项目简介
本项目根据个人需求进行北京二手房信息的数据分析,通过数据分析观察住房特征规律,利用机器学习模型进行简单的预测。
数据源
通过爬虫爬取第三方房屋中间商网站(链家和安居客)获取数据源,仅供学习使用。
目的
北京房价是最受关注的话题。因此,本项目以研究北京二手房房价为目的,对二手房房价进行数据分析。
统计北京各区域二手房房价情况
统计北京各区域二手房数量
统计西城区、东城区和海淀区各地方二手房房价
统计房价与房屋面积区段的房屋数量
技术和工具
本项目以Python语言编程完成数据分析。
数据分析:pandas,numpy,matplolib
1、 数据导入和清洗
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 导入链家二手房数据
lianjia_df = pd.read_csv('./lianjia.csv')
print(lianjia_df.head())
print('\n')
# 删除没用的列 ['Id', 'Direction', 'Elevator', 'Renovation'],为了与安居客数据合并
drop = ['Id', 'Direction', 'Elevator', 'Renovation']
lianjia_df_clean = lianjia_df.drop(drop, axis=1)
# 重新摆放列位置 ['Region', 'District', 'Garden', 'Layout', 'Floor', 'Year', 'Size', 'Price']
columns = ['Region', 'District', 'Garden', 'Layout', 'Floor', 'Year', 'Size', 'Price']
lianjia_df_clean = pd.DataFrame(lianjia_df_clean, columns=columns)
