【知识蒸馏】什么是知识蒸馏、方法解读
文章目录
1. 前言
1.1 由来
科学理论只有进行实践才能转化成产品,我们往往更看重知识转化为经济效益。轻量化网络就是将我们模型能够在现有的有限硬件条件下实现落地。
- 假如你用深度学习模型在服务器上达到了很好的预测效果,实际上是很多网络(Resnet,Vgg等)需要的计算量和计算资源很大,这对硬件的要求很高
- 然而,你可能只有一个1050(悲
- 在应用服务上,我们很容易见到这些智能产品,要直接把模型算法部署到这些小的设备上是困难的
- 于是,我们希望从一个大的模型上得到知识转移给小的模型,而小模型能达到跟大模型相当的效果,因此 知识蒸馏 就诞生了。
1.2 定义
知识蒸馏:就是把一个大模型的知识迁移到小模型上,因为大模型虽然能达到较高的精度,但它的训练往往需要大量的资源和时间,小模型的训练需要的资源少,训练速度快,但它的精度往往不如大模型。显然,不是每个人都拥有足够的资源训练大模型,为了使用更少的资源、更快的速度,并且精度不能太差,不如让小模型Student学习大模型Teacher的知识,用更少的资源就能达到不错的精度。
1.3 可蒸馏(迁移)的知识
需要明确的是,教师网络或给定的预训练模型中包含哪些可迁移的知识?基于常见的深度学习任务,可迁移知识可以列举为:
- 中间层特征:浅层特征注重纹理细节,深层特征注重抽象语义;
- 任务相关知识:如分类概率分布,目标检测涉及的实例语义、位置回归信息等;
- 表征相关知识:强调特征表征能力的迁移,相对通用、任务无关(Task-agnostic);表征间相关性,如相似度、Relation等;
2. 蒸馏方法介绍
2.1 知识的种类、蒸馏的种类

2.2 “知识”的种类
2.2.1 基于响应的知识__Distilling the Knowledge in a Neural Network(提出 vanilla knowledge)
教师网络最后一层的输出,直接模仿教师最后的预测,该方法简单高效。
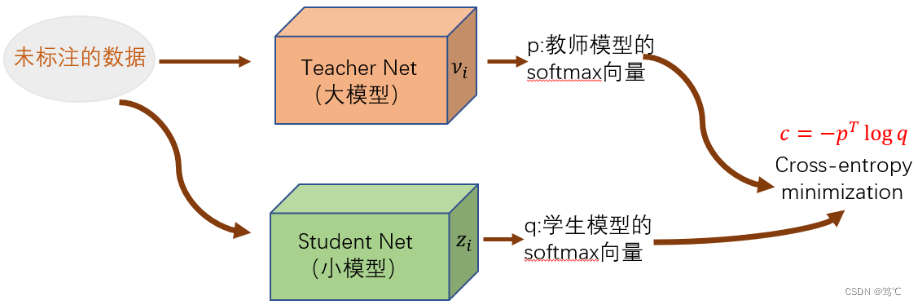
- Hinton的文章 “Distilling the Knowledge in a Neural Network” 首次提出了知识蒸馏(暗知识提取)的概念,通过引入与教师网络(Teacher network:复杂、但预测精度优越)相关的软目标(Soft-target)作为Total loss的一部分,以诱导学生网络(Student network:精简、低复杂度,更适合推理部署)的训练,实现知识迁移(Knowledge transfer)。
