http://ruder.io/optimizing-gradient-descent/
https://www.jiqizhixin.com/articles/2016-11-21-4
tensorflow-梯度下降(代码)
深度解读最流行的优化算法:梯度下降(精简版)
这里主要进行梯度公式推导,基本知识和内容可参考上述博客:
(一)、Cost Function
线性回归是给出一系列点假设拟合直线为h(x)=theta0+theta1*x, 记Cost Function为J(theta0,theta1)
之所以说单参数是因为只有一个变量x,即影响回归参数θ1,θ0的是一维变量,或者说输入变量只有一维属性。

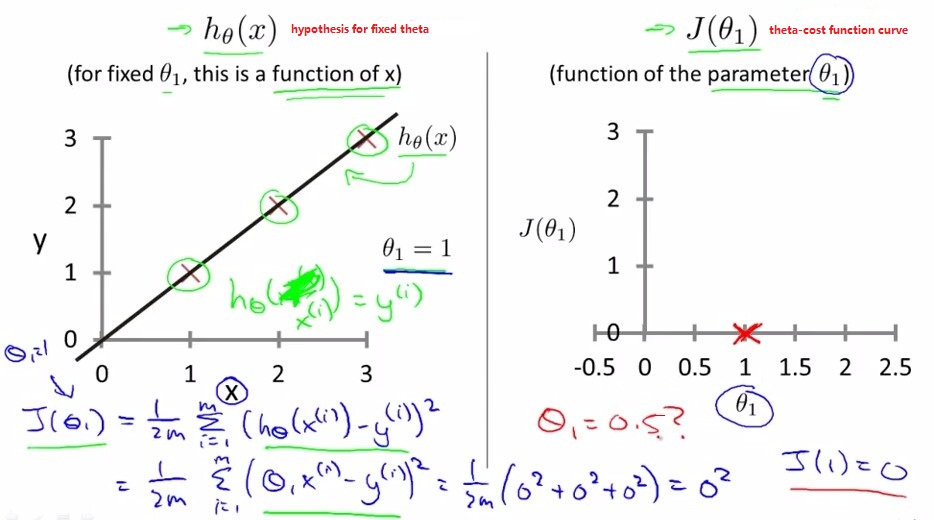
下图中为简化模式,只有theta1没有theta0的情况,即拟合直线为h(x)=theta1*x
左图为给定theta1时的直线和数据点×
右图为不同theta1下的cost function J(theta1)
cost function plot:

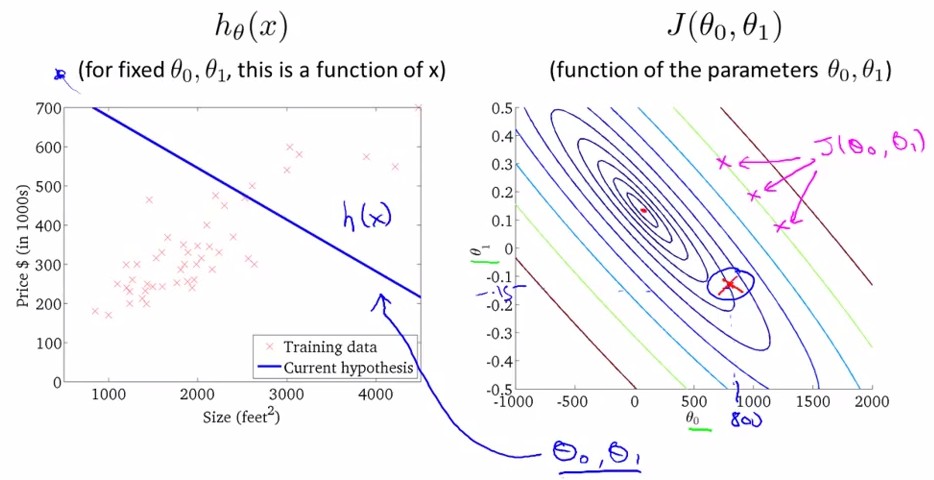
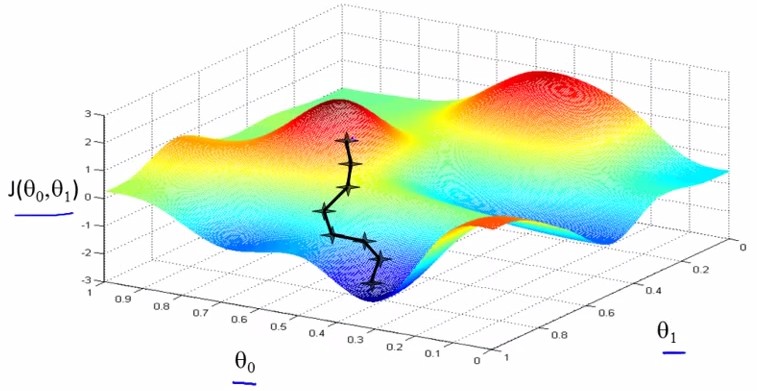
当存在两个参数theta0和theta1时,cost function是一个三维函数,这种样子的图像叫bowl-shape function

将上图中的cost function在二维上用不同颜色的等高线映射为如下右图,可得在左图中给定一个(theta0,theta1)时又图中显示的cost function.