print(lianjia_df_clean.head())
print('\n')
# 计算Region列数据的总量
lianjia_total_num = lianjia_df_clean['Region'].count()
print(lianjia_total_num)
运行结果:

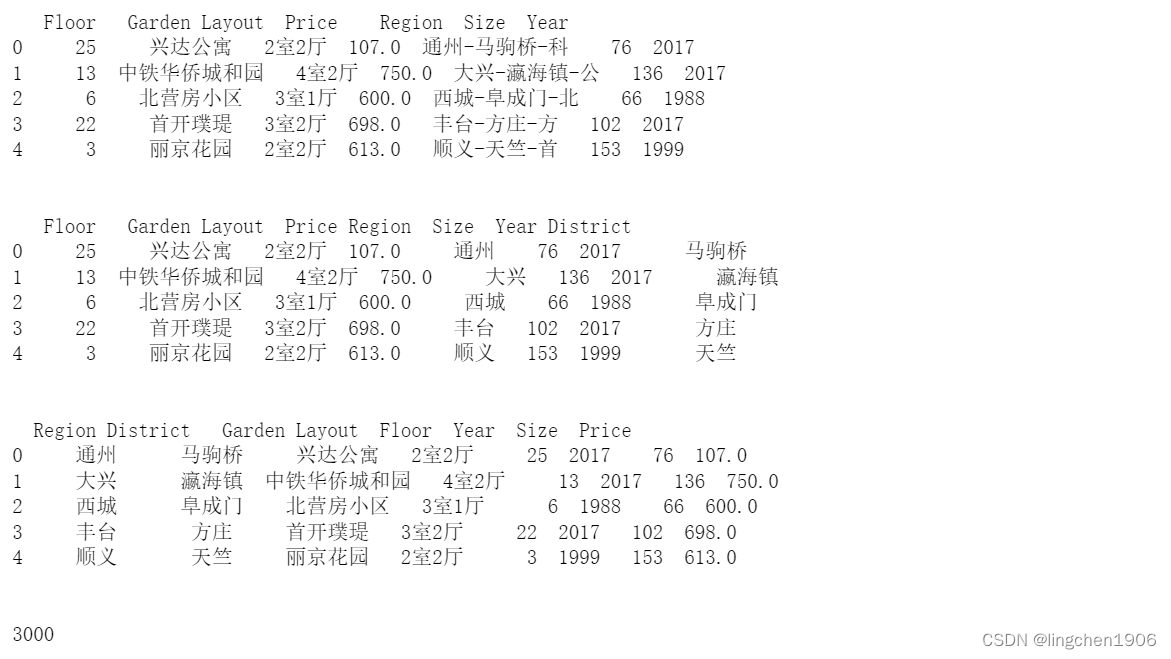
# 导入安居客二手房数据
anjuke_df = pd.read_csv('./anjuke.csv')
print(anjuke_df.head())
print('\n')
# 正则表达式
anjuke_df['District'] = anjuke_df['Region'].str.extract(r'.+?-(.+?)-.+?', expand= False)
anjuke_df['Region'] = anjuke_df['Region'].str.extract(r'(.+?)-.+?-.+?', expand= False)
print(anjuke_df.head())
print('\n')
#清洗数据,重新摆放列位置
columns = ['Region', 'District', 'Garden', 'Layout', 'Floor', 'Year', 'Size', 'Price']
anjuke_df = pd.DataFrame(anjuke_df, columns=columns)
print(anjuke_df.head())
print('\n')
#计算Region列数据的总量
anjuke_total_num = anjuke_df['Region'].count()
print(anjuke_total_num)
运行结果:
