最近在学习用Python进行数据分析、机器学习,基本都是用现成数据集进行模型训练及验证,想用一些实际数据看一下效果,于是想到用Python尝试抓取一些实际数据。
目标:爬取链家网北京二手房房价、位置、面积等数据
环境:Python3.5.2,Anaconda4.2.0

1.准备工作
首先,导入所需要的库,主要有urllib.request、BeautifulSoup、Pandas、Numpy、re。
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import re
- urllib.request:打开和浏览url中内容。具体用法参见:https://docs.python.org/3/library/urllib.request.html#module-urllib.request
- BeautifulSoup:将html解析为对象进行处理,全部页面转变为字典或者数组,相对于正则表达式的方式,可以大大简化处理过程。具体用法参见:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- Pandas: Pandas 是python的一个数据分析包,提供了大量能使我们快速便捷地处理数据的函数和方法。 具体用法参见:https://pandas.pydata.org/
- Numpy:Numpy支持高级大量的维度数组与矩阵运算,针对数组运算提供大量的数学函数库。 具体用法参见:https://www.numpy.org/
- re:re是pyhton中实现正则表达式匹配操作的模块。具体用法参见:https://docs.python.org/3.5/library/re.html
2.抓取数据
首先,了解一下目标网站的URL结构,例如 https://bj.lianjia.com/ershoufang/dongcheng/pg2/
- bj表示城市,北京
- ershoufang是频道名称,二手房
- dongcheng是城区名称,东城区
- pg2是页面码,第二页

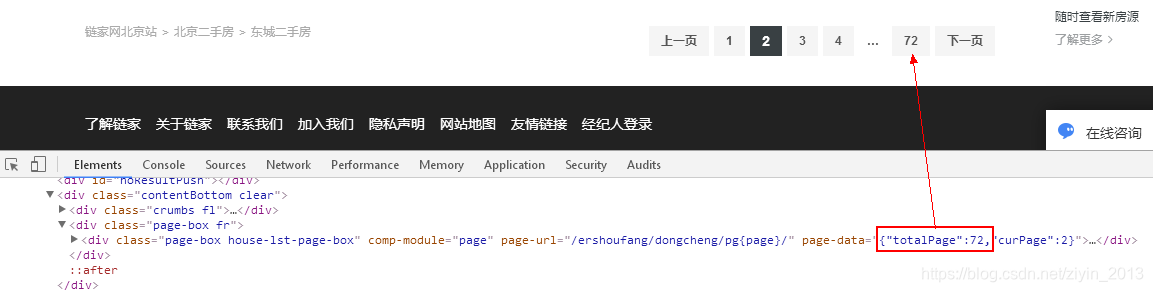
例如,我们要抓取北京各个区二手房频道,所以前面城市、频道名称不会变,属于固定部分;后面的城区要遍历北京各个区(东城、西城、朝阳…),页码需要在1-所选城区总页数间变化,属于可变部分。将URL分为两部分,前面的固定部分赋值给url,后面的可变部分用双层for循环遍历,外层循环遍历城区,内层循环遍历所选城区的页面。其中,需要获取所选城区包含的总页数,提取div标签中class=page-box fr的第一个子标签属性page-data的值。
chengqu={'dongcheng':'东城区','xicheng':'西城区','chaoyang':'朝阳区','haidian':'海淀区','fengtai':'丰台区','shijingshan':'石景山区', 'tongzhou':'通州区','changping':'昌平区','daxing':'大兴区','shunyi':'顺义区','fangshan':'房山区'}
for cq in chengqu.keys():
url='https://bj.lianjia.com/ershoufang/'+cq+'/' #组成所选城区的URL
html=urlopen(url)
bsObj=BeautifulSoup(html) #解析抓取的页面内容
total_page=re.sub('\D','',bsObj.find('div','page-box fr').contents[0].attrs['page-data'])[:-1] #获取所选城区总页数
print ('total_page',total_page)
for j in np.arange(1,int(total_page)+1):
page_url=url+'pg'+str(j) #组成所选城区页面的URL
然后,使用BeautifulSoup对页面进行解析。
page_html=urlopen(page_url)
page_bsObj=BeautifulSoup(page_html)
接着,提取页面中的关键信息进行提取,主要对房屋信息、房屋位置、总价和单价进行提取。

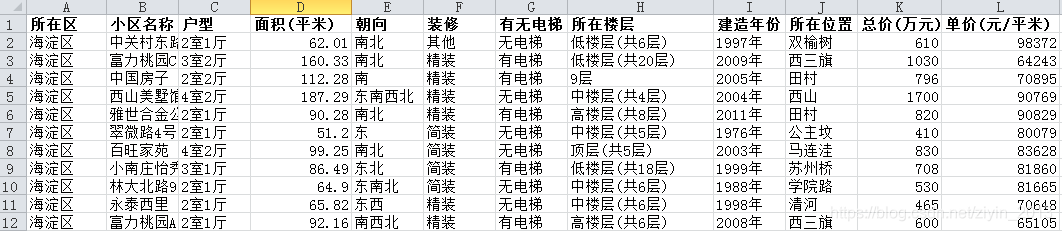
依次把页面div标签中class为houseInfo、positionInfo、totalPrice、unitPrice的部分提取出来,用get_text()获取对应标签中的信息,其中houseInfo、positionInfo包含房屋的多种属性,用split()对其进行分列,只选取了houseInfo包含6个属性且positionInfo包含3个属性的数据。另外,对于单价用get_text()后得到“单价100748元/平米”,包含了文本和数字,用re.sub()正则匹配出数字部分。最后,依次把提取到的信息添加到对应列表中。
info=bsObj.findAll("div",{"class":"houseInfo"})
