1:确定一个小目标:预测函数
机器学习的一个常见任务是 通过学习算法,自动发现数据 背后的规律,不断改进模型,然后做出预测。
即:学习算法—发现规律—改进模型—做出预测
为了方便理解,我们举一个简单的例子:在二维直角坐标系中有一些样本点,横纵坐标分别代表一组有因果关系的变量,比如房子的价格和面积。
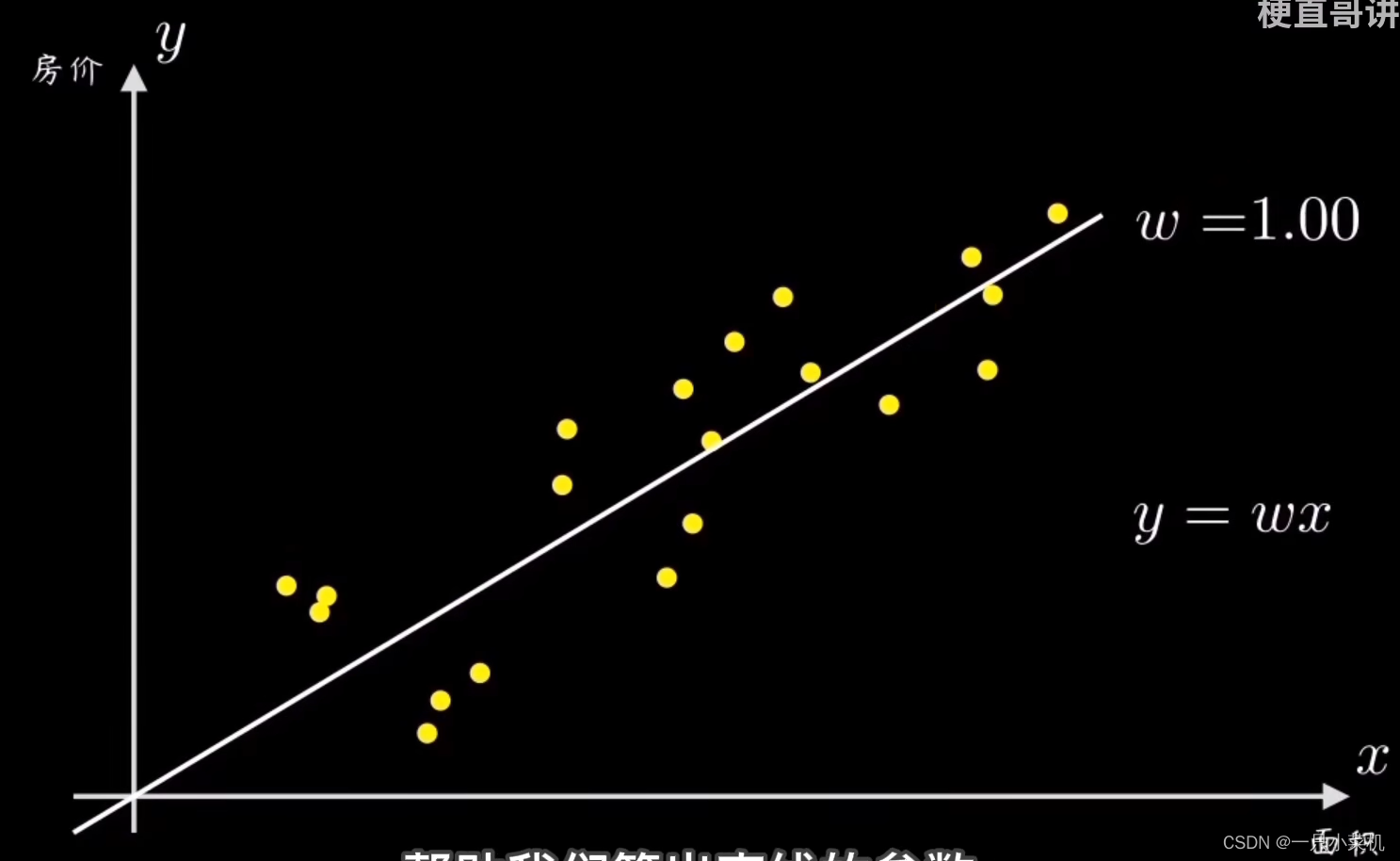
