原文地址:一只鸟的天空,http://blog.csdn.net/heyongluoyao8/article/details/49429629
防止过拟合的处理方法
过拟合
我们都知道,在进行数据挖掘或者机器学习模型建立的时候,因为在统计学习中,假设数据满足独立同分布(i.i.d,independently and identically distributed),即当前已产生的数据可以对未来的数据进行推测与模拟,因此都是使用历史数据建立模型,即使用已经产生的数据去训练,然后使用该模型去拟合未来的数据。但是一般独立同分布的假设往往不成立,即数据的分布可能会发生变化(distribution drift),并且可能当前的数据量过少,不足以对整个数据集进行分布估计,因此往往需要防止模型过拟合,提高模型泛化能力。而为了达到该目的的最常见方法便是:正则化,即在对模型的目标函数(objective function)或代价函数(cost function)加上正则项。
在对模型进行训练时,有可能遇到训练数据不够,即训练数据无法对整个数据的分布进行估计的时候,或者在对模型进行过度训练(overtraining)时,常常会导致模型的过拟合(overfitting)。如下图所示:
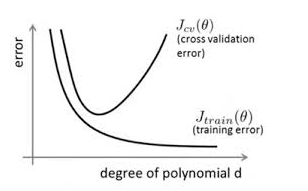
通过上图可以看出,随着模型训练的进行,模型的复杂度会增加,此时模型在训练数据集上的训练误差会逐渐减小,但是在模型的复杂度达到一定程度时,模型在验证集上的误差反而随着模型的复杂度增加而增大。此时便发生了过拟合,即模型的复杂度升高,但是该模型在除训练集之外的数据集上却不work。
为了防止过拟合,我们需要用到一些方法,如:early stopping、数据集扩增(Data augmentation)、正则化(Regularization)、Dropout等。
Early stopping
对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
Early stopping方法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation data的accuracy,当accuracy不再提高时,就停止训练。这种做法很符合直观感受,因为accurary都不再提高了,在继续训练也是无益的,只会提高训练的时间。那么该做法的一个重点便是怎样才认为validation accurary不再提高了呢?并不是说validation accuracy一降下来便认为不再提高了,因为可能经过这个Epoch后,accuracy降低了,但是随后的Epoch又让accuracy又上去了,所以不能根据一两次的连续降低就判断不再提高。一般的做法是,在训练的过程中,记录到目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。此时便可以停止迭代了(Early Stopping)。这种策略也称为“No-improvement-in-n”,n即Epoch的次数,可以根据实际情况取,如10、20、30……
数据集扩增
在数据挖掘领域流行着这样的一句话,“有时候往往拥有更多的数据胜过一个好的模型”。因为我们在使用训练数据训练模型,通过这个模型对将来的数据进行拟合,而在这之间又一个假设便是,训练数据与将来的数据是独立同分布的。即使用当前的训练数据来对将来的数据进行估计与模拟,而更多的数据往往估计与模拟地更准确。因此,更多的数据有时候更优秀。但是往往条件有限,如人力物力财力的不足,而不能收集到更多的数据,如在进行分类的任务中,需要对数据进行打标,并且很多情况下都是人工得进行打标,因此一旦需要打标的数据量过多,就会导致效率低下以及可能出错的情况。所以,往往在这时候,需要采取一些计算的方式与策略在已有的数据集上进行手脚,以得到更多的数据。
通俗得讲,数据机扩增即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。一般有以下方法:
- 从数据源头采集更多数据
- 复制原有数据并加上随机噪声
- 重采样
- 根据当前数据集估计数据分布参数,使用该分布产生更多数据等
正则化方法
