的方法,也是最常用的方法,假如优化:

其中 L 为经验风险,其为在训练样本上的误差,而 G 为对参数的惩罚,也叫结构风险. α 是平衡两者,如果太大则对应的惩罚越大,如过太小,甚至接近与0,则没有惩罚.
最常用的范数惩罚为L1,L2正则化,L1又被成为 Lasso :

即绝对值相加,其趋向于是一些参数为0.可以起到特征选择的作用.
L2正则化为:

其趋向与,使权重很小.其又成为 ridge .
关于更多可以参考: 机器学习中的范数规则化之(一)L0、L1与L2范数
L1正则与L2正则的思想就是不能够一味的去减小损失函数,你还得考虑到模型的复杂性,通过限制参数的大小,来限制其产生较为简单的模型,这样就可以降低产生过拟合的风险。
它们的区别在于L1更容易得到稀疏解。为什么呢?我们先看看一个直观的例子:

假设我们模型只有 w1,w2 两个参数,上图中左图中黑色的正方形是L1正则项的等值线,而彩色的圆圈是模型损失的等值线;右图中黑色圆圈是L2正则项的等值线,彩色圆圈是同样模型损失的等值线。因为我们引入正则项之后,我们要在模型损失和正则化损失之间折中,因此我们去的点是正则项损失的等值线和模型损失的等值线相交处。通过上图我们可以观察到,使用L1正则项时,两者相交点常在坐标轴上,也就是 w1,w2 中常会出现0;而L2正则项与等值线常相交于象限内,也即为 w1,w2 非0。因此L1正则项时更容易得到稀疏解的。
而使用L1正则项的另一个好处是:由于L1正则项求解参数时更容易得到稀疏解,也就意味着求出的参数中含有0较多。因此它自动帮你选择了模型所需要的特征。L1正则化的学习方式是一种嵌入式特征学习方式,它选取特征和模型训练时一起进行的。
2. 数据增强,增加样本数据量
让模型泛化的能力更好的最好办法就是使用更多的训练数据进行训练,但是在实践中,我们拥有的数据是有限的,解决这一问题可以人为的创造一些假数据添加到训练集中.
一个具体的例子:
在AlexNet中,将256*256图像随机的截取224*224大小,增加了许多的训练样本,同时可以对图像进行左右翻转,增加样本的个数,实验的结果可以可降低1%的误差.
在神经网络中输入噪声也可以看做是数据增强的一种方式.
在实际的项目中,你会发现,那些技巧虽然都可以减轻过拟合的风险,但是却都比不上增加样本量来的更实在。为什么增加样本可以减轻过拟合的风险呢?这个要从过拟合是啥来说。过拟合可以理解为我们的模型对样本量学习的太好了,把一些样本的特殊的特征当做是所有样本都具有的特征。举个简单的例子,当我们模型去训练如何判断一个东西是不是叶子时,我们样本中叶子如果都是锯齿状的话,如果模型产生过拟合了,会认为叶子都是锯齿状的,而不是锯齿状的就不是叶子了。如果此时我们把不是锯齿状的叶子数据增加进来,此时我们的模型就不会再过拟合了。因此其实上述的那些技巧虽然有用,但是在实际项目中,你会发现,其实大多数情况都比不上增加样本数据来的实在。
3. 提前终止(early stopping)
如下图所示(图片来源deep learning),当随着模型的能力提升,训练集的误差会先减小再增大,这样可以提前终止算法减缓过拟合现象.关于算法的具体流程参考deep learning.
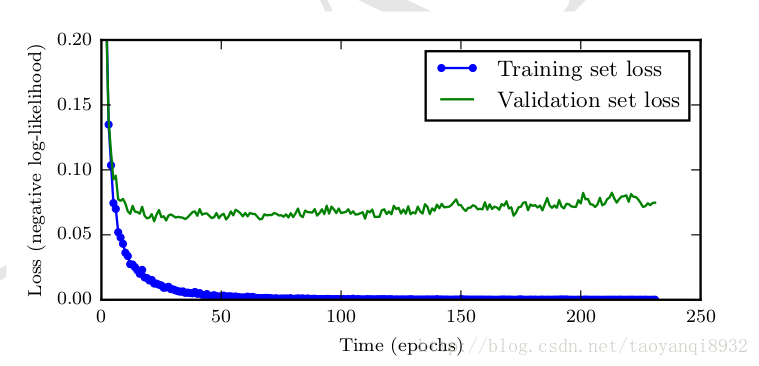