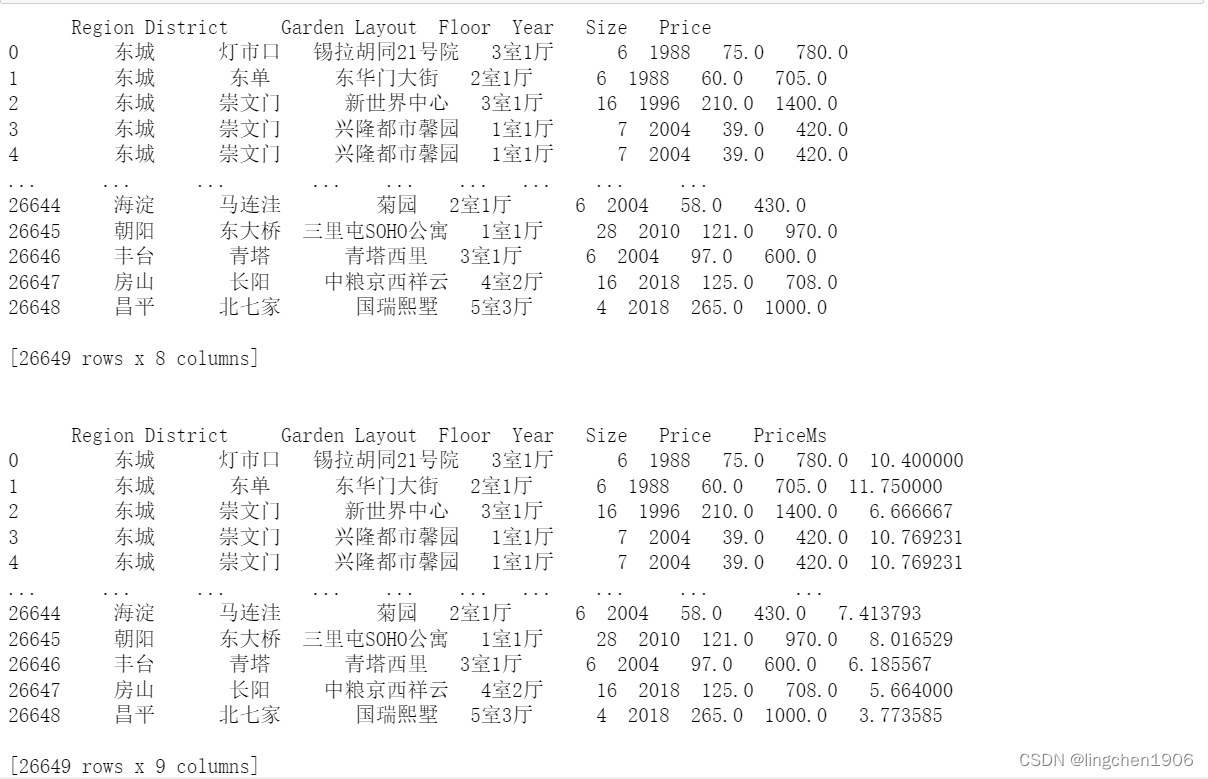
# 数据集合并:将链家数据集与安居客数据集合并
df = pd.merge(lianjia_df_clean, anjuke_df, how='outer')
print(df)
print('\n')
# 增加一列:每平方的价格
df['PriceMs'] = df['Price'] / df['Size']
print(df)
print('\n')
# 对汇总数据再次清洗 (Null, 重复)
df.dropna(how='any')
df.drop_duplicates(keep='first', inplace=True)
# 一些别墅的房屋单价有异常,删选价格大于25万一平的
df = df.loc[df['PriceMs']<25] # 保留25万以下的数据
total_num = anjuke_total_num + lianjia_total_num
df_num = df['Region'].count()
drop_num = total_num - df_num
print(total_num)
print(df_num)
print(drop_num)
运行结果:

2.数据可视化分析
北京各区域二手房房价均值对比 & 二手房数量对比
# 统计北京各区域二手房房价数量
df_house_count = df.groupby('Region')['Price'].count().sort_values(ascending=False)
print(df_house_count)
print('\n')
# 统计北京各区域二手每平方米房房价
df_house_mean = df.groupby('Region')['PriceMs'].mean().sort_values(ascending=False)