正则化方法是指在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。
- L1正则
L1正则是基于L1范数,即在目标函数后面加上参数的L1范数和项,即参数绝对值和与参数的积项,即:
C=C0+λn∑w|w|
其中C0 代表原始的代价函数,n 是样本的个数,λ 就是正则项系数,权衡正则项与C0 项的比重。后面那一项即为L1正则项。
在计算梯度时,w 的梯度变为:
∂C∂w=∂C0∂w+λnsgn(w)
其中,sgn 是符号函数,那么便使用下式对参数进行更新:
w:=w+α∂C0∂w+βλnsgn(w)
对于有些模型,如线性回归中(L1正则线性回归即为Lasso回归),常数项b 的更新方程不包括正则项,即:
b:=b+α∂C0∂b
其中,梯度下降算法中,α<0,β<0 ,而在梯度上升算法中则相反。
从上式可以看出,当w 为正时,更新后w 会变小;当w 为负时,更新后w 会变大;因此L1正则项是为了使得那些原先处于零(即|w|≈0 )附近的参数w 往零移动,使得部分参数为零,从而降低模型的复杂度(模型的复杂度由参数决定),从而防止过拟合,提高模型的泛化能力。
其中,L1正则中有个问题,便是L1范数在0处不可导,即|w| 在0处不可导,因此在w 为0时,使用原来的未经正则化的更新方程来对w 进行更新,即令sgn(0)=0 ,这样即:
sgn(w)|w>0=1,sgn(w)|w<0=−1,sgn(w)|w=0=0 - L2正则
L2正则是基于L2范数,即在目标函数后面加上参数的L2范数和项,即参数的平方和与参数的积项,即:
C=C0+λ2n∑ww2
其中C0 代表原始的代价函数,n 是样本的个数,与L1正则化项前面的参数不同的是,L2项的参数乘了12 ,是为了便于计算以及公式的美感性,因为平方项求导有个2,λ 就是正则项系数,权衡正则项与C0 项的比重。后面那一项即为L2正则项。
L2正则化中则使用下式对模型参数进行更新:
w:=w+α∂C0∂w+βλnw
对于有些模型,如线性回归中(L2正则线性回归即为Ridge回归,岭回归),常数项b 的更新方程不包括正则项,即:
b:=b+α∂C0∂b
其中,梯度下降算法中,α<0,β<0 ,而在梯度上升算法中则相反。
从上式可以看出,L2正则项起到使得参数w 变小加剧的效果,但是为什么可以防止过拟合呢?一个通俗的理解便是:更小的参数值w 意味着模型的复杂度更低,对训练数据的拟合刚刚好(奥卡姆剃刀),不会过分拟合训练数据,从而使得不会过拟合,以提高模型的泛化能力。
在这里需要提到的是,在对模型参数进行更新学习的时候,有两种更新方式,mini-batch (部分增量更新)与 full-batch(全增量更新),即在每一次更新学习的过程中(一次迭代,即一次epoch),在mini-batch中进行分批处理,先使用一部分样本进行更新,然后再使用一部分样本进行更新。直到所有样本都使用了,这次epoch的损失函数值则为所有mini batch的平均损失值。设每次mini batch中样本个数为m ,那么参数的更新方程中的正则项要改成:
λm∑w|w|
λ2m∑ww2
而full-batch即每一次epoch中,使用全部的训练样本进行更新,那么每次的损失函数值即为全部样本的误差之和。更新方程不变。 -
在神经网络中:Regularized网络更鼓励小的权重, 小的权重的情况下, x一些随机的变化不会对神经网络的模型造成太大影响, 所以更小可能受到数据局部噪音的影响.Un-regularized神经网路, 权重更大, 容易通过神经网络模型比较大的改变来适应数据,更容易学习到局部数据的噪音Regularized更倾向于学到更简单一些的模型简单的模型不一定总是更好,要从大量数据实验中获得,目前添加regularization可以更好的泛化更多的从实验中得来,理论的支持还在研究之中
- 总结
-
都是减小权重, 方法不同:L1减少一个常量, L2减少权重的一个固定比例如果权重本身很大, L1减少的比L2少很多如果权重本身很小, L1减少的更多
L1倾向于集中在少部分重要的连接上当w=0, 偏导数∂C/∂w无意义, 因为|w|的形状在w=0时是一个V字形尖锐的拐点.所以, 当w=0时,我们就使用un-regulazied表达式, sgn(0) = 0. 本来regularization的目的就是减小权重, 当权重=0时,无需减少