常识告诉我们,它们的分布是成正比的,也就是一条过原点的直线y=wx 。我们的任务就是设计一个算法,让机器能够拟合这些数据,帮助我们算出直线的参数w。
一个简单的办法就是:先随即选一条过原点的直线。
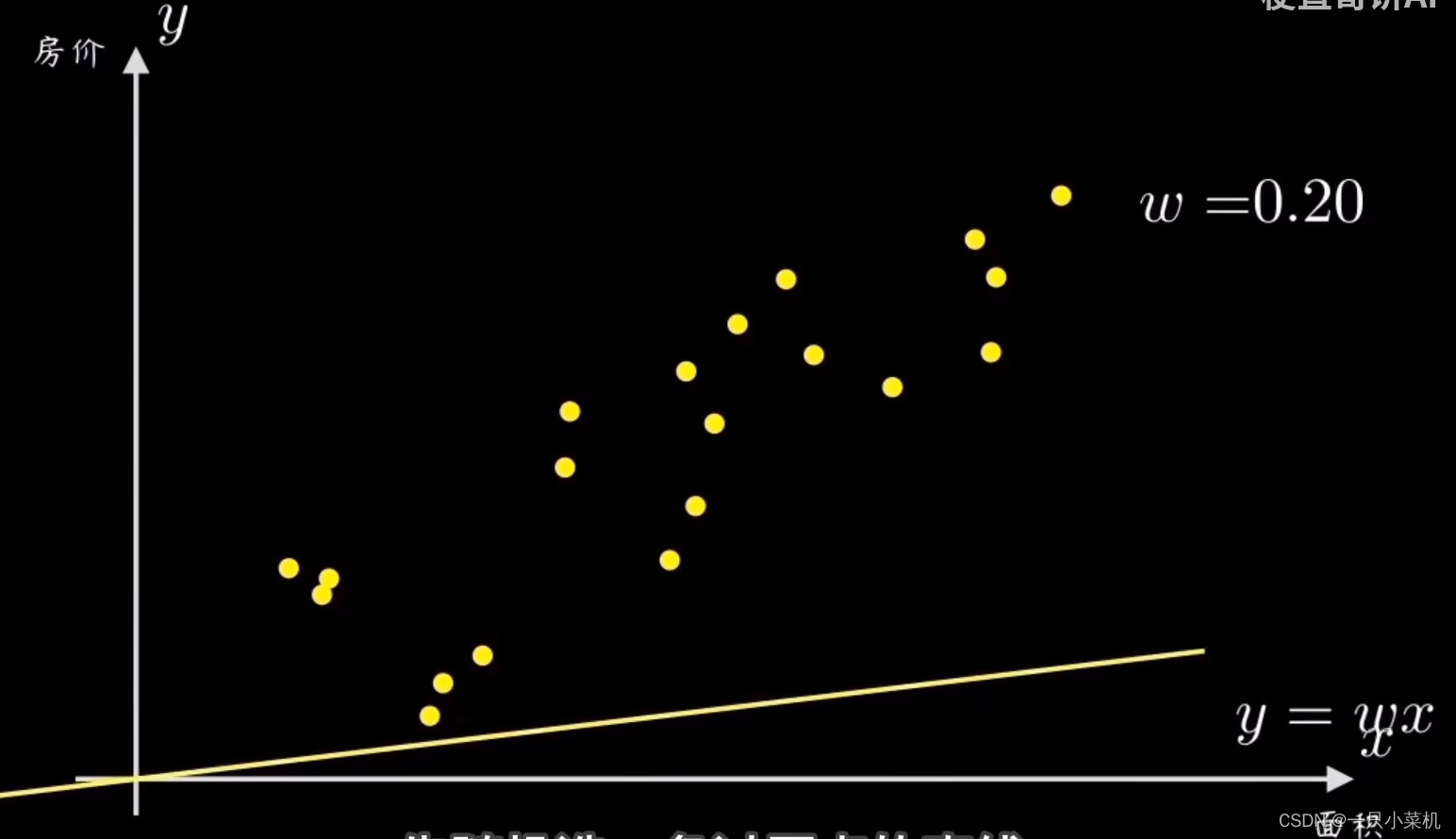
然后计算所有样本点和这条直线的偏离程度,再根据误差大小来调整直线的斜率w。在这个问题中,直线y=wx就是所谓的预测函数。
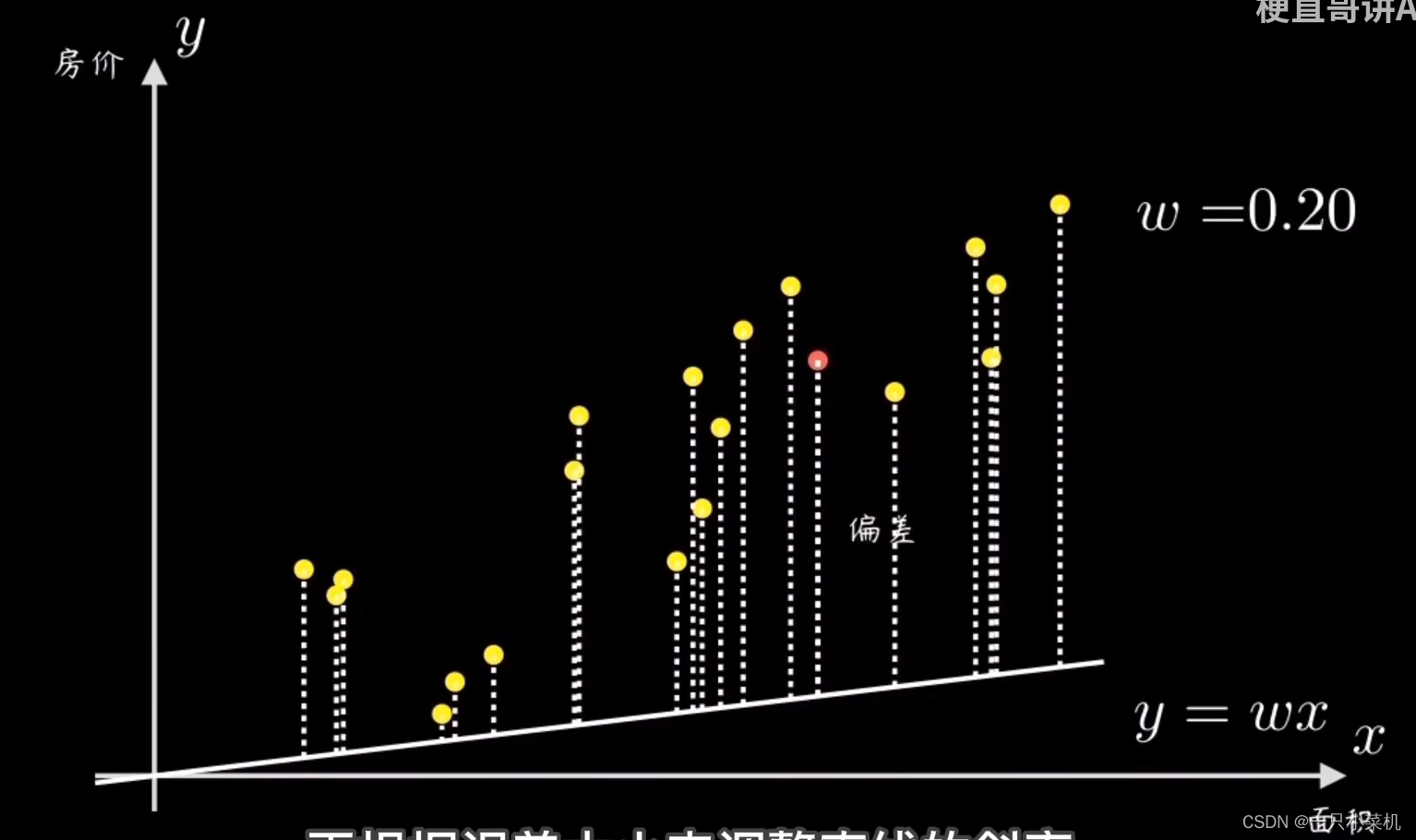
2:找到差距:代价函数
