冒泡排序
什么是冒泡排序?
冒泡排序之所以被称为冒泡排序,在我看来冒泡才是关键。想必大家在炎炎夏日都喝过汽水,把汽水打开,汽水中的二氧化碳形成小气泡就咕噜噜的向上冒了起来,但是他们冒泡的速度却不一样,这是因为质量轻的气泡就先冒出水面,质量大的就后冒出水面。冒泡排序也是这样的,算法中的每一个元素都可以看作小气泡,根据自身数值的大小,小的在前大的在后向着瓶口移动。冒泡排序的过程就可以看作气泡向着瓶口移动的过程。
冒泡排序的原理(升序)
冒泡排序的原理:把数据元素进行两两比对,如果不满足小的在前大的灾后,就把这两个元素的交换,一直重复这个步骤,直到最后一个元素为止,这样循环一次就得到一个最大的最大的值。在进行并重复上面的操作,就可以得到一个升序的序列啦。
冒泡排序的过程
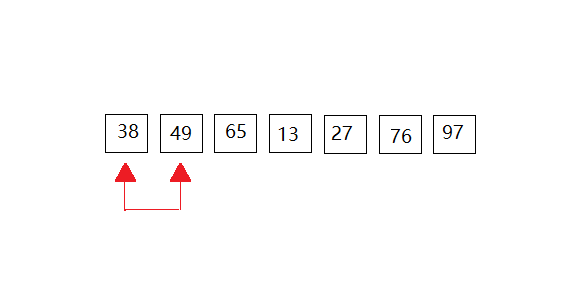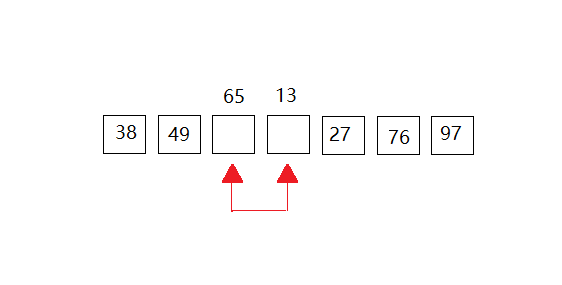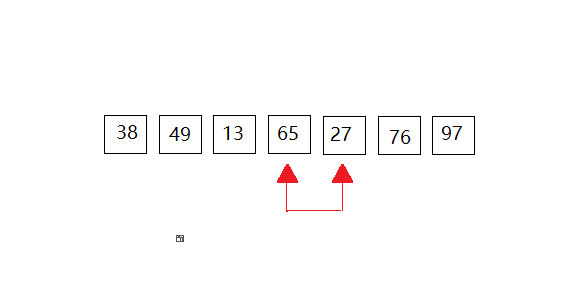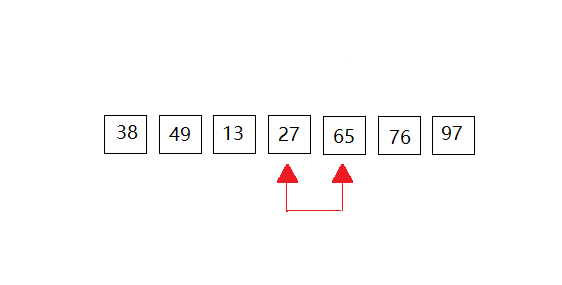
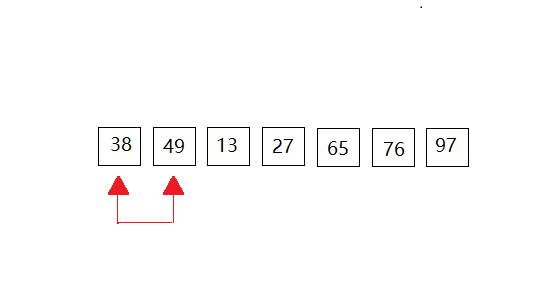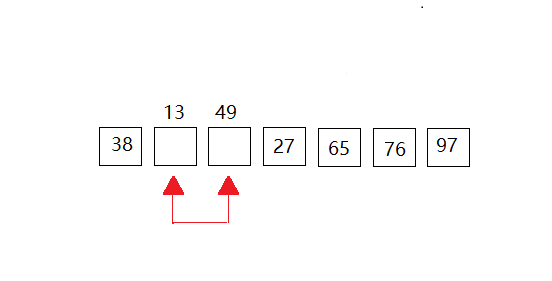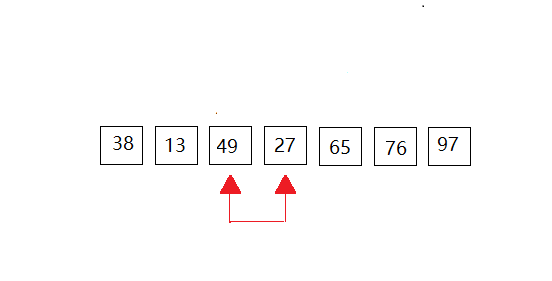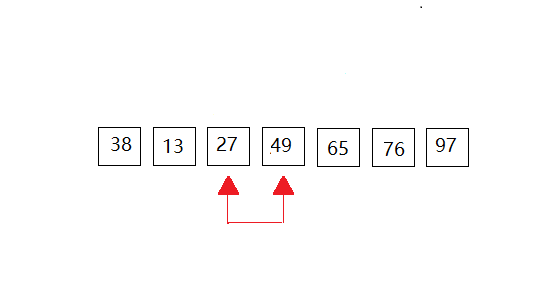
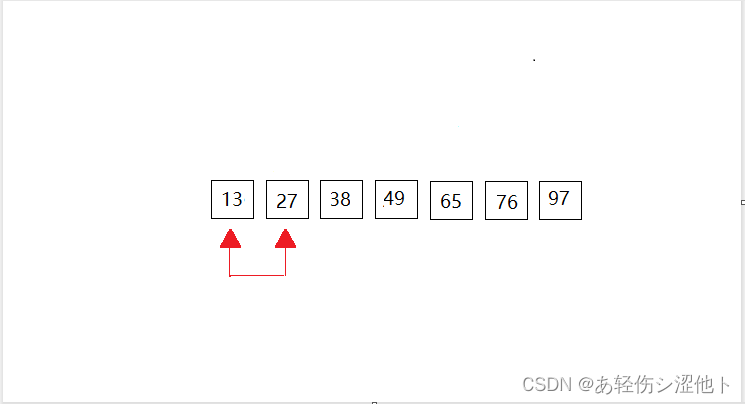
我们以一下的数据进行演示:{49,38,65,97,76,13,27},共有7个元素组成。动图全部放在一起,感觉大家有时不知道进行到了那里,所以我采用一次一次的来展示。(共有6次比较,n个数据元素,要扫描n-1次。)
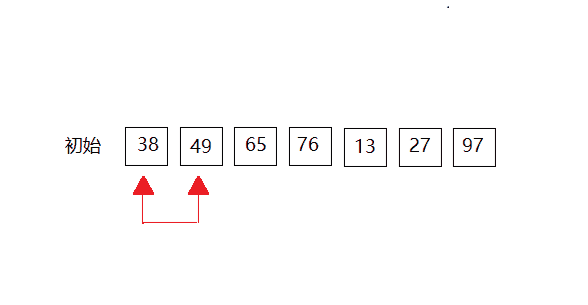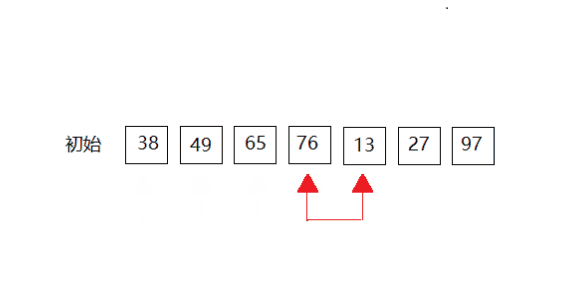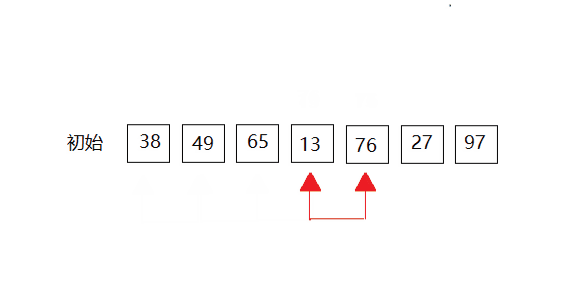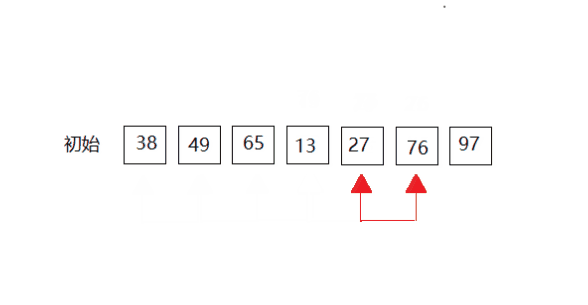
第一次:

第二次:数组末尾元素已经是最大的,就不需要比较。
第三次:
第四次:
第五次:
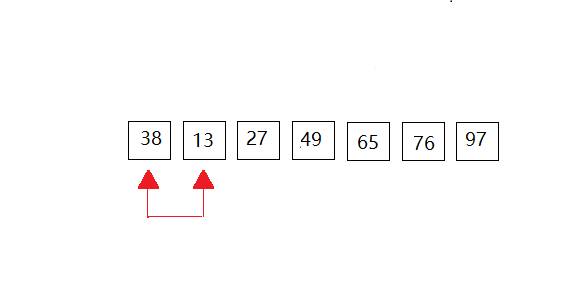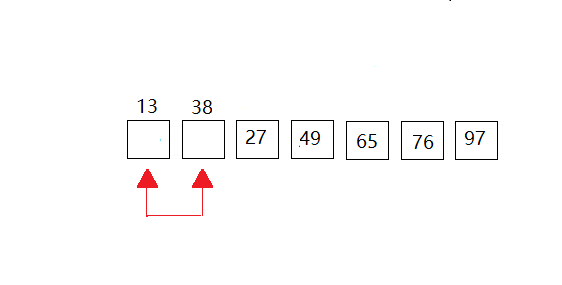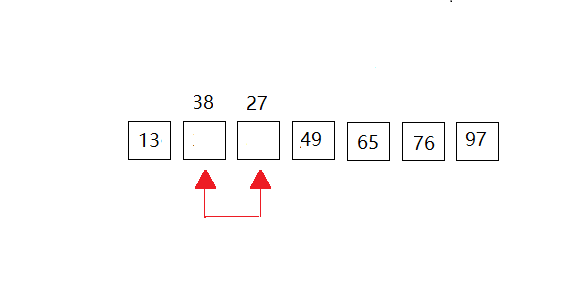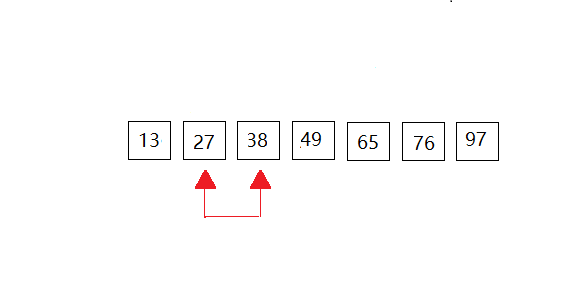
第六次:这里也就是第一个和第二个元素进行比较,但是第一个元素比第二个元素小,所以没有做成动图。
代码展示
这里 的代码就不用上面的数据,改为让用户自己输入。
#include <stdio.h>
#define size 7 //数组的大小,修改值就是改变数组的大小
int main()
{
int arr[size] = {
0 };
for (int i = 0; i < size; i++)//输入元素;
{
scanf("%d", &arr[i]);
}
for (int i = 0; i < size-1; i++)//控制的是层次循环。
{
for (int j = 0; j < size - i - 1; j++)//控制每一层元素,两两对比的次数。
{
if (arr[j] > arr[j + 1])//如果前面一个大于后面一个,交换位置
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
printf("通过冒泡排序后\n");
for (int i = 0; i < size; i++)//打印输出排序好的数据
{
printf("%3d", arr[i]);
}
return 0;
}
大家看完上面的这个代码,觉得它还可不可以改进呢?答案是肯定的,上面的程序还可以进行优化。大家不妨想想,排序到一定的时候,程序就已经完全有序了,但是程序还在继续前后两两比较,没有停下来。要怎么优化呢?其实我们可以通过设计一个标签:
第一步:让它在第一个for循环前面值等于一(int flag=1;)
第二步:在执行第一个for循环时判断flag的值等不等于1( n=0;n<m-1&&flag==1;m++)
第三步:在第一个for循环里面,在第二个for循环前面将flag的值修改为零(flag=0;),这表示前面的元素还没有完全有序,如果完全有序就不会进入第一个循环。
第四步:在第二个循环if里面将flag的值修改为一。表示还在进行交换,没有完全有序。
修改后的代码如下:
#include <stdio.h>
#define size 7 //数组的大小,修改值就是改变数组的大小
int main()
{
int arr[size] = {
0 };
int flag=1;
for (int i = 0; i < size; i++)//输入元素;
{
scanf("%d", &arr[i]);
}
for (int i = 0; i < size-1&&flag==1; i++)//控制的是层次循环。
{
flag=0;
for (int j = 0; j < size - i - 1; j++)//控制每一层元素,两两对比的次数。
{
if (arr[j] > arr[j + 1])//如果前面一个大于后面一个,交换位置
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
flag=1;
}
}
}
printf("通过冒泡排序后\n");
for (int i = 0; i < size; i++)//打印输出排序好的数据
{
printf("%3d", arr[i]);
}
return 0;
}
总结
1.第一次循坏的次数是总元素减一。
2.第二个循环里面循环的次数是待循环的元素减一,在减去第一个循环进行过的次数。
优点:每趟结束时,不仅能够挤出一个最大值到最后面位置,还能同时部分理顺其他元素;
快速排序
什么是快速排序?
快速排序是对冒泡排序的一种改进
基本思想
选取任意一个元素作为关键字,通过一趟排序将待排序元素分割为两个独立的部分,一部份小于关键字,一部分大于关键字。则继续对这两部分元素继续进行排序,以达到整个序列有序。
关键字:可以是第一个数,最后一个数,最中间的一个数,或者是任意一个数。
原则:将所有比关键字小的元素安置在它的位置之前,将所有大于关键字的元素安置在它的位置之后。关键字作为分界线。
具体做法:设两个指针left 和right,他们的初始值分别为left=0和right=总元素-1,首先从right所指位置向前搜索找到一个元素小于pivotkey的值,然后将right所指向的值和low的值交换。然后再从low所指的位置向后搜索,找到一个大于pivotkey的值,将low所指向的值和right进行交换,重复这两个步骤直至low=right为止,完成一次循环。
代码展示
#include <stdio.h>
