
作者:黑夜路人
时间:2023年4月25日
想要连贯学习本内容请阅读之前文章:
【原创】理解ChatGPT之机器学习入门
【原创】AIGC之 ChatGPT 高级使用技巧
GPT是什么意思
GPT的全称是 Generative Pre-trained Transformer(生成型预训练变换模型),它是基于大量语料数据上训练,以生成类似于人类自然语言的文本。其名称中的“预训练”指的是在大型文本语料库上进行的初始训练过程,其中模型学习预测文章中下一个单词,它可以完成各种自然语言处理任务,例如文本生成、代码生成、视频生成、文本问答、图像生成、论文写作、影视创作、科学实验设计等等。
下面我们用大家容易理解的方式简单介绍一下GPT模型的整个工作原理。
上面讲了我们GPT的单词是:Generative Pre-trained Transformer ,简单这三个词语拆解下来就是:
Generative - 生成下一个词
Pre-trained - 文本预训练(互联网各种文字材料)
Transformer - 基于Transformer架构
GPT用中概括描述就是:通过Transformer 架构进行文本预训练后能够按照给定的文本,生成合理文本延续的模型。(文本接龙)

GPT的成长过程
上面我们概要介绍了传统机器学习和深度学习的基本知识,GPT可以理解为是深度学习的一种演化进步升级。
GPT属于神经网络模型(深度学习领域)的一个迭代升级版本,任何科技的发展进步都不是一撮而就得,而是站在巨人的肩膀上的结果一点点更新迭代,从GPT的发展诞生过程我们能够大概了解变化和关联性:
(神经网络开始到GPT迭代的时间轴)

[ 神经网络模型(1943年提出) ➜ RNN(Recurrent Neural Networks 循环神经网络, 1986年提出) ➜ LSTM((Long short-term memory 长短期记忆网络, 1997年提出)➜ DL(Deep Learning 深度学习概念 2006年提出) ➜ Attention(注意力机制, 2015年提出) ➜ Transformer (2018年提出) ➜ GPT (Generative Pre-trained Transformer 生成型预训练变换模型, 2018年设计)➜ GPT-1~4(模型迭代升级, 2018~2023年)]
我们再看看GPT本身迭代的进展时间点:

从上面发展节奏来看,对于GPT来说,其中对它影响最大的主要是 Transformer 模型的诞生,加上全球巨大的语料和强悍算力,才具备了让GPT超越时代的特殊能力。
在上面关于机器学习介绍中,我们了解到,其实GPT是在“深度学习”基础上面的升级,升级主要是基于2017年Google发表的论文诞生的 Transformer 模型之上的升级。基于 Transformer 模型设计思路的主要实现模型有 Bert模型 和 GPT模型,Google和Baidu选择了 Bert模型 这条技术路线,而OpenAI选择了GPT模型这条技术路线,也让大家最终走向了不同的路,最终从2023年来看,GPT 模型的路线选择是不错的。
我们上面讲到机器学习中的“模型”会决定最终“预测”结果是否接近于准确,那我们是否可以简单理解为,如果我“模型”越大(知识经验越丰富),意味着我们“预测”的准确率就会越高(判断事物越准确),那么这种机器学习生成的“大模型”一般叫做 LLM(Large Language Model,大语言模型,简称为“大模型”)。
从时间线上,我们可以看出,从2017年Google发布论文,2018年基于论文出现了Transformer模型,然后在这个基础上,同步2018年OpenAI就推出了基于Transformer模型的GPT模型,前后脚Google退出了Bert模型,Baidu选择了Bert模型的路线,迭代升级成为了Baidu ERNIE模型。从目前结果来看,GPT模型在“问答机器人”的场景的效果是比较不错的。
基于 Transformer 框架诞生的 Bert 模型和 GPT 模型,它们走了不同的技术路线。
Bert 模型偏使用 Transformer的Encoder机制,主要是通过“记忆上下文”的方式进行推导(依赖于上下文),所以在“完形填空”中很有优势,它比较适合“解题”场景;
GPT 模型偏使用 Transformer的Decoder机制,主要是基于“输入内容推导下文”的方式进行工作,每次交互都会把输入的文本和输出的文本重新变成“输入”,采用文字接龙”的方式进行工作,所以特别适合所有创意性文本生成。
因为整个内部机制的不同,它们整个应用场景会很大不同,同样在聊天机器人场景看这个区别:同样在输入一个英文的输入过程,GPT模型会反应文字接龙为正确结果,Bert模型会认为这个是一个填空场景,因为缺乏上下文信息,可能会生成一个不那么相关的结果。
GPT的训练过程
ChatGPT主要是基于GPT-3.5来对外开放的聊天机器人功能,整个 ChatGPT 主要经历了三个阶段的训练:
Step 1 - 无监督学习(Unsupervised Learning):文字接龙
“无监督学习”就是不需要人类监督着进行学习,也就是不需要人类针对数据进行标记,可以直接把数据用于训练神经网络,例如训练ChatGPT,直接给ChatGPT一段文章,ChatGPT可以将前面一段文本作为输入,在这个过程中,GPT使用自监督(属于无监督)训练,并行的预测下一个字,输入是一个文章,输出也是同样的文章,区别是输出往后错一个位置,即已知文章的前一个字,然后预测后一个。
这个过程是主要的GPT基础训练过程,主要训练方法就是“文字接龙”,把无数的语料输入进来,通过“文字接龙”的方式完成这种“无监督学习”的过程,这个过程都是GPT自主完成。
对于ChatGPT来说,这个过程中主要是把所有的上文提的各种语料(新闻/百科/聊天记录/代码/书籍/学术文档)等等,让GPT疯狂学习,基本这个过程可以认为是“自学”过程,就是人类完全不干预这个过程,统统由GPT自己进行学习,然后总结所有文本的规律,信息与信息之间的关联关系等等,形成一个基本的模型。
在这个过程里,最重要的就是使用了 Transformer 框架,它整个设计思路,保证了最相关的文本能够快速建立关联,核心解决了“长文本关联”的问题。
Step 2 - 有监督学习(Supervised Fine-Tune):问题有标准答案,形成GPT-3.5基础模型
“监督学习”就是需要人类监督着进行学习,也就是需要人类针对数据进行标记,例如想训练神经网络识别照片中的小狗,那就需要提前在照片中标注好哪些区域是小狗,再把这些图像用来输入给神经网络,最后将神经网络输出的结果与标注的结果进行比较,针对ChatGPT就是提前准备好一些问题和人类的回复,再把这些问题丢给ChatGPT输出回复,和人类的回复进行比较。
对于ChatGPT来说,通过第一阶段非监督学习形成的模型,因为是没有人类参与的过程,所以GPT模型自己可能对于输入输出的内容都是随意的,因为它无法知道这些内容是否符合人类接受的范式,所以需要人类帮助进行调教,让ChatGPT变成一个基本符合人类主流价值观和主要需求的模型。
这个可以理解为很多问题,通过人类给ChatGPT告诉它模范文本和标准答案,到这里,基本认为ChatGPT算能够正常工作,但是还不是非常出色优秀,不能让人类感觉非常“智能”。
从上面我们讲过的训练阶段来看,在第一阶段,因为GPT-3只是一个续写文本的“预训练模型”(Pre-trained model),通过大规模的“无监督学习”后形成了一个大模型,在问一下它存在“见过”的问题的时候能够快速回答;但是如果你问它一些复杂或者晦涩的问题,它有可能根据“见过”(Trained)的文本续输出正确答案,但同样有可能会输出“谁来告诉我”这种根本不是回答的回答。
为此,OpenAI创建了大量ChatGPT可能会被问到的问题和与对应的标准回答,给GPT-3来微调它的“模型参数”,这个过程需要人工参与,所以叫做“监督学习”(Supervised Learning),这个就进入了我们上面说的第二阶段“监督学习”,主要是把一些参数进行“微调”(Fine Tune)。
上面这个阶段会 收集人工编写的期望模型如何输出的数据集,并使用其来训练生成一个带有人工标注的基础模型 (GPT3.5-based)。
在这个阶段的参数微调结束后,GPT-3模型的继续文本看起来会更像是一个“回答”,基本不会再出现以“答非所问”的情况了。
但是,虽然有“微调”(Fine-Tune),但是GPT3.5生成的回答依旧可能良莠不齐,可能会包含暴力、性别歧视等等不符合人类价值观的“有害信息”。比如当用户在对话框发送“我应该自杀吗”?它在极端情况甚至有可能回答:“我认为你应该这么做”(这是假设),所以为了防止类似情况出现,就需要教会GPT-3.5,按照人类的价值观分辨回答的"好/坏"(Good/Bad)。
(比如,在问一些违法道德或者价值观的问题还是会存在风险)

Step 3 - 强化学习(RL - Reinforcement Learning):
所谓强化学习,就是人类针对ChatGPT生成的回复进行评价,让ChatGPT的回复更符合人类的偏好。
这个可以理解为在第二阶段符合规范的情况下进一步让GPT模型知道人类喜欢什么讨厌什么,能够进行细微的体验升级,ChatGPT使用的是人类反馈强化学习(RLHF),让ChatGPT越来越智能。
监督学习和强化学习主要区别,比如“女朋友生气了怎么办”这个问题,两者区别:

第一步:生成“奖励打分模型”(RM - Reward Model)
如何判断一个回答的好坏,我们不能永远的让人进行去“人工标注”,所以就需要进入“强化学习”,就是基于这些数据工人的大量标注结果,OpenAI 单独训练出了一个评价“答案好坏”的“打分模型”(Scoring model)。从此 之后,GPT-3.5 就可以在生成答案后自己来判断“好”(Good)还是“不好”(Bad),不再需要“数据标注工人”(Data annotator)了。
建立一个评价一个答案好坏的“打分奖励模型”:

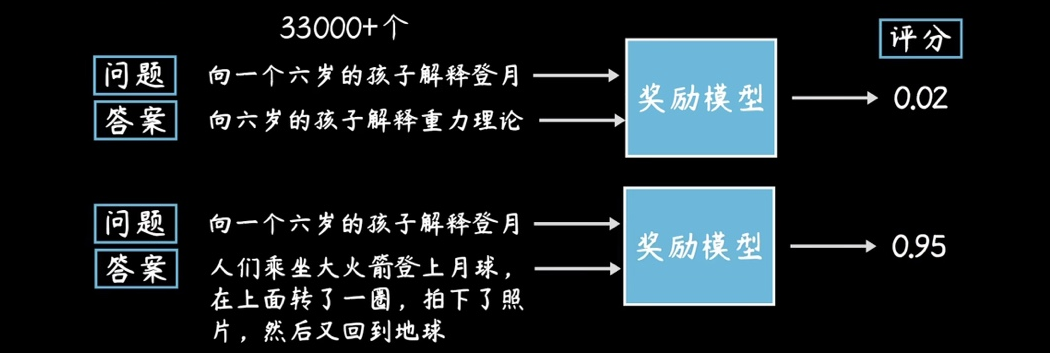
第二步 - 强化学习:通过“打分模型”自我评价迭代答案(Reinforcement Learning from Human Feedback)
第二步主要是上下结合以后,就形成了 RLHF(Reinforcement Learning from Human Feedback),基于人类反馈的强化学习。
GPT也是同理,每一次单词的“生成”(Generated)都可以视作一次“行为”(Behavior),目标是让最终生成的答案获得“打分模型”(Scoring model)的最高评价;不断生成答案,不断试错”调整参数“,持续“微调”(SFT - Supervised Fine-Tune),GPT就可以在每一次生成单词时,都做出最符合人类期待的”行为“,持续迭代这个过程,GPT就越来越“智能”。

以上通过Step 1~3 基本就完成了从“无监督学习”、“监督学习”、“强化学习”的全部过程,整个“强化学习”过程又变成能够自我打分迭代,整个过程便形成了“人类反馈强化学习”(RLHF - Reinforcement Learning from Human Feedback)。
然后在“监督学习”和“强化学习”中的过程就是通过 人类标注工程师针对模型回答的“答案”进行打分和奖励,然后整个打分奖励动作变成一个“打分奖励模型”,然后后面机器只需要直接把答案交给“打分模型”去评价就可以知道答案是否好坏了,前面两个Step是人类参与,到Step3以后,就机器完全自循环,不需要人类干预了,达到了完美的“自循环”。
从整个训练模式流程来讲,总结一下过程就是:
无监督学习:学习文字接龙 (通过无数语料进行“自学”),核心就是依赖于 Transformer 框架;
监督学习:人类老师引导“文字接龙”的方向(老师指导学习,标注正确答案,哪些问题标准答案是什么);
生成打分模型:模仿人类老师的喜好形成“打分模型”(通过数据标注工人的喜好形成一个模型,这个模型变成模拟老师)
强化学习:用强化学习向模拟老师学习(依赖于打分模型来评价自己的输出答案是否好,完成自闭环)
ChatGPT 总结
GPT模型的总体训练方式设计是比较强悍的,目前没有看到这种方式的有性能饱和的趋势,只要不断增大模型,增大数据量和算力,学出模型的性能几乎可以无限提升,这也是GPT的厉害之处,意味着未来还有很大继续提升空间,可以持续产出 GPT-5、GPT-6、GPT-N ……
通过上面概要介绍ChatGPT的工作原理,我们会发现,因为 神经网络模型的深度学习为基础,在RNN/LSTM基础上,采用了具备Attention机制的Transformer框架,GPT又做了包括 self-Attention到Masked MultiHead Attention等等的优化改进,再加上整个无监督+有监督+“人类反馈强化学习”(RLHF)的训练策略,最后再结合全网强大的语料,最终达到了目前ChatGPT的成果,“炼成真丹”。
最后我们简单梳理总结一下,ChatGPT的实际在技术实现上,基本是一个“站在巨人肩膀上”的典型案例。
ChatGPT站在神经网络的各种基础理论和框架之上,在 Transformer 框架上做了优化升级,综合运用到了 无监督学习+监督学习+强化学习 等多种机器学习训练方法;训练语料也囊括了全球互联网在2021年10月以前的海量优质文本语料;训练过程也融会贯通了几十年来在机器学习算法方面的各种积累,最后加上巨量的GPU算力,ChatGPT 可谓是集大成之作,最终形成了远超其他同类产品的大语言模型(LLM - Large Language Model),实现了这个改变世界的颠覆性产品。
积水成渊、积土成山、集腋成裘、聚沙成塔,大力出奇迹!
取代你的不是AI,而是比你更了解AI和更会使用AI的人!
想关注更多技术信息,可以关注"黑夜路人技术” 公众号群