print(df_house_count)
运行结果:

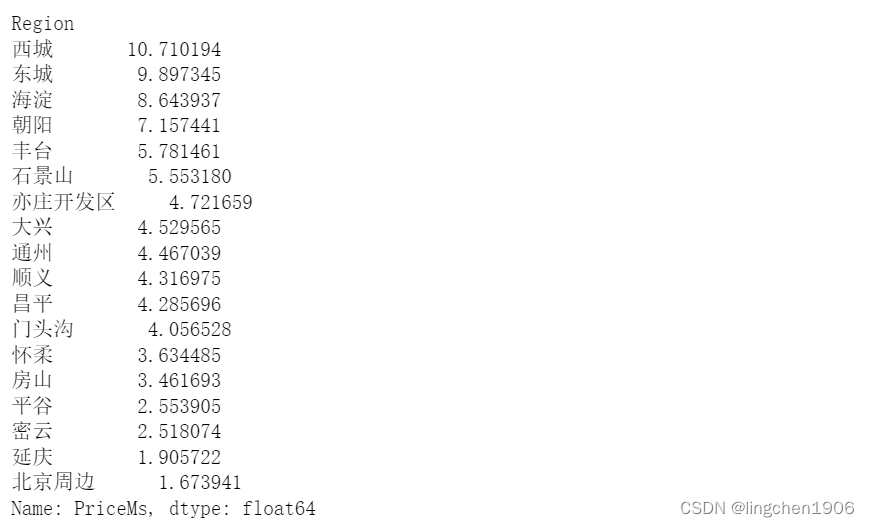
方案一:
plt.figure(figsize=(20,10))
plt.rc('font', family='SimHei', size=13)
plt.style.use('ggplot')
plt.subplot(211)
plt.title('各区域二手房平均价格的对比', fontsize = 20)
plt.ylabel('二手房平均价格 (万/平方米)', fontsize = 15)
bar1 = plt.bar(np.arange(len(df_house_mean.index)), df_house_mean.values, color='c')
plt.show()
运行结果:
由方案一可以看出,x轴上不是索引值,需要对其进行进一步的改进。
方案二:
在方案一的基础上改进。
先对方案一中得到得bar1进行循环便利打印:
for i in bar1:
print(i)
运行结果:

然后根据打印结果编写一个函数,将索引值添加到横轴:
def auto_x(bar, x_index):
x = []
for i in bar:
x.append(i.get_x() + i.get_width()/2)
x = tuple(x)
plt.xticks(x, x_index)
调用函数:
auto_x(bar1, df_house_mean.index)
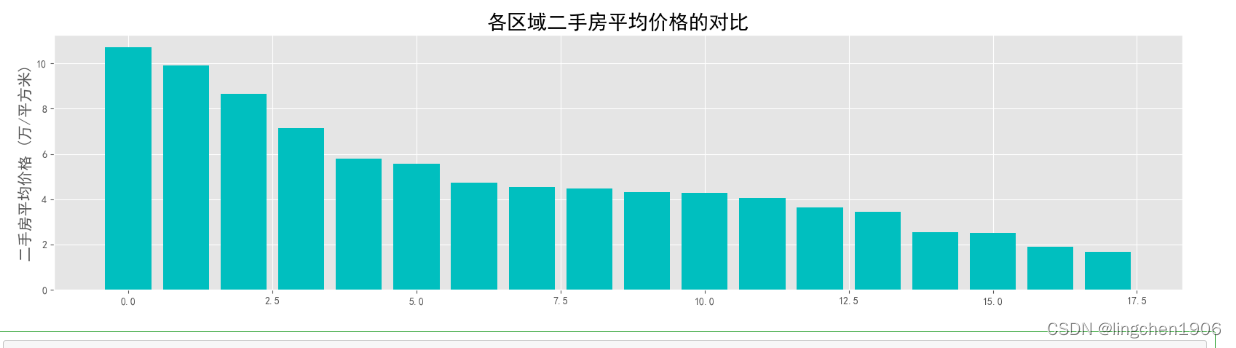
对方案一改进得最终结果:
def auto_x(bar, x_index):
x = []
for i in bar:
x.append(i.get_x() + i.get_width()/2)