提前终止是一种很常用的缓解过拟合的方法,如在决策树的先剪枝的算法,提前终止算法,使得树的深度降低,防止其过拟合.
在对模型进行训练时,我们可以将我们的数据集分为三个部分,训练集、验证集、测试集。我们在训练的过程中,可以每隔一定量的step,使用验证集对训练的模型进行预测,一般来说,模型在训练集和验证集的损失变化如下图所示:
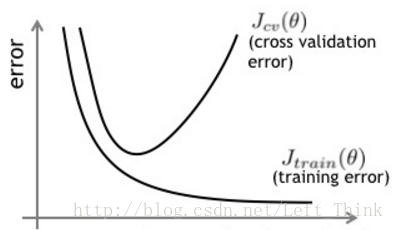
可以看出,模型在验证集上的误差在一开始是随着训练集的误差的下降而下降的。当超过一定训练步数后,模型在训练集上的误差虽然还在下降,但是在验证集上的误差却不在下降了。此时我们的模型就过拟合了。因此我们可以观察我们训练模型在验证集上的误差,一旦当验证集的误差不再下降时,我们就可以提前终止我们训练的模型。
4. 参数绑定与参数共享
在卷积神经网络CNN中(计算机视觉与卷积神经网络 ),卷积层就是其中权值共享的方式,一个卷积核通过在图像上滑动从而实现共享参数,大幅度减少参数的个数,用卷积的形式是合理的,因为对于一副猫的图片来说,右移一个像素同样还是猫,其具有局部的特征.这是一种很好的缓解过拟合现象的方法.
同样在RNN中用到的参数共享,在其整条时间链上可以进行参数的共享,这样才使得其能够被训练.
5. bagging 和其他集成方法
其实bagging的方法是可以起到正则化的作用,因为正则化就是要减少泛化误差,而bagging的方法可以组合多个模型起到减少泛化误差的作用.
在深度学习中同样可以使用此方法,但是其会增加计算和存储的成本.
6. Dropout
Dropout提供了一种廉价的Bagging集成近似,能够训练和评估指数级数量的神经网络。dropout可以随机的让一部分神经元失活,这样仿佛是bagging的采样过程,因此可以看做是bagging的廉价的实现.
但是它们训练不太一样,因为bagging,所有的模型都是独立的,而dropout下所有模型的参数是共享的.
通常可以这样理解dropout:假设我们要判别一只猫,有一个神经元说看到有毛就是猫,但是如果我让这个神经元失活,它还能判断出来是猫的话,这样就比较具有泛化的能力,减轻了过拟合的风险.
Dropout是在深度学习中降低过拟合风险的常见方法,它是由大牛Hinton老爷子提出的。老爷子认为在神经网络产生过拟合主要是因为神经元之间的协同作用产生的。因此老爷子在神经网络进行训练的时候,让部分神经元失活,这样就阻断了部分神经元之间的协同作用,从而强制要求一个神经元和随机挑选出的神经元共同进行工作,减轻了部分神经元之间的联合适应性。
Dropout的具体流程如下:

7. 辅助分类节点(auxiliary classifiers)
在Google Inception V1中,采用了辅助分类节点的策略,即将中间某一层的输出用作分类,并按一个较小的权重加到最终的分类结果中,这样相当于做了模型的融合,同时给网络增加了反向传播的梯度信号,提供了额外的正则化的思想.
8. Batch Normalization
在Google Inception V2中所采用,是一种非常有用的正则化方法,可以让大型的卷积网络训练速度加快很多倍,同事收敛后分类的准确率也可以大幅度的提高.

未完待续…
参考资料:
- deep learning
- tensorflow实战
- 机器学习中的范数规则化之(一)L0、L1与L2范数