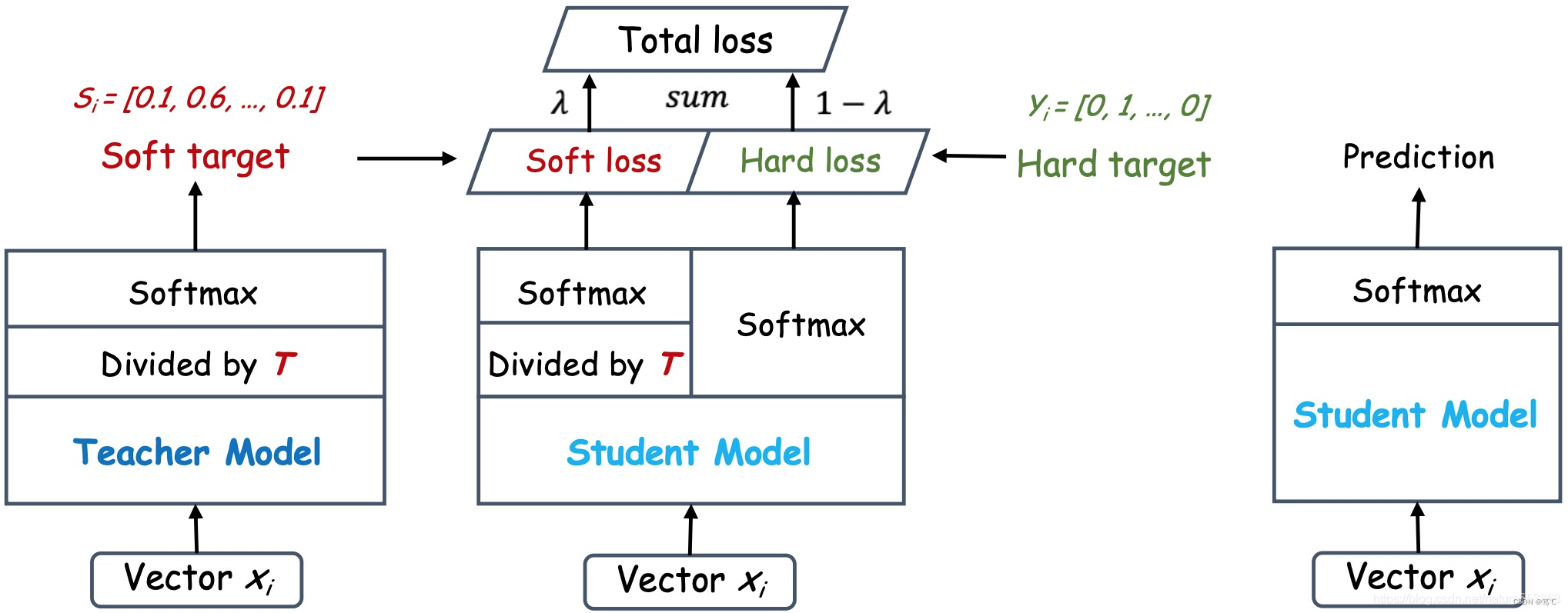
- 如上图所示,教师网络(左侧)的预测输出除以温度参数(Temperature)之后、再做Softmax计算,可以获得软化的概率分布(软目标或软标签),数值介于0~1之间,取值分布较为缓和。
- Temperature数值越大,分布越缓和;
- 而Temperature数值减小,容易放大错误分类的概率,引入不必要的噪声。
- 针对较困难的分类或检测任务,Temperature通常取1,确保教师网络中正确预测的贡献。
- 硬目标则是样本的真实标注,可以用One-hot矢量表示。
- Total loss设计为软目标与硬目标所对应的交叉熵的加权平均(表示为KD loss与CE loss),其中软目标交叉熵的加权系数越大,表明迁移诱导越依赖教师网络的贡献,这对训练初期阶段是很有必要的,有助于让学生网络更轻松的鉴别简单样本,但训练后期需要适当减小软目标的比重,让真实标注帮助鉴别困难样本。另外,教师网络的预测精度通常要优于学生网络,而模型容量则无具体限制,且教师网络推理精度越高,越有利于学生网络的学习。
联合训练:教师网络与学生网络也可以联合训练(对应论文)。
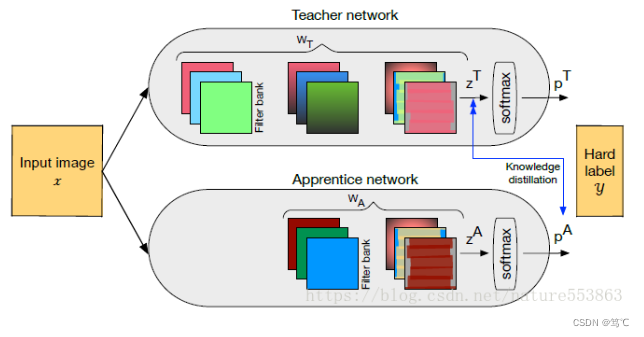
- 此时教师网络的暗知识及学习方式都会影响学生网络的学习,具体如下(式中三项分别为教师网络Softmax输出的交叉熵loss、学生网络Softmax输出的交叉熵loss、以及教师网络数值输出与学生网络Softmax输出的交叉熵loss):
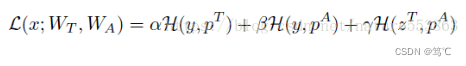
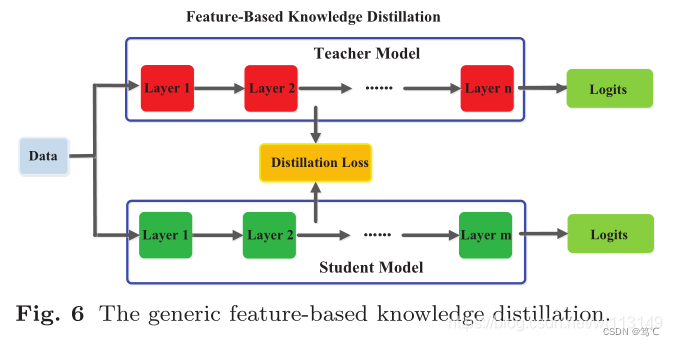
2.2.2 基于feature的知识
损失函数:
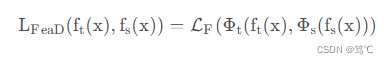
Φ t Φ_t Φt 表示如果教师和学生模型的feature map的shape不一样时,把shape变成一样。
L F L_F LF:相似性函数,用于匹配教师和学生模型的feature map;
问题:
扫描二维码关注公众号,回复:
14702107 查看本文章

- (1)怎么选择合适的hint层;
- (2)由于hint层和guided层的尺寸不一样,需要研究怎么去研究匹配两者之间的特征表征。