(ps:“损失函数(Loss Function )是定义在单个样本上的,算的是一个样本的误差。 代价函数(Cost Function )是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。)
首先,我们需要量化数据的偏离程度,也就是误差。最常见的方法是均方误差,顾名思义,就是误差平方和的平均值。
我们先来看一个点p1(x1,y1),对应的误差是e1(这边说的是均方误差)。 我们可以知道,e1=(y1-wx1)² 。
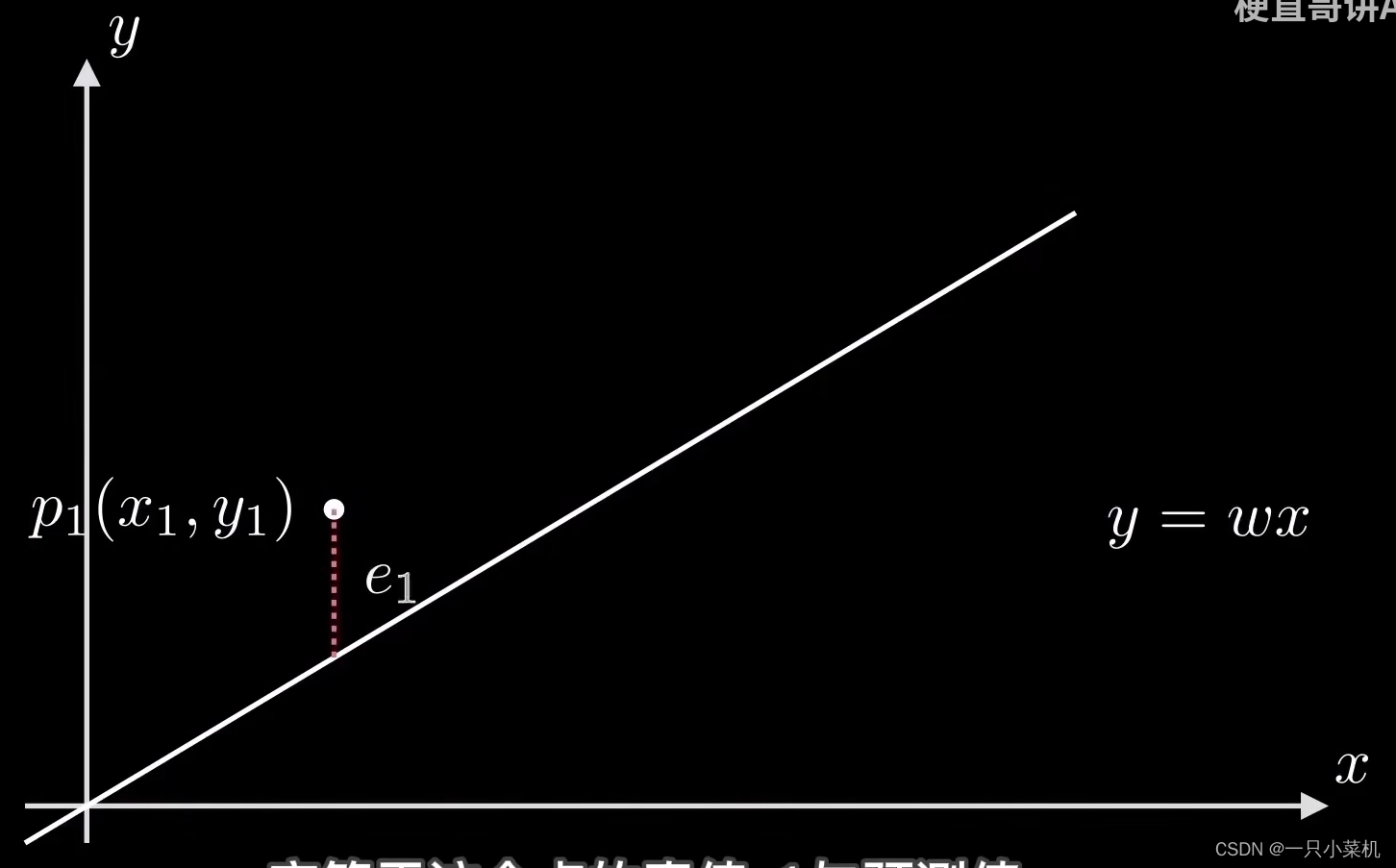
用完全平方公式展开后得到如下图的公式。同理,点p2,p3一直到pn的误差e2,e3,en 也都是一样的形式。我们的目的是求所有点误差的平均值,考虑到x,y和样本数n都是已知数。
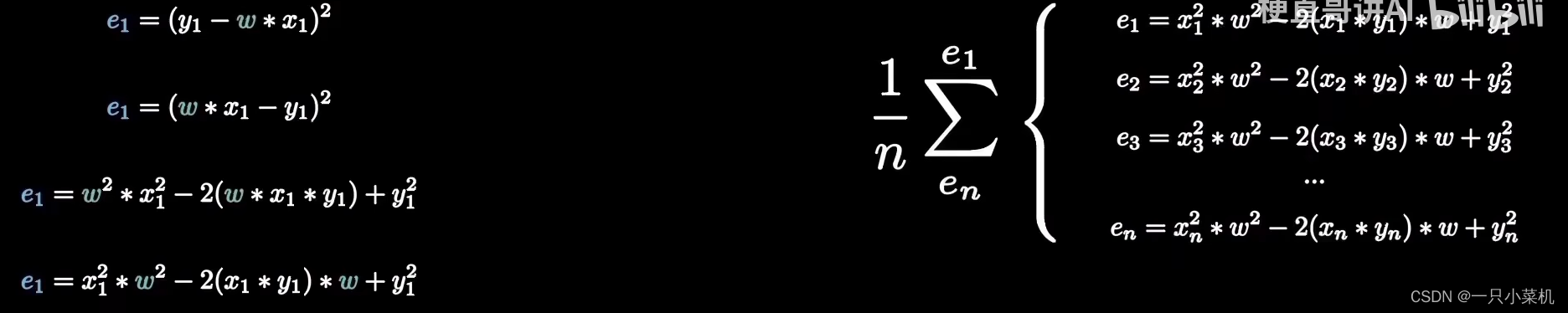
因此,通过合并同类项,然后用常量abc分别代替不同项的系数。--------未完待续