x = tuple(x)
plt.xticks(x, x_index)
plt.figure(figsize=(20,10))
plt.rc('font', family='SimHei', size=13)
plt.style.use('ggplot')
plt.subplot(211)
plt.title('各区域二手房平均价格的对比', fontsize = 20)
plt.ylabel('二手房平均价格 (万/平方米)', fontsize = 15)
bar1 = plt.bar(np.arange(len(df_house_mean.index)), df_house_mean.values, color='c')
auto_x(bar1, df_house_mean.index)
plt.show()
运行结果:
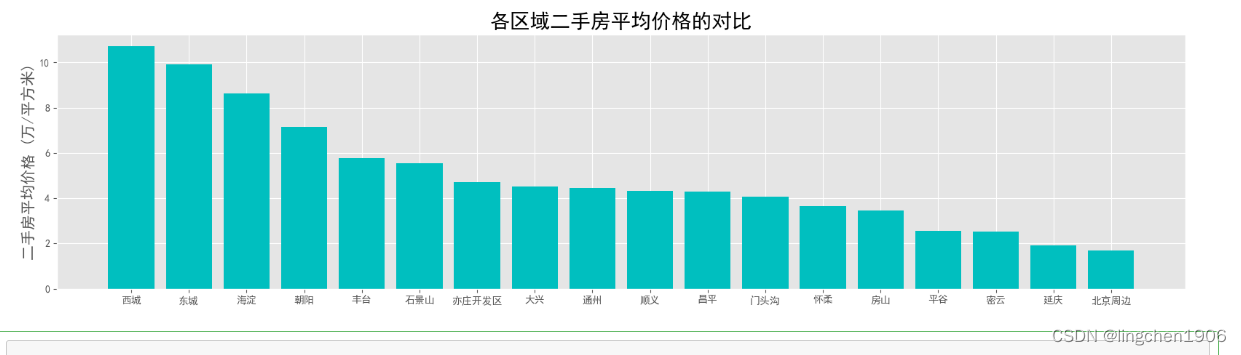
方案三:
方案二不是最优做法,方案三更为简洁。
# 各区域二手房平均价格对比 # plt.rc('font', family='SimHei', size=13) plt.style.use('ggplot')
plt.figure(figsize=(20,10))
plt.rc('font', family='SimHei', size=13)
plt.style.use('ggplot')
plt.subplot(211)
plt.title('各区域二手房平均价格的对比', fontsize = 20)
plt.ylabel('二手房平均价格 (万/平方米)', fontsize = 15)
bar1 = plt.bar(df_house_mean.index, df_house_mean.values, color='c')
plt.show()
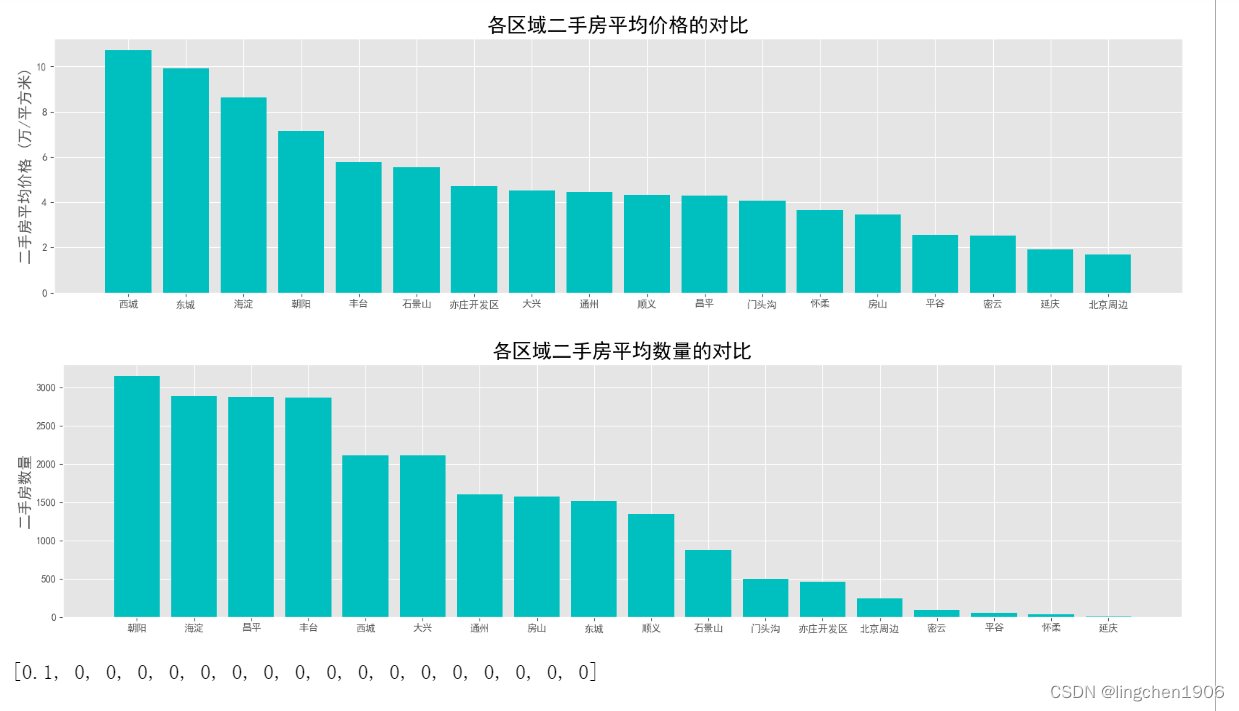