#define size 6//自定义数组的大小
void swap(int arr[], int low, int high)//交换两个元素的值
{
int temp = arr[low];
arr[low] = arr[high];
arr[high] = temp;
}
void Qsort(int arr[], int low, int high)//low 起始位置 high 末尾位置
{
if (low < high)
{
int pivotloc = partition(arr, low, high);//计算基点
Qsort(arr, low, pivotloc - 1);//基点左边进行排序
Qsort(arr, pivotloc + 1, high);//基点右边进行排序
}
}
int partition(int arr[], int low, int high)
{
int pivotkey = arr[low];//基点等于第一个元素
while (low < high)
{
while (low < high && arr[high] >= pivotkey)//从后向前开始查找元素,满足while循环的都不满足,向前寻找。
{
--high;
}
//找到小于pivotkey的值,将他们进行交换
swap(arr, low, high);
while (low < high && arr[low] <= pivotkey)//从前往后查找,满足while循环的都不满足,向后寻找
{
++low;
}
//找到大于pivotkey的值,将他们进行交换。
swap(arr, low, high);
}
return low;//返回关键字的位置
}
int main()
{
//创建一个数组
int arr[size] = {
0 };
//输入数据
for (int i = 0; i < size; i++)
{
scanf_s("%d", &arr[i]);
}
Qsort(arr, 0, size - 1);
//打印排序好的数组
for (int j = 0; j < size; j++)
{
printf("%d ", arr[j]);
}
return 0;
}
采用的是两向中间交替式逼近法
每一趟对个子表的操作都相似,采用递归算法。
快速排序不适合于原本有序或基本有序的记录序列进行排序