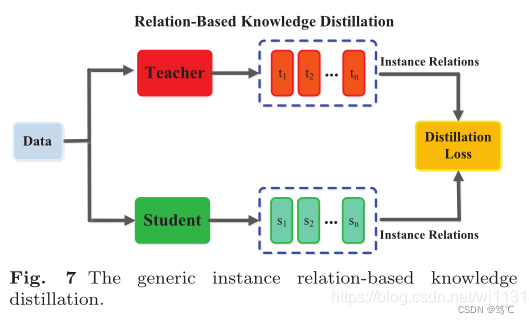
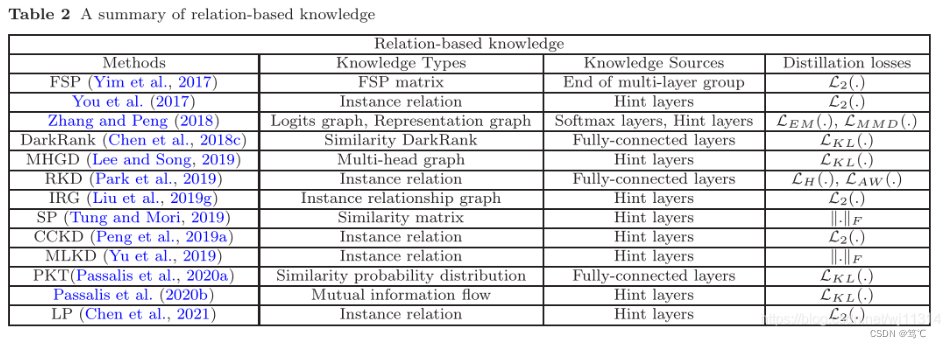
2.2.3 基于relation的知识
基于relation的知识:在不同层或者数据样本的关系。
- FSP 矩阵(Gram 矩阵):通过两个层之间的特征图做内积,总结特征图之间的关系,使用特征图之间的联系作为知识。(2017)
- 奇异值分解(SVD)KD用来提取键值信息
- 多教师网络的知识用每个教师模型的logits和feature作为节点做了两个图,通过logits和表征图作为KD的知识(Multi-head graph-based KD)
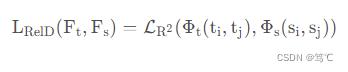
2.3 “蒸馏”的种类
根据学生是不是和教师网络同时更新可以分三种:离线蒸馏、在线蒸馏、自蒸馏。
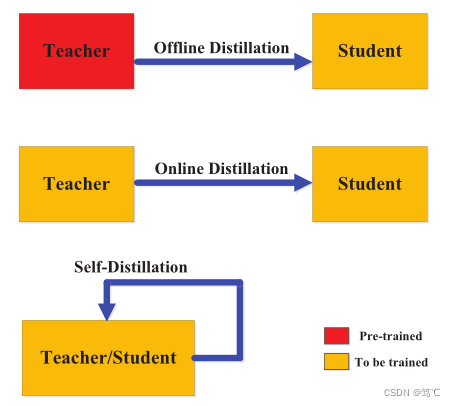
2.3.1 离线蒸馏
vanilla 蒸馏,两个步骤:
- 蒸馏前,在大数据集上预先训练好教师模型
- 蒸馏时,教师模型以logits或者中间features的形式提取知识,然后指导学生模型进行训练
- 方法
- 离线蒸馏方法通常采用单向知识转移和两阶段训练程序。
- 然而,复杂的大容量教师模型训练时间很长是无法避免的,而离线蒸馏的学生模型训练通常在教师模型的指导下是高效的。而且,大老师和小学生之间的能力差距一直存在,学生往往很大程度上依赖于老师。
2.3.2 在线蒸馏
在大容量高性能的教师模型不存在的时候,使用在线蒸馏可以提高学生网络性能。
- 方法
- 在线蒸馏是一种具有高效并行计算的单阶段端到端训练方案。
- 然而,现有的在线方法(例如,相互学习)通常不能解决在线设置中的高容量教师,使得进一步探索在线设置中教师和学生模型之间的关系成为有趣的话题。
2.3.3 自蒸馏
在自蒸馏中,教师和学生模型使用相同的网络。
- 方法:
- 从更深层蒸馏到更浅层
- 把自己层的注意力图作为蒸馏目标蒸馏到更低层
- 把前epoch得到的网络当作监督的训练过程转移到后面层,后面层模仿前一层
- 标签平滑正则化
3. 参考
【1】https://blog.csdn.net/wj113149/article/details/116142902
【2】https://blog.csdn.net/nature553863/article/details/80568658