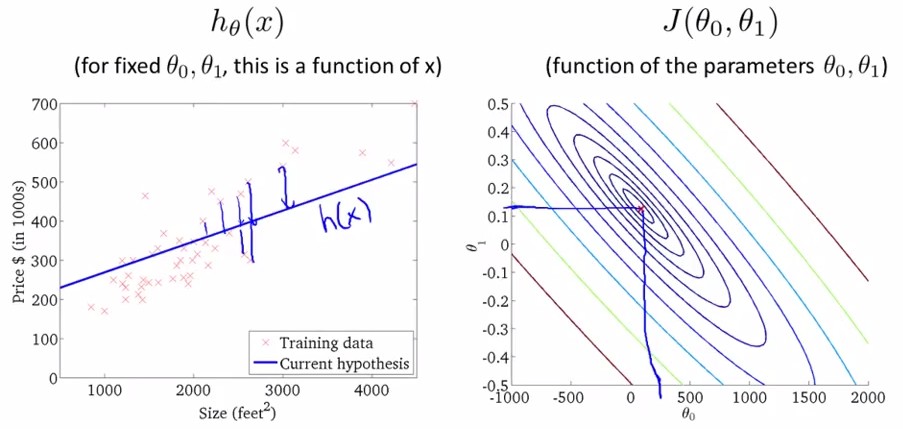
我们的目的是最小化cost function,即上图中最后一幅图,theta0=450,theta1=0.12的情况。
(二)、Gradient descent
gradient descent是指梯度下降,为的是将cost funciton 描绘出之后,让参数沿着梯度下降的方向走,并迭代地不断减小J(theta0,theta1),即稳态。

每次沿着梯度下降的方向:
参数的变换公式:其中标出了梯度(蓝框内)和学习率(α):

gradient即J在该点的切线斜率slope,tanβ。下图所示分别为slope(gradient)为正和负的情况:
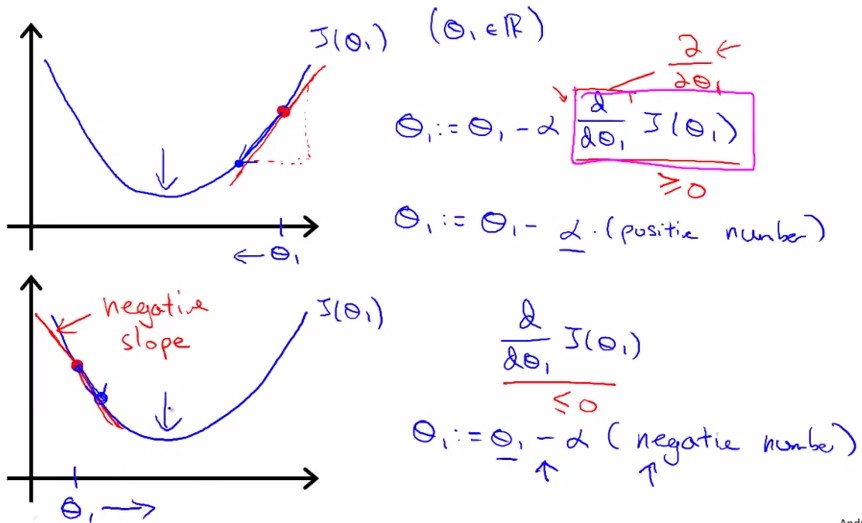
同时更新theta0和theta1,左边为正解:

