对机器学习感兴趣,上网易公开课听吴恩达得机器学习课程,第二堂课得梯度下降就不是特别懂
度娘一下,发现一篇博客,阅之,毛瑟顿开,整理如下、
原博地址http://www.cnblogs.com/LeftNotEasy/archive/2010/12/05/mathmatic_in_machine_learning_1_regression_and_gradient_descent.html
引入第一个概念拟合函数
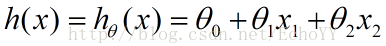
这个函数说白了就是ax+by+c,只不过这里x,y记为x1,x2、a,b,c记为theta0~2
其中x1,x2…xn是一组特征值,是数据调研得到的一组数据,所以这里其实重要得是theta,中间的HthetaX
令x1=1则有了下式
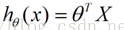
这里得thetaT其实就是theta得一组向量,也就对应了吴教授视频得取theta=0向量那一段
注意这个公式里X是大写的X而不是小写的x1,x2其实也就是泛指一组数据而不是一个具体得维度
那么又怎么确定这个h(x)也就是theta向量取得nice呢?很自然得引入了损失函数

公式,因为是取一组奈斯得theta值,所以参数从x变为了theta,设为J
叠加符号里m为数据得组数
梯度下降得图形里是各种漂亮得弧面型
其中由于将其画在二维平面上,因此智能展示三个维度的立体坐标系
注意看的话会发现其纵轴也就是Z轴是损失函数J,而两个横轴均为theta
所以图形上的一个点也就对应着给定一组theta,即给定一个向量theta后的J的值。
因为我们的目的是使J值尽可能的小,其充分必要条件就是在梯度下降的“山脉”图里的最低点,也就是等高线里的最低点

视频里对应上图时间点是这样的描述“梯度下降算法经过第一次迭代之后,由于改变了参数的空间,所以一次梯度下降之后会得到这样的结果”
那么问题自然而然的就回归到在给定坐标系的一组<theta,J>值后,一次次迭代找到最奈斯的theta值。
对应房屋售价估算场景里。
这是给定初始theta的图

而经过一次迭代之后,也就是第一次更新theta的值,J的函数值发生了变化

经过n次迭代之后,也就得到了最奈斯的J值
至于为啥梯度下降可以得到最奈斯的值,假如theta只有一个维度,那么J(theta)是一个二次函数,
同时J(theta)的表达式中偏导数符号变成了导数符号,而换到二次函数上时,某一点的到数值是该点的切线值,沿着切线可以递归到函数的极小值点