# 各区域二手房数量对比
plt.figure(figsize=(20,10))
plt.subplot(212)
plt.title('各区域二手房平均数量的对比', fontsize = 20)
plt.ylabel('二手房数量', fontsize = 15)
bar1 = plt.bar(df_house_count.index, df_house_count.values, color='c')
plt.show()
运行结果:
3、饼图可视化
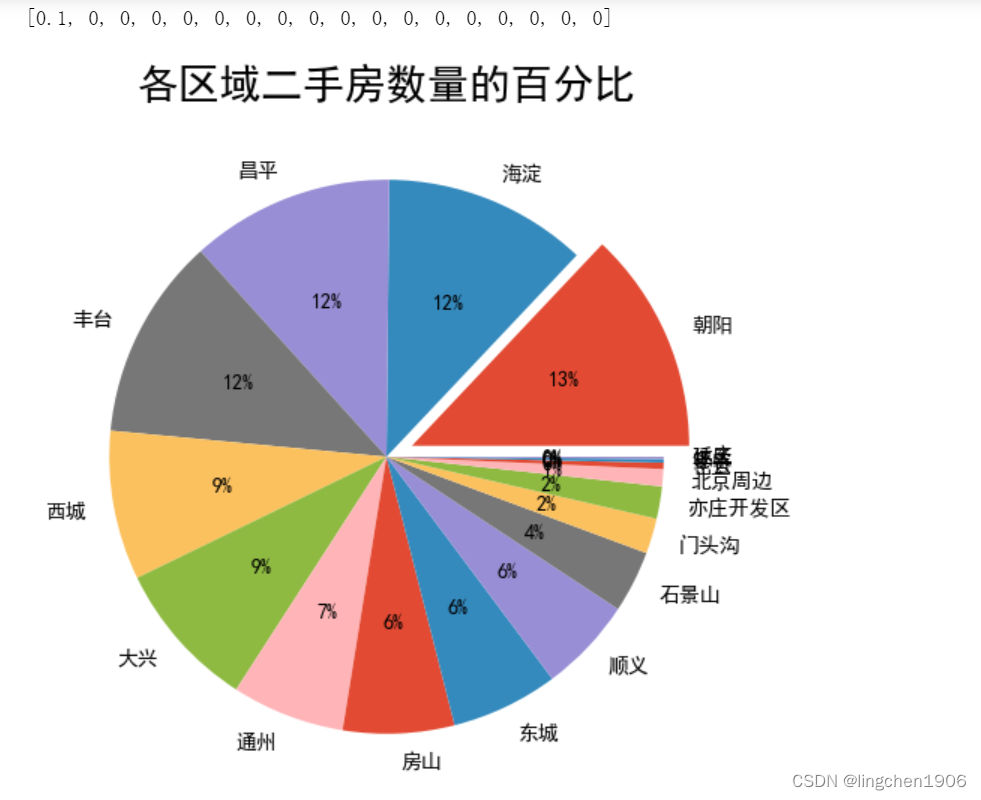
# 各区域二手房数量百分比
plt.figure(figsize=(6,6))
plt.title('各区域二手房数量的百分比', fontsize=20)
ex = [0]*len(df_house_count)
ex[0] = 0.1
print(ex)
plt.pie(df_house_count, radius=1, autopct='%1.f%%', labels = df_house_count.index, explode=ex )
plt.show()
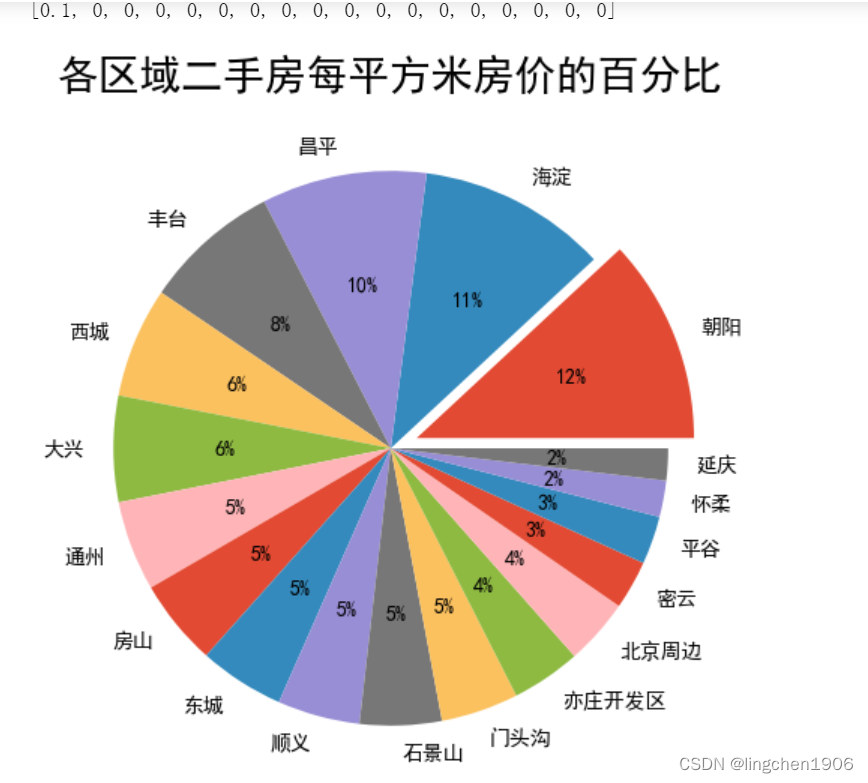
# 各区域二手房每平方米房价
plt.figure(figsize=(6,6))
plt.title('各区域二手房每平方米房价的百分比', fontsize=20)
ex = [0]*len(df_house_mean)
ex[0] = 0.1
print(ex)
plt.pie(df_house_mean, radius=1, autopct='%1.f%%', labels = df_house_count.index, explode=ex )
plt.show()
运行结果: