
想要连贯学习本内容请阅读之前文章:
【原创】AIGC之 ChatGPT 高级使用技巧
【原创】AIGC之主流产品介绍
AIGC是什么
AIGC - AI Generated Content (AI生成内容),对应我们的过去的主要是 UGC(User Generated Content)和 PGC(Professional user Generated Content)。
AIGC就是说所有输出内容是通过AI机器人来生成产出相关内容,主要区别是过去主要是普通用户和某一领域专业用户(人)生产内容,AIGC主要是依赖于人工智能(非人类)生成内容,这个就是AIGC的核心意思。
(版权认定:UGC和PGC是有版权概念的,版权归属于负责生成内容的人,AIGC目前美国法规认为是没有版权概念的,就是内容不属于调用的人,也不属于这个AI机器,所以没有版权归属这件事。)
AIGC可以生成什么内容
目前AIGC主要可以生成文本内容和图片内容(目前视频生成有一些产品,但是没有文本和图片生成这么成熟),所以我们主要集中在文本和图片的AIGC的介绍。
AIGC在文本内容方面,主要可以通过 Q&A (提问回答)得形式进行互动,能够按照人类想要的“提问”生产输出符合人类预期的内容。
一般我们可以把AI当做一个全知全能的“高级人类”,以“文本AIGC”来抡,你可以向它提出问题(Prompt),然后它做出相应回答。所有提问和回答都可以涉及到方方面面,包括不限于 百科知识/创意文案/小说剧本/代码编程/翻译转换/论文编写/教育教学/指导建议/聊天陪伴 等等等等场景不一而足,场景都需要你去想,可以理解它是一个拥有全地球知识的“百晓生”,什么都可以问它或者跟它交流。
比如我们用大名鼎鼎的 ChatGPT 来进行提问:
对于“图片AIGC”来说,你可能脑子里有无数创意,但是自己不会绘画,无法把脑子里的Idea变成实实在在的图片,那么,“图片AIGC”能够帮助你按照你脑子想要的东西,你告诉它,然后它能够帮助你通过图片绘画的形式给你画出来,让你一下子把自己的“创意”变成了图片现实。
比如我们用非常好用的“图片AIGC” 工具 Midjourney 来画画:

AIGC基本工作原理
AIGC底层主要依赖的是AI技术,AI技术本质主要是让机器拥有像人类一样的智能(Artificial Intelligence),所以就需要让机器能够像人类一些学习和思考,所以目前大部分实现AI的底层技术叫做“机器学习”(Machine Learnin)技术。
机器学习技术主要有很多应用场景,比如现在非常常用的包括 人脸识别(手机解锁/支付宝支付/门禁解锁等)、语音识别(小爱同学/小度/Siri)、美颜换脸(主播美颜/美颜相机)、地图导航、气象预测、搜索引擎、NLP(自然语言处理)、自动驾驶、机器人控制、AIGC 等等。
机器如何进行学习
机器学习可以简单理解为是模拟人类学习的过程,我们来看一下机器是如何模拟人类学习的。

我们再看看所谓的“机器学习”:

对于人类学习来说,我们看到的事物和遇到的事物就是我们的“资料”(语料),然后我们通过“学习总结归纳”(学习算法),最后变成了“知识经验智慧”(模型),然后遇到事情的时候我们就会调用这些“知识经验方法论”做出相应的反应决策动作(预测推理);
对于机器学习来说,给它输入大量的“语料”(看到遇到的事物),然后通过机器学习算法(总结归纳抽取相似点),最后形成了“模型”(知识经验方法论),然后再遇到一些需要判断决策的时候,我们就会把要判断决策的事物给“模型”,然后就会告诉我们输出结果(推理推测结果);
从抽象层来说,我们会发现,本质来说,“人类学习”和“机器学习”内在本质是比较像的。
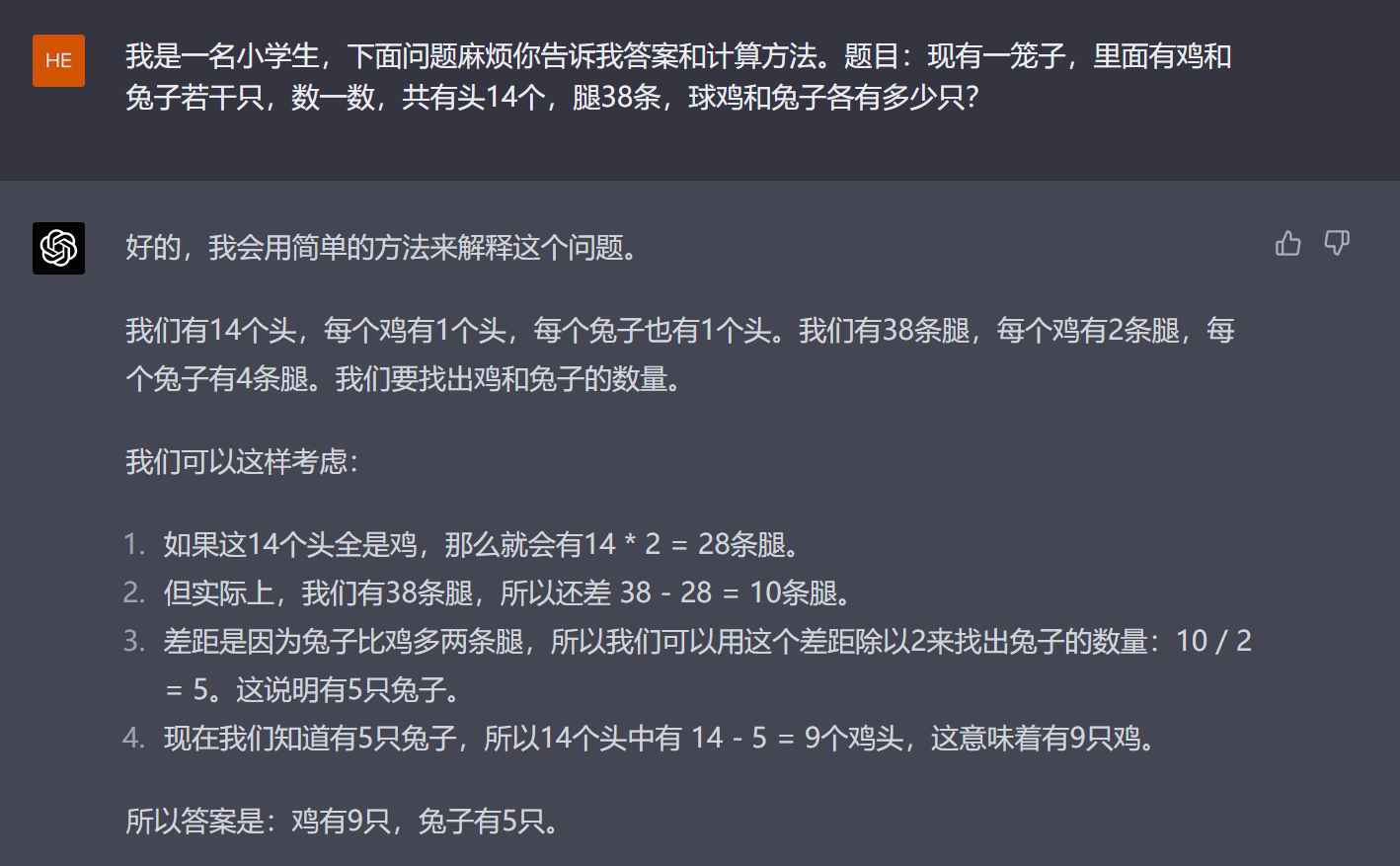
我们来看一个计算机里概要的机器学习的过程:
里面核心步骤就是:“训练数据 ➜ 训练算法 ➜ 模型 ➜ 预测 ➜ 输出结果”,其中最终产出物是“模型”(Model,模型文件),然后主要是前置的“训练模型”和后置的“模型预测”,然后产生对应结果。
上面这个过程我们可以简单理解为:“模型”就是一只小狗,饲养员就是那个“训练算法”,饲养员在场下对那个小狗通过一些指令和奖惩措施进行反复训练(训练算法),小狗就会学会一些技能(模型),一旦学会了,小狗就可以出去表演,表演的过程就是预测。
所以我们会看到,里面如果“模型”中的特征(知识经验)越多,最终在“预测”阶段就越准确,如果模型越小,或者中间的特征数据越少,可能最终预测结果准确率会降低。(类似一个人遇到的事情越多,总结的经验就越多,俗话说的“人生没有白走的路没有白踩的坑” 大概就是这个逻辑)
机器学习的发展
机器学习技术主要经历了从兴起到深度学习三个大技术时代,第一个是兴起时代,然后是传统的机器学习时代,最后是基于神经网络的深度学习时代,以下简单按照我个人理解做了一个发展阶段分类。
兴起阶段:1943年诞生了感知机模型(MCP),一位心理学家和一位数理逻辑学家 提出了人工神经网络的概念和人工神经元的数学模型,算开创了人工神经网络得研究时代。然后从60年代到80年代之间,有了机器学习概念和模式识别等,属于整个研究的兴起探索阶段,这个阶段各种方向的探索都在进行,百花齐放。
第一阶段:传统机器学习(Machine Learnin),从1980年召开第一届技术学习研讨会开始,虽然同步也有神经网络得研究,但是可以简单理解为大行其道的主要是基于数学和统计分析为主的方式得机器学习,特别是在1990年到2001年之间,从理论到实践都经过了很大的发展。这个时间段一直到2006年,在信息行业主要流行的传统机器学习包括 传统隐马尔可夫模型(HMM)、条件随机场(CRFs)、最大熵模型(MaxEnt)、Bboosting、支持向量机(SVM)、贝叶斯(Bayes)等等,具体实践中落地包括 线性回归、逻辑回归、SVM、决策树、随机森林、朴素贝叶斯 等等落地的算法。这些算法的因果逻辑和中间计算过程都是清晰明确的,基本是清晰可信的,不足就是最终效果有上限,可能最终“智能”效果有时候就不够。
第二阶段 V1:“深度学习”(Deep Learnin),2006年机器学习教父级人物Hinton发表了深层神经网络的论文正式开启了基于神经网络得“深度学习”的阶段,可以简单认为“深度学习”是传统机器学习的另外一条路线,它主要区别是在“学习策略”方面的路线不同,传统机器学习主要是依赖于“数学统计分析”为主的方法,过程结果可推导;深度学习主要是也依赖于让计算机模拟人脑一样神经网络连接一样的方式进行运算。
第二阶段 V2:Transformer 模型(Transformer model),2015年提出了Attention机制,2017年Google发表了论文《Attention Is All You Need》在此基础之上提出了Transformer架构,它基于encoder-decoder架构,抛弃了传统的RNN、CNN模型,仅由Attention机制(注意力机制)实现,并且由于encoder端是并行计算的,训练时间大大缩短。Transformer模型广泛应用于NLP领域,机器翻译、文本摘要、问答系统等等,最近几年比较主流的Bert和GPT模型就是基于Transformer模型构建的。
我们看一下深度学习基本的发展历史:

机器学习和深度学习的区别
常规的机器学习一般我们会叫做“传统机器学习”或者是“浅层机器学习”,主要是为了对应“深度学习”这个概念。深度学习与传统机器学习不太一样,所以它主要是用来定义不同网络框架参数层的神经网络,所以主有很多神经网络结构,包括 无监督预训练网络(Unsupervised Pre-trained Networks)、卷积神经网络(Convolutional Neural Networks)、循环神经网络(Recurrent Neural Networks)、递归神经网络 (Recursive Neural Networks)等等;
神经网络叫做“深度学习”主要是看里面所谓神经网络的层数,1-2层叫做浅层神经网络,超过5层叫做深层神经网络,又叫做深度学习”。
其中,应用比较多的主要 卷积网络(CNN - Convolutional Neural Networks)、循环神经网络(RNN - Recurrent Neural Networks)+递归神经网络(RNN - Recursive Neural Networks)、长短期记忆RNN(LSTM - Long short-term memory) 和为了解决 LSTM/RNN 中的一些问题的解决办法加入Attention机制的Transformer框架。
深度学习在计算机视觉(CV、如图像识别)、自然语言处理(NLP)、自动驾驶、机器人控制 等方面比传统机器学习效果更好。
在训练数据规模比较小的情况下,传统机器学习型算法表现还可以,但是数据增加了,传统机器学习效果没有增加,会有一个临界点;但是对于深度学习来说,数据越多,效果越好。所以也是越来越逐步“深度学习”取代“传统机器学习”的过程了。
传统机器学习和深度学习的效果性能对比图:
传统机器学习和深度学习的处理过程区别:(传统机器学习特征是清晰的,深度学习内部特征是黑盒)

深度学习中使用的神经网络,大概的工作机制是模拟人类的脑子工作机制,比如我们通过眼睛看到一个物体的过程:

我们再看看基于神经网络得“深度学习” 进行学习的过程:

从上面神经网络工作过程我们可以看出,基于神经网络的“深度学习”整个过程基本跟传统机器学习是完全不同的。
还有一个区别就是传统机器学习在训练的时候,基本可以使用传统CPU运算就可以了,但是在深度学习方面,因为神经网络层数多,计算量大,一般都需要使用 GPU或AI计算芯片(AI卡)进行运算才行,这个也就是我们常说的“算力”。
深度学习在大规模数据计算方面算力消耗成本惊人,以ChatGPT为例,传闻大概运算花费了英伟达(NVIDIA)的A100型号GPU一万张,目前京东A100的卡销售价格大约为人民币10万元,ChatGPT大概训练算力成本粗略预估为10亿人民币,对于ChatGPT公布的数据来看,一次大模型的训练大约需要1200万美元,所以除了比拼算法,算力更是很重要的决定性因素。
神经网络的分类
基于上面深度学习的逻辑,我们宏观看一下深度学习的神经网络包括哪些:

深度学习我们可以理解为:分类方式主要是基于“机器学习策略”是“神经网络”的策略,“学习方式”主要是 监督学习、无监督学习(也可能包含强化学习)等不同场景结合产生的“机器学习”方式叫做“深度学习”。
本文概要学习了AIGC和机器学习的基本概念,有个基本认识了解,方便其他依赖于机器学习和深度学习的人工智能(AI)的各种应用和原理的理解。
取代你的不是AI,而是比你更了解AI和更会使用AI的人!
##End##
想关注更多技术信息,可以关注"黑夜路人技术” 公众号