position_info=bsObj.findAll("div",{"class":"positionInfo"})
totalprice=bsObj.findAll("div",{"class":"totalPrice"})
unitprice=bsObj.findAll("div",{"class":"unitPrice"})
house_loc=[] #房屋所在小区
house_type=[] #房屋户型
house_area=[] #房屋面积
house_direction=[] #房屋朝向
house_decorating=[] #房屋装修
house_lift=[] #有无电梯
house_floor=[] #房屋楼层
house_year=[] #建造年份
house_position=[] #房屋位置
t_price=[] #房屋总价
u_price=[] #房屋单价
for i_info,i_pinfo,i_tp,i_up in zip(info,position_info,totalprice,unitprice):
if len(i_info.get_text().split('/'))==6 and len(i_pinfo.get_text().split('/'))==3:
#分列houseinfo并依次获取房屋所在小区、户型、面积、朝向、装修、有无电梯各字段
house_loc.append(i_info.get_text().split('/')[0])
house_type.append(i_info.get_text().split('/')[1])
house_area.append(i_info.get_text().split('/')[2][:-2])
house_direction.append(i_info.get_text().split('/')[3].replace(' ',''))
house_decorating.append(i_info.get_text().split('/')[4])
house_lift.append(i_info.get_text().split('/')[5])
#分列positioninfo并依次获房屋楼层、建造年份、位置各字段
house_floor.append(i_pinfo.get_text().split('/')[0])
house_year.append(i_pinfo.get_text().split('/')[1][:5])
house_position.append(i_pinfo.get_text().split('/')[2])
#获取房屋总价和单价
t_price.append(i_tp.span.string)
u_price.append(re.sub('\D','',i_up.get_text()))
将提取的数据导入pandas之中生成数据表。
#将数据导入pandas之中生成数据表
house_data=pd.DataFrame()
house_data[u'城区']=[chengqu[cq]]*len(house_loc)
house_data[u'小区名称']=house_loc
house_data[u'房型']=house_type
house_data[u'面积']=house_area
house_data[u'朝向']=house_direction
house_data[u'装修']=house_decorating
house_data[u'有无电梯']=house_lift
house_data[u'楼层']=house_floor
house_data[u'建造年份']=house_year
house_data[u'位置']=house_position
house_data[u'总价']=t_price
house_data[u'单价']=u_price
print (house_data)
将数据存入到csv中,便于后续分析。
house_data.to_csv('house_bj.csv', mode='a', header=False,ecoding='gb2312',index=None)
总共提取到北京11个区28560条二手房信息。
最后,附上完整代码~~
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import re
chengqu={'dongcheng':'东城区','xicheng':'西城区','chaoyang':'朝阳区','haidian':'海淀区','fengtai':'丰台区','shijingshan':'石景山区',
'tongzhou':'通州区','changping':'昌平区','daxing':'大兴区','shunyi':'顺义区','fangshan':'房山区'}
for cq in chengqu.keys():
url='https://bj.lianjia.com/ershoufang/'+cq+'/' #组成所选城区的URL