关于学习率:
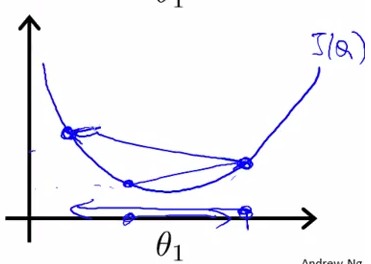
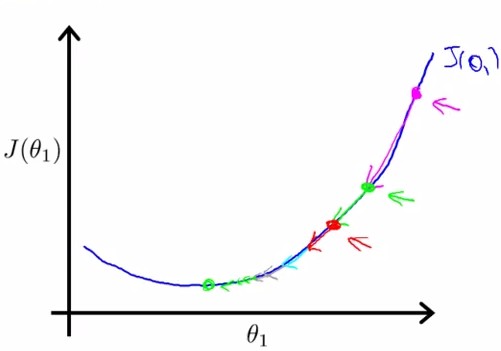
α太小:学习很慢; α太大:容易过学习
所以如果陷入局部极小,则slope=0,不会向左右变换
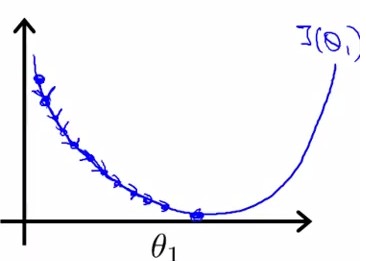
本图表示:无需逐渐减小α,就可以使下降幅度逐渐减小(因为梯度逐渐减小):
求导后:
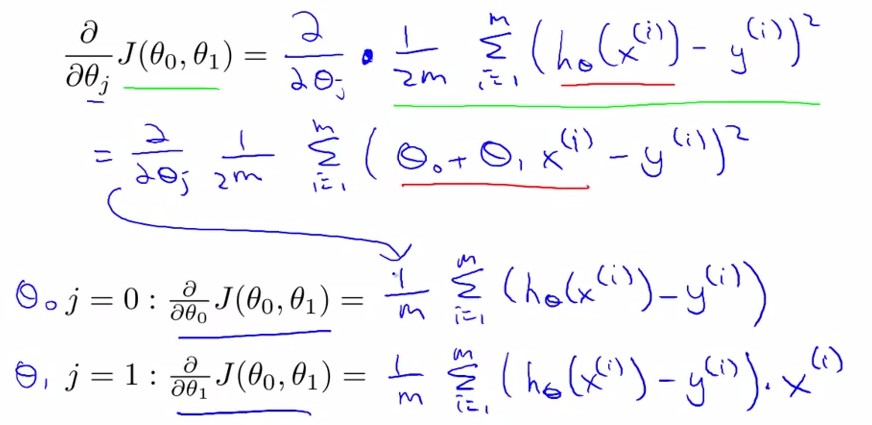
由此我们得到:
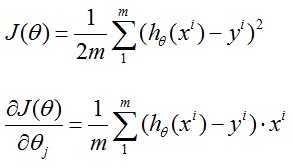

其中x(i)表示输入数据x中的第i组数据
梯度下降step1: 
step 2:

step 3:求偏导过程
所以,我们需要对每一个特征让它沿着导数递减的方向去移动:
对一个函数求偏导数,我们得出的是这个函数是上升/下降和他们的幅度,如果一个函数过于陡峭,我们很有可能移动过多,跑到了最低点的另外一边,然后下一次迭代又跑到了另外一边,循环往复……因此采用α来控制步长,避免移动过快或过慢 。 矩阵运算其实,上面我们已经可以解决一般线性方程求近似最小值的问题了,但上面的方式不够直观,也不够简单,现在我们换一种解决方式——矩阵。 我们先将参数使用矩阵表示:
样本参数矩阵:
其中m代表是m个样本。

当我们将样本使用矩阵表示以后,h(θ)的表示就变成了:
对应的误差函数J(θ)自然也可以使用矩阵去表示。

通过一个m*n的矩阵我们就可以将有N个特征值、M个训练样本的误差值表示出来。
上面我们是通过最小二乘法去表示损失函数的,现在我们将矩阵表达的误差函数代入最小二乘法,得到下面的J(θ)表达式: 
在进行公示推导之前,我们先复习几个矩阵运算的基础知识。 
结合等式(2)和(3)我们又可以得出一个新的等式:

回忆完上面的线性代数基础以后,我们可以下面开始我们愉快的推导了: 
在第三步的时候,我们利用了一个实数的trace等于这个实数的性质。 第四步的时候,我们利用了一个矩阵的trace=它的转置矩阵的trace的性质。 第五步的话,我们令A的转置=θ;B=X和它转置的积;C=I。 最后,我们令J(θ)的导数=0,这样θ的取值就代表了J(θ)的最小值。 所以,使用矩阵表示损失函数最小值的最终公式变为: 
我们使用矩阵的目的是为了让我们的运算更简单易懂,我们推导出矩阵表示表达时的θ求值函数以后,只需要对样本参数做4次矩阵运算就可以求出特征矩阵,而不是像上面那样用好几个for循环。 |