正则项是为了降低模型的复杂度,从而避免模型区过分拟合训练数据,包括噪声与异常点(outliers)。从另一个角度上来讲,正则化即是假设模型参数服从先验概率,即为模型参数添加先验,只是不同的正则化方式的先验分布是不一样的。这样就规定了参数的分布,使得模型的复杂度降低(试想一下,限定条件多了,是不是模型的复杂度降低了呢),这样模型对于噪声与异常点的抗干扰性的能力增强,从而提高模型的泛化能力。还有个解释便是,从贝叶斯学派来看:加了先验,在数据少的时候,先验知识可以防止过拟合;从频率学派来看:正则项限定了参数的取值,从而提高了模型的稳定性,而稳定性强的模型不会过拟合,即控制模型空间。
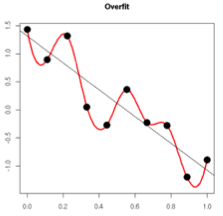
另外一个角度,过拟合从直观上理解便是,在对训练数据进行拟合时,需要照顾到每个点,从而使得拟合函数波动性非常大,即方差大。在某些小区间里,函数值的变化性很剧烈,意味着函数在某些小区间里的导数值的绝对值非常大,由于自变量的值在给定的训练数据集中的一定的,因此只有系数足够大,才能保证导数的绝对值足够大。如下图(引用知乎):
另外一个解释,规则化项的引入,在训练(最小化cost)的过程中,当某一维的特征所对应的权重过大时,而此时模型的预测和真实数据之间距离很小,通过规则化项就可以使整体的cost取较大的值,从而,在训练的过程中避免了去选择那些某一维(或几维)特征的权重过大的情况,即过分依赖某一维(或几维)的特征(引用知乎)。
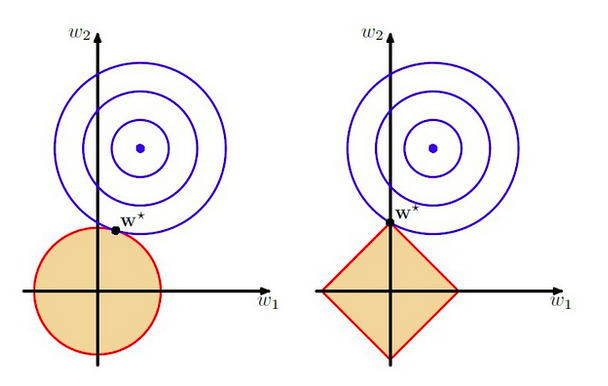
L2与L1的区别在于,L1正则是拉普拉斯先验,而L2正则则是高斯先验。它们都是服从均值为0,协方差为1λ 。当λ=0 时,即没有先验)没有正则项,则相当于先验分布具有无穷大的协方差,那么这个先验约束则会非常弱,模型为了拟合所有的训练集数据, 参数w 可以变得任意大从而使得模型不稳定,即方差大而偏差小。λ 越大,标明先验分布协方差越小,偏差越大,模型越稳定。即,加入正则项是在偏差bias与方差variance之间做平衡tradeoff(来自知乎)。下图即为L2与L1正则的区别:
上图中的模型是线性回归,有两个特征,要优化的参数分别是w1和w2,左图的正则化是L2,右图是L1。蓝色线就是优化过程中遇到的等高线,一圈代表一个目标函数值,圆心就是样本观测值(假设一个样本),半径就是误差值,受限条件就是红色边界(就是正则化那部分),二者相交处,才是最优参数。可见右边的最优参数只可能在坐标轴上,所以就会出现0权重参数,使得模型稀疏。
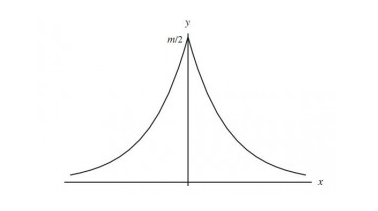
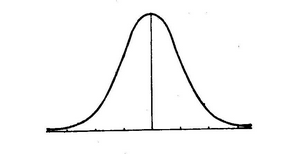
其实拉普拉斯分布与高斯分布是数学家从实验中误差服从什么分布研究中得来的。一般直观上的认识是服从应该服从均值为0的对称分布,并且误差大的频率低,误差小的频率高,因此拉普拉斯使用拉普拉斯分布对误差的分布进行拟合,如下图:
而拉普拉斯在最高点,即自变量为0处不可导,因为不便于计算,于是高斯在这基础上使用高斯分布对其进行拟合,如下图:
具体参见:正态分布的前世今生
Dropout
正则是通过在代价函数后面加上正则项来防止模型过拟合的。而在神经网络中,有一种方法是通过修改神经网络本身结构来实现的,其名为Dropout。该方法是在对网络进行训练时用一种技巧(trick),对于如下所示的三层人工神经网络:
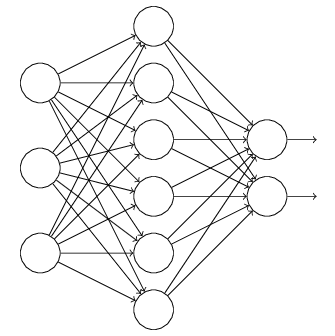
对于上图所示的网络,在训练开始时,随机得删除一些(可以设定为一半,也可以为1/3,1/4等)隐藏层神经元,即认为这些神经元不存在,同时保持输入层与输出层神经元的个数不变,这样便得到如下的ANN:
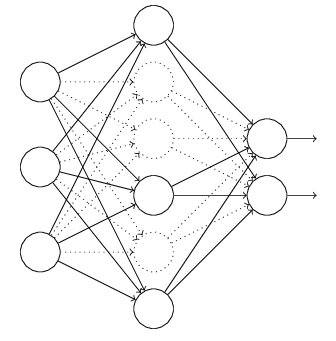
然后按照BP学习算法对ANN中的参数进行学习更新(虚线连接的单元不更新,因为认为这些神经元被临时删除了)。这样一次迭代更新便完成了。下一次迭代中,同样随机删除一些神经元,与上次不一样,做随机选择。这样一直进行更新w和b,直至训练结束。
-
奥康姆剃刀