html=urlopen(url)
bsObj=BeautifulSoup(html)
total_page=re.sub('\D','',bsObj.find('div','page-box fr').contents[0].attrs['page-data'])[:-1] #获取所选城区总页数
print ('total_page',total_page)
for j in np.arange(1,int(total_page)+1):
page_url=url+'pg'+str(j) #组成所选城区页面的URL
#print (page_url)
page_html=urlopen(page_url)
page_bsObj=BeautifulSoup(page_html)
info=bsObj.findAll("div",{"class":"houseInfo"})
position_info=bsObj.findAll("div",{"class":"positionInfo"})
totalprice=bsObj.findAll("div",{"class":"totalPrice"})
unitprice=bsObj.findAll("div",{"class":"unitPrice"})
house_loc=[] #房屋所在小区
house_type=[] #房屋户型
house_area=[] #房屋面积
house_direction=[] #房屋朝向
house_decorating=[] #房屋装修
house_lift=[] #有无电梯
house_floor=[] #房屋楼层
house_year=[] #建造年份
house_position=[] #房屋位置
t_price=[] #房屋总价
u_price=[] #房屋单价
for i_info,i_pinfo,i_tp,i_up in zip(info,position_info,totalprice,unitprice):
if len(i_info.get_text().split('/'))==6 and len(i_pinfo.get_text().split('/'))==3:
#分列houseinfo并依次获取房屋所在小区、户型、面积、朝向、装修、有无电梯各字段
house_loc.append(i_info.get_text().split('/')[0])
house_type.append(i_info.get_text().split('/')[1])
house_area.append(i_info.get_text().split('/')[2][:-2])
house_direction.append(i_info.get_text().split('/')[3].replace(' ',''))
house_decorating.append(i_info.get_text().split('/')[4])
house_lift.append(i_info.get_text().split('/')[5])
#分列positioninfo并依次获房屋楼层、建造年份、位置各字段
house_floor.append(i_pinfo.get_text().split('/')[0])
house_year.append(i_pinfo.get_text().split('/')[1][:5])
house_position.append(i_pinfo.get_text().split('/')[2])
#获取房屋总价和单价
t_price.append(i_tp.span.string)
u_price.append(re.sub('\D','',i_up.get_text()))
#将数据导入pandas之中生成数据表
house_data=pd.DataFrame()
house_data[u'城区']=[chengqu[cq]]*len(house_loc)
house_data[u'小区名称']=house_loc
house_data[u'房型']=house_type
house_data[u'面积']=house_area
house_data[u'朝向']=house_direction
house_data[u'装修']=house_decorating
house_data[u'有无电梯']=house_lift
house_data[u'楼层']=house_floor
house_data[u'建造年份']=house_year
house_data[u'位置']=house_position
house_data[u'总价']=t_price
house_data[u'单价']=u_price
#print (house_data)
#将数据存入到csv中,便于后续分析
house_data.to_csv('house_bj.csv', mode='a', header=False,ecoding='gb2312',index=None)